En este artículo, discutiremos cómo seleccionar aleatoriamente columnas del marco de datos de Pandas.
De acuerdo con nuestros requisitos, podemos seleccionar columnas al azar de un método de base de datos de pandas donde el método pandas df.sample() nos ayuda a seleccionar filas y columnas al azar.
Sintaxis del método pandas sample():
Devuelve una selección aleatoria de elementos del eje de un objeto. Para la repetibilidad, puede usar el parámetro random_state.
DataFrame.sample(n=Ninguno, frac=Ninguno, replace=False, weights=Ninguno, random_state=Ninguno, axis=Ninguno)
Parámetros:
- n: valor int, Número de filas aleatorias a generar.
- frac: valor flotante, devuelve (valor flotante * longitud de los valores del marco de datos). frac no se puede usar con n.
- replace: valor booleano, devolver muestra con reemplazo si es True.
- random_state: valor int o numpy.random.RandomState, opcional. si se establece en un número entero en particular, devolverá las mismas filas que la muestra en cada iteración.
- eje: 0 o ‘fila’ para Filas y 1 o ‘columna’ para Columnas.
Método 1: seleccione una sola columna al azar
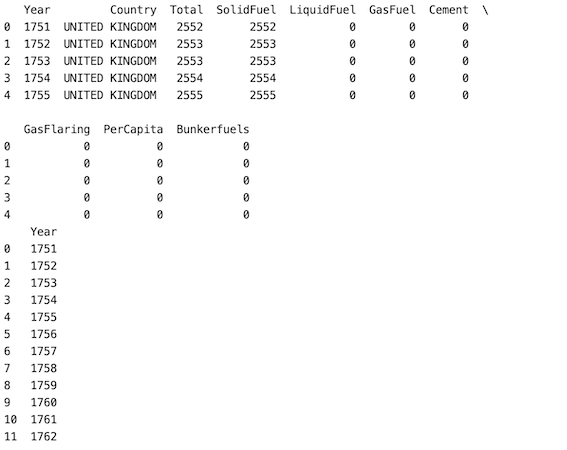
En este enfoque, en primer lugar, se lee el paquete Pandas con el que se importa el archivo CSV dado utilizando el método pd.read_csv() para leer el conjunto de datos. El método df.sample() se usa para seleccionar filas y columnas aleatoriamente. axis =’ column’ dice que estamos seleccionando columnas. cuando no se especifica «n», el método devuelve una columna aleatoria de forma predeterminada.
Para descargar el archivo CSV haga clic aquí
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
# randomly selecting columns
df = df.sample(axis='columns')
print(df)
Producción:
Método 2: Seleccione un número de columnas en un estado aleatorio
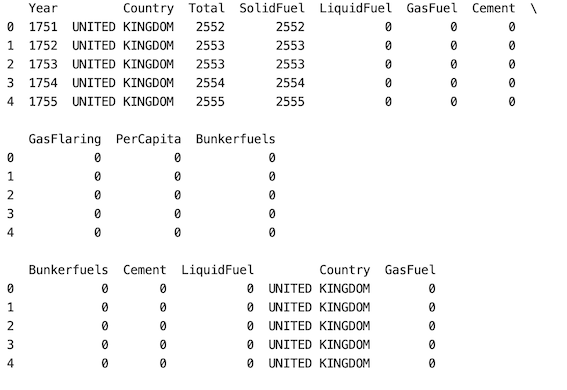
En este enfoque, si el usuario quiere seleccionar un cierto número de columnas más de 1, usamos el parámetro ‘n’ para este propósito. En el siguiente ejemplo, damos n como 5. Seleccionamos al azar 5 columnas de la base de datos.
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns')
print(df.head())
Producción:
Método 3: permitir una selección aleatoria de la misma columna más de una vez (configurando replace=True)
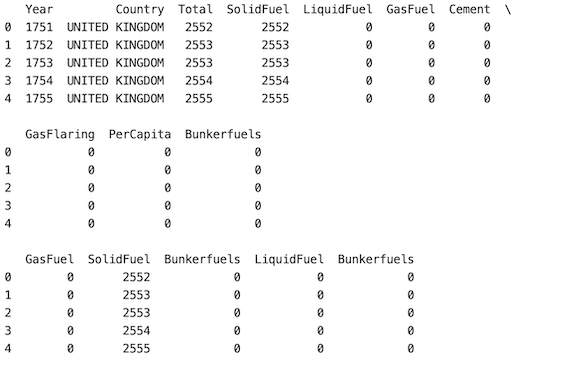
Aquí, en este enfoque, si el usuario desea seleccionar una columna más de una vez, o si se necesita repetibilidad en nuestra selección, debemos establecer el parámetro de reemplazo en ‘Verdadero’ en el método df.sample(). La columna ‘Bunkerfields’ se repite dos veces.
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(n=5, axis='columns',replace='True')
print(df.head())
Producción:
Método 4: seleccione una parte del número total de columnas al azar:
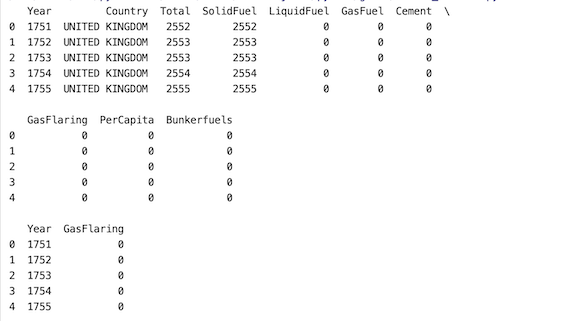
Aquí, en este enfoque, si el usuario desea seleccionar una parte del conjunto de datos, se debe usar el parámetro frac. En el siguiente ejemplo, nuestro conjunto de datos tiene 10 columnas. 0,25 de 10 es 2,5, se redondea aún más a 2. Se devuelven las columnas Año y Quema de gas.
Python3
# import packages
import pandas as pd
# reading csv file
df =pd.read_csv('fossilfuels.csv')
pd.set_option('display.max_columns', None)
print(df.head())
print()
# randomly selecting columns
df = df.sample(frac=0.25, axis='columns')
print(df.head())
Producción:
Publicación traducida automáticamente
Artículo escrito por lizzywizzy366 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA