RED se encuentra entre los primeros algoritmos de Active Queue Management (AQM). RED fue propuesto en 1993 por Sally Floyd. RED recibe tres nombres diferentes; también conocido como Descarte temprano aleatorio o Caída temprana aleatoria y Detección temprana aleatoria (por lo que hay 3 posibles formas completas de RED). El objetivo principal de RED es:
- Evite la congestión: la gestión pasiva de colas sufre este problema. AQM detecta la congestión de antemano y la evita.
- Evite el problema de la sincronización global: la gestión pasiva de colas sufre este problema. AQM evita este problema.
- Evite el problema del bloqueo: Los flujos de corta duración sufren el problema del bloqueo cuando los flujos de larga duración ocupan los búfer de los enrutadores todo el tiempo. AQM resuelve este problema, ahora los flujos de corta duración pueden obtener espacio en el búfer.
- Maximice la función ‘Power’, que es la relación entre el rendimiento y el retraso: AQM maneja la cola del búfer correctamente, por lo tanto, no habrá pérdida de paquetes, como resultado, no habrá retransmisión de paquetes. El flujo será fluido y el retardo será mínimo.
Nota: RED se propuso en 1993 y el término ‘Bufferbloat’ se acuñó en 2011. Aún así, AQM resuelve el problema de bufferbloat. Sin embargo, RED se considera adecuado para resolver el problema de Bufferbloat porque controla la «longitud de la cola» dentro de los umbrales especificados. Nunca permite que el búfer se llene por completo. Entonces, naturalmente, está previniendo el problema de la hinchazón del búfer. Se ha trabajado mucho en este algoritmo al igual que TCP. Se han propuesto varias variantes de RED en la literatura: Gentle RED, Nonlinear RED (NLRED), Adaptive RED (ARED) y muchas otras.
Funcionamiento del algoritmo RED:
RED opera durante el tiempo de ‘en cola’. Funciona en el puerto de salida durante el tiempo de puesta en cola, no lo confunda con el ‘puerto de entrada’ en la arquitectura del enrutador. ¡RED se ejecuta en el ‘puerto de salida’, pero durante el tiempo de ‘poner en cola’! RED opera ‘a la llegada de cada paquete’. Por lo tanto, no hay un intervalo de tiempo periódico en el que se invoque RED. Si los paquetes llegan a una velocidad más baja, se invoca RED a una velocidad más baja. Si los paquetes no llegan, no se invoca el algoritmo RED. RED decide si el paquete entrante debe ponerse en cola o descartarse. Cuando llega un nuevo paquete, RED toma una decisión; si este paquete debe ponerse en cola o descartarse? Toma esta decisión incluso si hay espacio en la cola. Toma esta decisión porque si poner en cola el paquete aumenta la demora general o hace que la cola se llene, entonces se producirá la congestión.
El algoritmo RED contiene los siguientes componentes:
- Cálculo de la longitud media de la cola.
- El cálculo de la probabilidad de descarte, ya sea que el paquete se ponga en cola o se descarte, depende de esta probabilidad.
- Lógica de toma de decisiones (ayuda a decidir si el paquete entrante debe ponerse en cola o descartarse).
Cálculo de la longitud promedio de la cola:
A la llegada de cada paquete, RED calcula la longitud promedio de la cola usando la ecuación. (1). Este modelo matemático se conoce como ‘Promedio móvil ponderado exponencial’ o EWMA.
=> newavg = (1 – w q ) x oldavg + w q x current_queue_len Eq. (1)
=> donde, newavg = nueva longitud de cola promedio calculada en esta muestra
=> oldavg = longitud de cola promedio anterior obtenida durante la muestra anterior
=> current_queue_len = longitud de cola ‘instantánea’ en el enrutador
=> w q = peso asociado con el ‘current_queue_len’. Valor predeterminado: 0,002
Más tarde Sally Floyd, la autora de RED hizo adaptativa la variable wq. Ya no era el valor codificado. Pero aquí, dado que estamos discutiendo el algoritmo RED original, su valor se toma como 0.002.
Cálculo de la probabilidad de caída
Una vez que se calcula el ‘nuevo promedio’, RED usa la siguiente lógica para calcular la probabilidad de caída (P d ), donde min th representa el umbral mínimo para la ‘longitud promedio de la cola’ y max th representa el umbral máximo para la ‘longitud promedio de la cola’. min th y max th están en el contexto de la longitud de cola promedio, no la longitud de cola instantánea. Esta es una conclusión importante antes de profundizar más.
=> if (newavg ≤ min th ) // el valor predeterminado de minth en el periódico es de 5 paquetes
=> poner en cola el paquete entrante // significa Pd= 0
=> else if (newavg > max th ) // el valor predeterminado de maxth en el papel es 15 paquetes
=> soltar el paquete entrante // significa Pd= 1
=> else Calcule Pd como se muestra en la ecuación. (2)
=> Pd= max p x [(newavg – min th ) ÷ (max th – min th )] Eq. (2)
=> La pendiente de la función lineal dependerá de este valor máximo de p .
=> donde, max p = máxima probabilidad de caída. Predeterminado: 0,5 (anteriormente, era 0,02)
Cuando la nueva longitud promedio de la cola es inferior al valor de umbral mínimo del tamaño de la cola, que es 5, la probabilidad de caída del paquete es 0. 0 significa que el paquete no se descartará, pero se pondrá en cola. Cuando la nueva longitud promedio de la cola es mayor que el valor de umbral máximo del tamaño de la cola, que es 15, la probabilidad de caída del paquete es 1. 1 significa que el paquete se descartará. Ahora viene el caso intermedio, cuando la nueva longitud promedio de la cola está entre el valor de umbral mínimo y máximo, entonces la probabilidad de caída se calculará utilizando una fórmula, dada anteriormente en la ecuación 2.
¿Qué hacemos con P d ? , esto es lo que haremos en el siguiente paso.
Lógica de toma de decisiones
Una vez que se calcula el ‘Pd’, RED usa la siguiente lógica para decidir si el paquete entrante debe ponerse en cola o descartarse:
=> si (Pd≤ R) poner en cola el paquete entrante
=> de lo contrario, suelte el paquete entrante
=> donde, R = número aleatorio distribuido uniformemente generado entre [0, 1]
Nota: Es importante que se utilice un generador de números aleatorios bien conocido para generar R. Si la implementación del generador de números aleatorios no es correcta, el rendimiento de RED podría verse afectado.
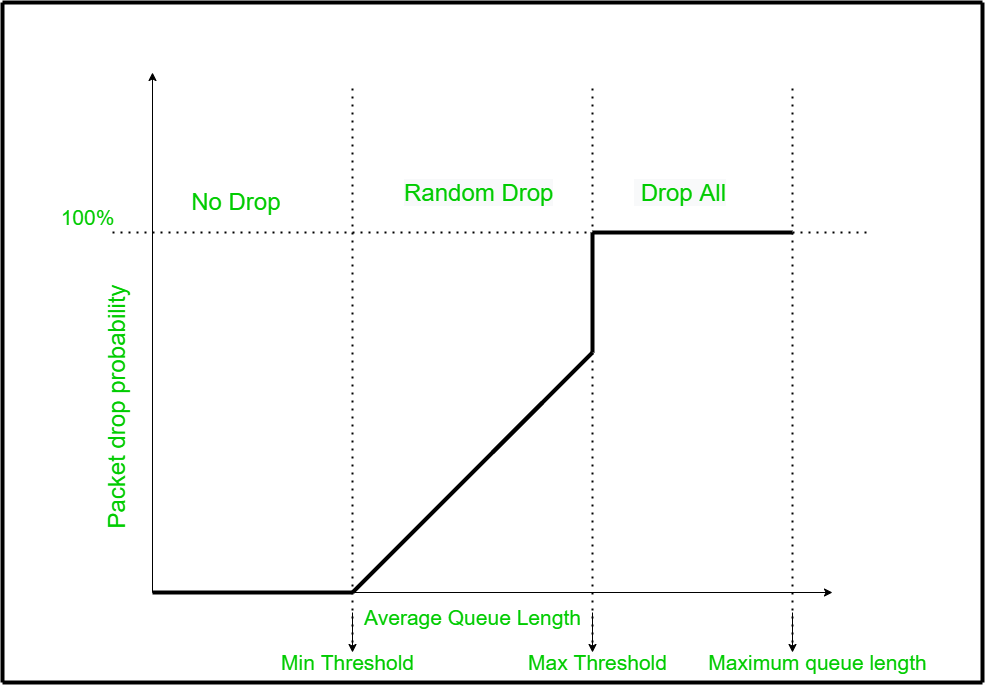
La parte izquierda es la región «No soltar». Si la longitud promedio de la cola es inferior al valor de umbral mínimo, el paquete se pondrá en cola. La parte derecha es la región «soltar todo». Si la longitud promedio de la cola es mayor que el valor de umbral máximo, el paquete se descartará. Si la longitud promedio de la cola está entre los valores de umbral mínimo y máximo, se calculará la probabilidad de caída de ese paquete. Con base en ese valor, se tomará la decisión final sobre poner en cola o descartar.
¿Es P d suficiente para permitir un patrón de caída aleatoria uniforme?
Cuando el tamaño promedio de la cola se vuelve constante, el número de paquetes que llegan ‘entre’ los paquetes descartados se convierte en una variable aleatoria geométrica con P d . Implica que las caídas de paquetes no se distribuyen uniformemente porque a veces llegan más paquetes y, a veces, llegan menos paquetes entre dos caídas de paquetes. Por lo tanto, se proporciona una nueva ecuación para calcular la probabilidad de caída (Pa ).
=> P a = P d ÷ (1 – contar x P d ) Eq. (3) donde, cuenta = número de paquetes en cola desde la última caída
¿Qué sucede con el ‘tamaño promedio de la cola’ cuando no llegan paquetes al enrutador?
Dado que RED se invoca solo cuando llegan los paquetes, existe la posibilidad de que el valor de ‘tamaño promedio de la cola’ indique incorrectamente una gran congestión incluso cuando la cola está realmente ‘vacía’. Si esto sucede, es posible que se descarte un paquete entrante incluso si la cola está totalmente vacía. El problema básico es que el valor de ‘tamaño promedio de cola’ no ‘decae’ cuando la cola está inactiva.
=> Cuando un primer paquete llega a una cola vacía, el ‘newavg’ se calcula como se muestra en la ecuación. (4)
=> newavg = (1 – w q ) m x oldavg Eq. (4) donde, m = el número de paquetes que ‘podrían’ tener
=> sido transmitido por el enrutador si no estaba inactivo. m se calcula como se muestra en la ecuación. (5)
=> m = (idle_stop_time – idle_start_time) ÷ (tiempo medio de transmisión de un paquete) Eq. (5)
=> donde, tiempo promedio de transmisión de un paquete = tamaño medio del paquete ÷ ancho de banda
=> Nota: ¡los paquetes pueden ser de diferentes tamaños en la red!
Pseudocódigo para Algoritmo RED:
A la llegada de cada paquete:
Paso 1: si (la cola está vacía) newavg = (1 – w q ) m x oldavg.
else newavg = (1 – w q ) x oldavg + w q x current_queue_len.
Paso 2: si (newavg ≤ mes) ponga en cola el paquete entrante.
si no (newavg > max th ).
soltar el paquete entrante.
si no Calcular P d y P a.
Paso 3: si (P a ≤ R) poner en cola el paquete entrante.
de lo contrario, suelte el paquete entrante.
Mandos configurables en ROJO:
- w q
- min th
- máx .
- p máx .
- tamaño medio de paquete
Publicación traducida automáticamente
Artículo escrito por pintusaini y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA