Toda estructura de datos tiene sus propias características especiales, por ejemplo, se utiliza un BST cuando se requiere una búsqueda rápida de un elemento (en log(n)). Se utiliza un montón o una cola de prioridad cuando es necesario recuperar el elemento mínimo o máximo en un tiempo constante. De manera similar, una tabla hash se usa para obtener, agregar y eliminar un elemento en tiempo constante. Cualquiera debe tener claro el funcionamiento de una tabla hash antes de pasar al aspecto de implementación. Así que aquí hay una breve descripción del funcionamiento de una tabla hash, y también se debe tener en cuenta que usaremos la terminología Hash Map y Hash Table indistintamente, aunque en Java HashTables son seguros para subprocesos mientras que HashMaps no lo son.
El código que vamos a implementar está disponible en Link 1 y Link2
Pero se recomienda encarecidamente leer este blog por completo e intentar descifrar el meollo de la cuestión de la implementación de un mapa hash y luego tratar de escribir el código usted mismo.
Fondo:
Cada tabla hash almacena datos en forma de una combinación (clave, valor). Curiosamente, cada clave es única en una tabla hash, pero los valores pueden repetirse, lo que significa que los valores pueden ser los mismos para las diferentes claves presentes en ella. Ahora, mientras observamos en una array para obtener un valor, proporcionamos la posición/índice correspondiente al valor en esa array. En una tabla hash, en lugar de un índice, usamos una clave para obtener el valor correspondiente a esa clave. Ahora todo el proceso se describe a continuación.
Cada vez que se genera una clave. La clave se pasa a una función hash. Cada función hash tiene dos partes, un código hash y un compresor .
El código hash es un número entero (aleatorio o no aleatorio). En Java, cada objeto tiene su propio código hash. Usaremos el código hash generado por JVM en nuestra función hash y comprimiremos el código hash que modulamos (%) el código hash por el tamaño de la tabla hash. Entonces, el operador de módulo es un compresor en nuestra implementación.
Todo el proceso asegura que para cualquier clave obtengamos una posición entera dentro del tamaño de la Tabla Hash para insertar el valor correspondiente.
Entonces, el proceso es simple, el usuario proporciona un conjunto de pares (clave, valor) como entrada y, en función del valor generado por la función hash, se genera un índice donde se almacena el valor correspondiente a la clave en particular. Entonces, siempre que necesitemos obtener un valor correspondiente a una clave, eso es solo O (1).
Esta imagen deja de ser tan color de rosa y perfecta cuando se introduce el concepto de colisión de hash. Imagine que para diferentes valores clave se asigna el mismo bloque de la tabla hash ahora, ¿dónde almacenan previamente los valores correspondientes a alguna otra clave anterior? Ciertamente no podemos reemplazarlo. ¡Eso será desastroso! Para resolver este problema, utilizaremos la técnica de enstringmiento por separado. Tenga en cuenta que existen otras técnicas de direccionamiento abierto, como el hash doble y el sondeo lineal, cuya eficiencia es casi la misma que la del enstringmiento por separado, y puede obtener más información sobre ellas en Enlace 1 Enlace 2 Enlace3
Ahora lo que hacemos es hacer una lista enlazada correspondiente al cubo particular de la tabla hash, para acomodar todos los valores correspondientes a diferentes claves que se asignan al mismo cubo.
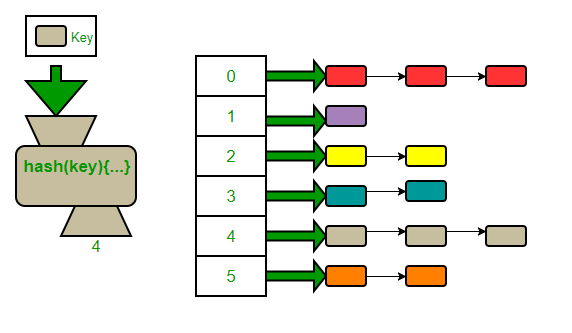
Ahora puede haber un escenario en el que todas las claves se asignen al mismo depósito, y tenemos una lista vinculada de tamaño n (tamaño de la tabla hash) de un solo depósito, con todos los demás depósitos vacíos y este es el peor de los casos. donde una tabla hash actúa como una lista enlazada y la búsqueda es O(n). ¿Asi que que hacemos?
Factor de carga:
Si n es el número total de cubos que decidimos llenar inicialmente, digamos 10 y digamos que 7 de ellos se llenaron ahora, por lo que el factor de carga es 7/10 = 0,7.
En nuestra implementación , cada vez que agregamos un par clave-valor a la tabla hash, verificamos el factor de carga, si es mayor que 0.7, duplicamos el tamaño de nuestra tabla hash.
Implementación
Tipo de datos de Node hash
Intentaremos hacer un mapa genérico sin poner restricciones en el tipo de datos de la clave y el valor. Además, cada Node hash necesita conocer el siguiente Node al que apunta en la lista vinculada, por lo que también se requiere un puntero siguiente.
Las funciones que planeamos mantener en nuestro mapa hash son
- get(K key) : devuelve el valor correspondiente a la clave si la clave está presente en HT ( H ast Table )
- getSize() : devuelve el tamaño del HT
- add() : agrega una nueva clave válida, un par de valores al HT, si ya está presente, actualiza el valor
- remove() : elimina la clave, el par de valores
- isEmpty() : devuelve verdadero si el tamaño es cero
ArrayList<HashNode<K, V>> bucket = new ArrayList<>();
Se implementa una función auxiliar para obtener el índice de la clave, para evitar la redundancia en otras funciones como obtener, agregar y eliminar. Esta función usa la función java incorporada para generar un código hash, y comprimimos el código hash por el tamaño del HT para que el índice esté dentro del rango del tamaño del HT
obtener()
La función get solo toma una clave como entrada y devuelve el valor correspondiente si la clave está presente en la tabla; de lo contrario, devuelve nulo. Los pasos son:
- Recuperar la clave de entrada para encontrar el índice en el HT
- Recorra la lista vinculada correspondiente al HT si encuentra el valor, luego devuélvalo, de lo contrario, si recorre completamente la lista sin devolverlo, significa que el valor no está presente en la tabla y no se puede recuperar, así que devuelva nulo
retirar()
- Obtener el índice correspondiente a la tecla de entrada usando la función de ayuda
- El recorrido de la lista enlazada es similar a get() pero lo que es especial aquí es que uno necesita eliminar la clave junto con encontrarla y surgen dos casos
- Si la clave a eliminar está presente al principio de la lista enlazada
- Si la llave que se va a quitar no está presente en la cabeza sino en otro lugar
agregar()
Ahora a la función más interesante y desafiante de toda esta implementación. Es interesante porque necesitamos aumentar dinámicamente el tamaño de nuestra lista cuando el factor de carga está por encima del valor que especificamos.
- Al igual que eliminar pasos hasta el recorrido y la adición, dos casos (suma en el punto principal o punto no principal) siguen siendo los mismos.
- Hacia el final, si el factor de carga es superior a 0,7
- Duplicamos el tamaño de la lista de arrays y luego recursivamente llamamos a la función de agregar en las claves existentes porque, en nuestro caso, el valor hash generado usa el tamaño de la array para comprimir el código hash JVM incorporado que usamos, por lo que necesitamos obtener nuevos índices para el existente llaves. Esto es muy importante de entender, por favor vuelva a leer este párrafo hasta que se dé cuenta de lo que está sucediendo en la función de agregar.
Java en su propia implementación de Hash Table usa Binary Search Tree si la lista vinculada correspondiente a un cubo en particular tiende a ser demasiado larga.
Java
// Java program to demonstrate implementation of our
// own hash table with chaining for collision detection
import java.util.ArrayList;
import java.util.Objects;
// A node of chains
class HashNode<K, V> {
K key;
V value;
final int hashCode;
// Reference to next node
HashNode<K, V> next;
// Constructor
public HashNode(K key, V value, int hashCode)
{
this.key = key;
this.value = value;
this.hashCode = hashCode;
}
}
// Class to represent entire hash table
class Map<K, V> {
// bucketArray is used to store array of chains
private ArrayList<HashNode<K, V> > bucketArray;
// Current capacity of array list
private int numBuckets;
// Current size of array list
private int size;
// Constructor (Initializes capacity, size and
// empty chains.
public Map()
{
bucketArray = new ArrayList<>();
numBuckets = 10;
size = 0;
// Create empty chains
for (int i = 0; i < numBuckets; i++)
bucketArray.add(null);
}
public int size() { return size; }
public boolean isEmpty() { return size() == 0; }
private final int hashCode (K key) {
return Objects.hashCode(key);
}
// This implements hash function to find index
// for a key
private int getBucketIndex(K key)
{
int hashCode = hashCode(key);
int index = hashCode % numBuckets;
// key.hashCode() could be negative.
index = index < 0 ? index * -1 : index;
return index;
}
// Method to remove a given key
public V remove(K key)
{
// Apply hash function to find index for given key
int bucketIndex = getBucketIndex(key);
int hashCode = hashCode(key);
// Get head of chain
HashNode<K, V> head = bucketArray.get(bucketIndex);
// Search for key in its chain
HashNode<K, V> prev = null;
while (head != null) {
// If Key found
if (head.key.equals(key) && hashCode == head.hashCode)
break;
// Else keep moving in chain
prev = head;
head = head.next;
}
// If key was not there
if (head == null)
return null;
// Reduce size
size--;
// Remove key
if (prev != null)
prev.next = head.next;
else
bucketArray.set(bucketIndex, head.next);
return head.value;
}
// Returns value for a key
public V get(K key)
{
// Find head of chain for given key
int bucketIndex = getBucketIndex(key);
int hashCode = hashCode(key);
HashNode<K, V> head = bucketArray.get(bucketIndex);
// Search key in chain
while (head != null) {
if (head.key.equals(key) && head.hashCode == hashCode)
return head.value;
head = head.next;
}
// If key not found
return null;
}
// Adds a key value pair to hash
public void add(K key, V value)
{
// Find head of chain for given key
int bucketIndex = getBucketIndex(key);
int hashCode = hashCode(key);
HashNode<K, V> head = bucketArray.get(bucketIndex);
// Check if key is already present
while (head != null) {
if (head.key.equals(key) && head.hashCode == hashCode) {
head.value = value;
return;
}
head = head.next;
}
// Insert key in chain
size++;
head = bucketArray.get(bucketIndex);
HashNode<K, V> newNode
= new HashNode<K, V>(key, value, hashCode);
newNode.next = head;
bucketArray.set(bucketIndex, newNode);
// If load factor goes beyond threshold, then
// double hash table size
if ((1.0 * size) / numBuckets >= 0.7) {
ArrayList<HashNode<K, V> > temp = bucketArray;
bucketArray = new ArrayList<>();
numBuckets = 2 * numBuckets;
size = 0;
for (int i = 0; i < numBuckets; i++)
bucketArray.add(null);
for (HashNode<K, V> headNode : temp) {
while (headNode != null) {
add(headNode.key, headNode.value);
headNode = headNode.next;
}
}
}
}
// Driver method to test Map class
public static void main(String[] args)
{
Map<String, Integer> map = new Map<>();
map.add("this", 1);
map.add("coder", 2);
map.add("this", 4);
map.add("hi", 5);
System.out.println(map.size());
System.out.println(map.remove("this"));
System.out.println(map.remove("this"));
System.out.println(map.size());
System.out.println(map.isEmpty());
}
}
3 4 null 2 false
Este artículo es una contribución de Ishaan Arora. Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo y enviarlo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA