La regresión logarítmica es un tipo de regresión que se utiliza para simular situaciones en las que el crecimiento o la decadencia se aceleran rápidamente inicialmente y luego se ralentizan con el tiempo. El siguiente gráfico, por ejemplo, muestra un ejemplo de decaimiento logarítmico:
La relación entre una variable predictora y una variable de respuesta podría describirse adecuadamente en este tipo de casos utilizando regresión logarítmica. La ecuación de un modelo de regresión logarítmica se ve así:

donde :
- y: La variable de respuesta
- x: Los coeficientes de regresión que caracterizan el vínculo entre x e y son las variables predictoras a, b.
Implementación paso a paso
Paso 1: Reúna los datos:
Para comenzar, generemos algunos datos ficticios para dos variables: x e y:
R
x=2:16 y=c(69, 60, 44, 38, 33, 28, 23, 20, 17, 15, 13, 12, 11, 10, 9.5)
Paso 2: Haz que los datos sean visuales:
Hagamos ahora un pequeño diagrama de dispersión para mostrar la relación entre x e y:
plot(x, y)
R
# Firstly we will fit the gfgModel gfgModel <- lm(y ~ log(x)) # Now Let's Print the summary summary(gfgModel)
Podemos observar en la figura que existe un patrón definido de decaimiento logarítmico entre las dos variables. El valor de la variable de respuesta, y, cae rápidamente inicialmente, luego disminuye gradualmente con el tiempo. Como resultado, usar una ecuación de regresión logarítmica para caracterizar la conexión entre las variables parece ser un enfoque decente.
Paso 3: Cree un modelo de regresión logarítmica:
A continuación, se utilizará la función lm() para ajustar un modelo de regresión logarítmica con el logaritmo natural de x como variable predictora e y como variable de respuesta.
Llamar:
lm(fórmula = y ~ log(x))
Derechos residuales de autor:
Mín. 1T Mediana 3T Máx.
-2.804 -1.972 -1.341 1.915 5.053
Coeficientes:
Estimación estándar Error valor t Pr(>|t|)
(Intersección) 87.591 2.462 35.58 2.43e-14 ***
log(x) -29.713 1.155 -25.72 1.56e-12 ***
—
signif. códigos: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
Error estándar residual: 2,69 en 13 grados de libertad
R-cuadrado múltiple: 0,9807, R-cuadrado ajustado: 0,9792
Estadístico F: 661,6 en 1 y 13 DF, valor p: 1,557e-12
El valor F general del modelo es 828,2 y el valor p que lo acompaña es excepcionalmente bajo (3,702e-13), lo que indica que el modelo en su conjunto es beneficioso. Podemos ver a partir de los coeficientes en la tabla de salida que la ecuación de regresión logarítmica ajustada es:
y = 63.1686 – 20.1987 ln (x)
Con base en el valor de la variable de predicción, x, podemos usar esta ecuación para predecir la variable de respuesta, y. Por ejemplo, si x es igual a 12, podemos anticipar que y es igual a 12,87:
y = 63.1686-20.1987 * ln(12) = 12.87
Nota: puede usar esta calculadora de regresión logarítmica en línea para calcular la ecuación de regresión logarítmica para un predictor y una variable de respuesta determinados.
Paso 4: cree una representación visual del modelo de regresión logarítmica:
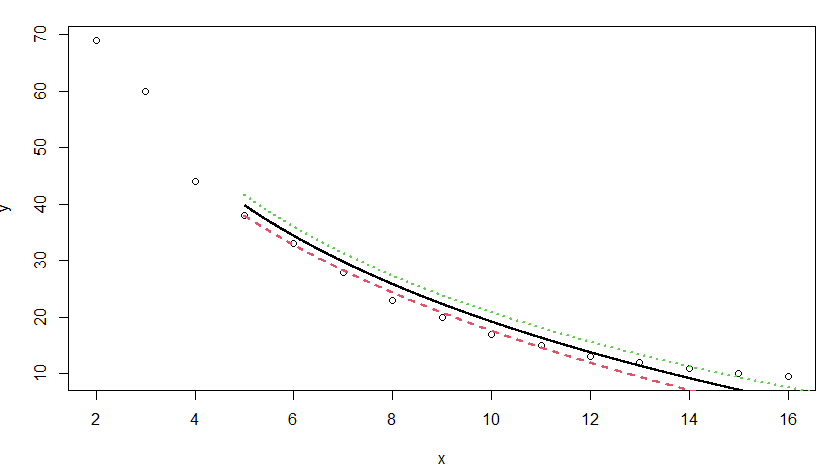
Finalmente, podemos graficar los datos para ver qué tan bien el modelo de regresión logarítmica coincide con los datos:
R
# We will plot the x and y axis plot(x, y) # now to define the line, we do x=seq(from=5,to=40,length.out=5000) # use the gfgModel to predict the # y-values based on the x-values y=predict(gfgModel,newdata=list(x=seq( from=5,to=40,length.out=5000)), interval="confidence") # Here is the line matlines(x,y, lwd=2)
Producción:
Publicación traducida automáticamente
Artículo escrito por therebootedcoder y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA