En este artículo, vemos la diferencia entre INNER JOIN y LEFT SEMI JOIN.
Unir internamente
Una unión interna requiere que dos columnas de conjuntos de datos sean iguales para obtener los valores de datos de fila comunes o los datos de la tabla de datos. En palabras simples, y devuelve un marco de datos o valores con solo aquellas filas en el marco de datos que tienen características comunes y el comportamiento deseado por el usuario. Esto es similar a la intersección de dos conjuntos en matemáticas. En resumen, podemos decir que Inner Join en el Id. de la columna devolverá columnas tanto de las tablas como solo de los registros coincidentes:
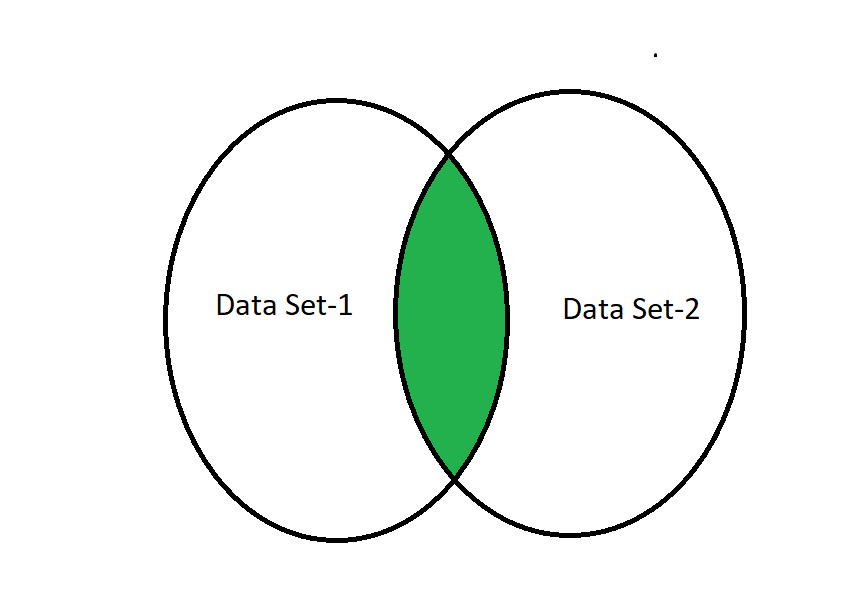
Unir internamente
Ejemplo:
Suponga que dos empresas están realizando un torneo de cricket entre empresas y los empleados que han participado dieron sus nombres en la tabla del conjunto de datos. Ahora en la tabla, tenemos dos o más Id similares . Ahora tenemos dos conjuntos de tablas de datos. Y queremos los datos de todos los empleados con el mismo ID en dos empresas diferentes para que podamos diferenciar fácilmente el mismo ID en diferentes empresas. En tal escenario, utilizaremos el concepto de unión interna para obtener todos los detalles de dichos empleados.
Python3
# importing pandas as pds
import pandas as pds
# Creating dataframe for the data_set first
data_Set1 = pds.DataFrame()
# Creating data list for the table 1
# here Id 101 and 102 will be same like
# in data set 2
schema = {'Id': [101, 102, 106, 112],
'DATA 1': ['Abhilash', 'Raman', 'Pratap', 'James']}
data_Set1 = pds.DataFrame(schema)
print("Data Set-1 \n", data_Set1, "\n")
# Creating dataframe data_set second
data_Set2 = pds.DataFrame()
# Creating data list for the table 2
# here Id 101 and 102 will be same like
# in data set 1
schema = {'Id': [101, 102, 109, 208],
'DATA 2': ['Abhirav', 'Abhigyan', 'John', 'Peter']}
data_Set2 = pds.DataFrame(schema)
print("Data Set-2 \n", data_Set2, "\n")
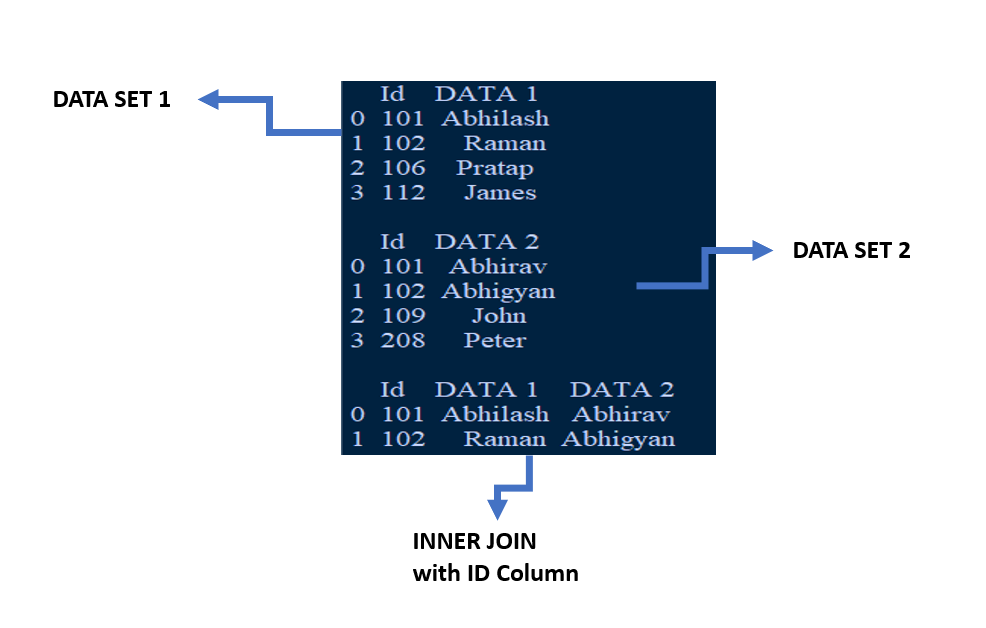
# inner join in python
inner_join = pds.merge(data_Set1, data_Set2, on='Id', how='inner')
# display dataframe
pds.DataFrame(inner_join)
Producción:
Semi-unión izquierda
Una semiunión izquierda requiere que dos columnas del conjunto de datos sean iguales para obtener los datos y devuelve todos los datos o valores de las columnas del conjunto de datos de la izquierda, e ignora todos los valores de datos de las columnas del conjunto de datos de la derecha. En palabras simples, podemos decir que Left Semi Join en la columna Id. devolverá columnas solo de la tabla de la izquierda y registros coincidentes solo de la tabla de la izquierda.
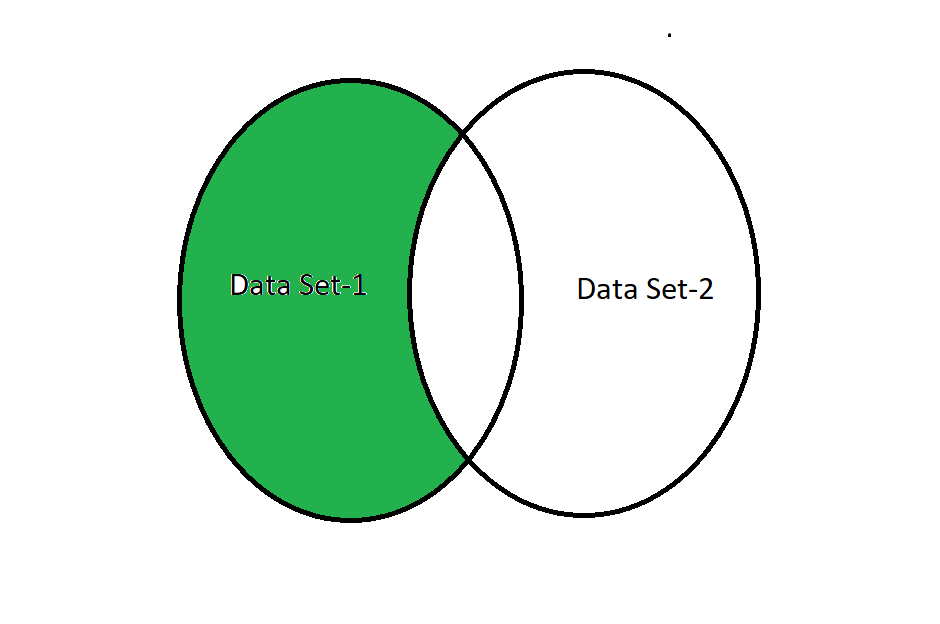
Semi-unión izquierda
Ejemplo:
Suponga que dos empresas están realizando un torneo de Cricket entre empresas y los empleados que han participado dieron sus nombres en la tabla del conjunto de datos. Ahora en la tabla, tenemos dos o más Id similares. Ahora tenemos dos conjuntos de tablas de datos. Las empresas con los datos del lado izquierdo quieren dar prioridad al empleado de su empresa para que pueda elegir quién jugará primero.
Python3
# importing pandas as pds
import pandas as pds
# Creating dataframe for the data_set first
data_Set1 = pds.DataFrame()
# Creating data list for the table 1
schema = {'Id': [101, 102, 106, 112],
'DATA 1': ['Abhilash', 'Raman', 'Pratap', 'James']}
data_Set1= pds.DataFrame(schema)
print(data_Set1,"\n")
# Creating dataframe data_set second
data_Set2 = pds.DataFrame()
# Creating data list for the table 2
schema2 = {'Id': [101, 102, 109, 208],
'DATA 2': ['Abhirav', 'Abhigyan', 'John', 'Peter']}
data_Set2= pds.DataFrame(schema2)
print(data_Set2,"\n")
# setting the base for the left semi-join in python
semi=data_Set1.merge(data_Set2,on='Id')
print(semi,"\n")
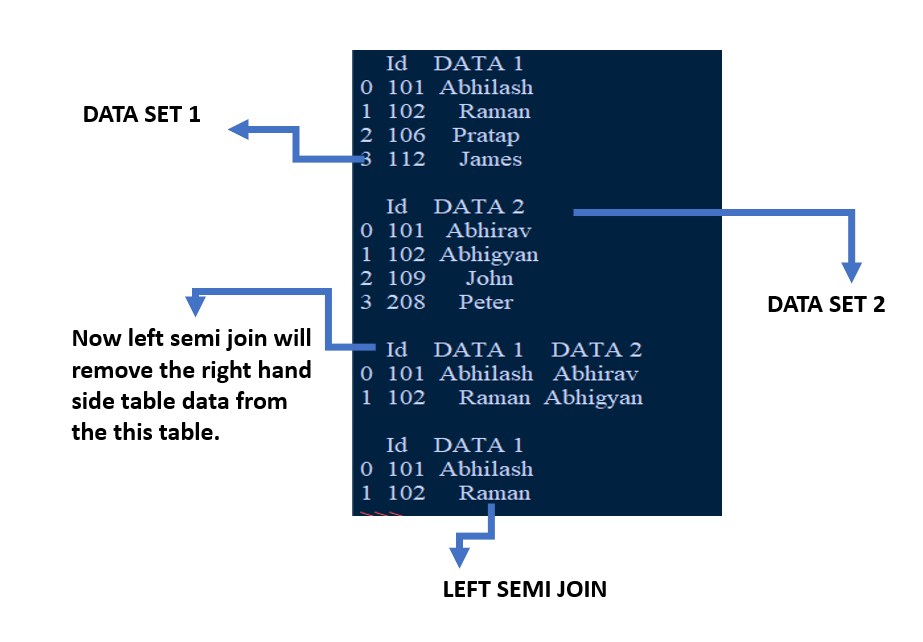
data_Set1['Id'].isin(data_Set2['Id'])
semi=data_Set1.merge(data_Set2,on='Id')
# our left semi join
new_semi=data_Set1[data_Set1['Id'].isin(semi['Id'])]
pds.DataFrame(new_semi)
Producción:
Publicación traducida automáticamente
Artículo escrito por abhilashgaurav003 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA