El análisis de vivacidad consiste en una técnica específica que se implementa para optimizar la asignación de espacio de registro para un fragmento de código determinado y facilitar el procedimiento de eliminación de código inactivo. Como cualquier máquina tiene un número limitado de registros para contener una variable o datos que se utilizan o manipulan, existe la necesidad de equilibrar la asignación eficiente de memoria para reducir costos y también permitir que la máquina maneje código complejo y una cantidad considerable de datos. de variables al mismo tiempo. El procedimiento se lleva a cabo durante la compilación de un código de entrada por un compilador mismo.
Variable Viva: Una variable está viva en cualquier instante de tiempo, durante el proceso de compilación de un programa si su valor está siendo usado para procesar un cómputo como la evaluación de una operación aritmética en ese instante o tiene un valor que será usado en el futuro sin que la variable sea redefinida en ningún paso intermedio.
Rango en vivo: el rango en vivo de una variable se define como la parte del código para el cual una variable estaba en vivo. El rango en vivo de una variable puede ser continuo o estar distribuido en diferentes partes del código. Esto implica que una variable puede estar activa en un instante y muerta en el siguiente y puede volver a estar activa durante una determinada porción.
El algoritmo de vivacidad se utiliza para evaluar la vivacidad de cada variable en cada paso. Si una o más variables están activas durante la ejecución de una instrucción, el algoritmo agrega la evaluación al resultado final y repite el mismo procedimiento para la siguiente instrucción. La salida del algoritmo se usa además para analizar el rango de variables en vivo y si dos variables no están en vivo simultáneamente en cualquier instante de tiempo, comparten un registro común. Por lo tanto, como resultado, el espacio disponible se utiliza de manera efectiva, lo cual es la motivación detrás del algoritmo.
El concepto básico se deriva del hecho de que para unas pocas variables temporales, las variables con rangos vivos disjuntos se pueden poner en un registro específico, según sea necesario. Para garantizar una asignación adecuada de un registro a múltiples variables, de acuerdo con el código, se introduce el concepto de Algoritmo de vivacidad y Variable viva .
Terminologías utilizadas:
Algunas terminologías clave son las que se analizan a continuación:
1. Gráfico de flujo de control: un gráfico de flujo de control se describe como una forma gráfica de representación para el control de flujo de un programa a través de un gráfico dirigido, durante el proceso de análisis. Cada Node de un gráfico de flujo de control (CFG) representa una declaración única o un conjunto de declaraciones y cada borde dirigido del gráfico representa el flujo de control para el código dado.
Tenga en cuenta que, para un gráfico de flujo de control:
Los bordes salientes apuntan a un Node sucesor.
succ[n] : It is the set of all successors of node 'n'.
Los bordes entrantes surgen de un Node predecesor.
pred[n] : It is the set of all predecessors of node 'n'.
2. Análisis de flujo de datos: un procedimiento para extraer información clave y aprender el comportamiento dinámico de un programa determinado mediante la revisión y el análisis del código estático únicamente.
3. Bloque Básico: El procedimiento para recolectar la información de vivacidad es una forma de análisis de flujo de datos, operando sobre el Gráfico de Flujo de Control donde cada enunciado, en general, es considerado como un Bloque Básico diferente .
Es importante señalar que la vivacidad es una propiedad de una variable que fluye a través y alrededor de los bordes dirigidos del gráfico de flujo de control.
4. Defina una variable: una expresión de asignación define una variable, digamos v , donde se asigna un valor a v .
- def(v): Se define como el conjunto de todos los Nodes en el gráfico de flujo de control donde se define ‘v’.
- def[n]: Se define como el conjunto de variables definidas por ‘n’, donde ‘n’ es un Node en el gráfico de flujo de control y ‘v’ es una variable.
5. Usar una variable: se dice que cada aparición de v en cualquier número de expresiones es un uso del valor de v que se usa para cada declaración que usa el valor de ‘v’.
- use(v): Se define como el conjunto de todos los Nodes en el grafo de flujo de control que usan ‘v’, y
- use[n]: Es el conjunto de variables utilizadas en ‘n’, donde ‘n’ es un Node en el gráfico de flujo de control y ‘v’ es una variable.
Tenga en cuenta que use[n] y def[n] para un Node determinado, ambos son independientes del flujo de control y, por lo tanto, son constantes para cada Node, independientemente de las iteraciones.
6. En vivo: una variable ‘v’ está en vivo en el borde ‘e’ si existe una ruta dirigida desde el borde ‘e’ al uso de ‘v’ que no pasa por ninguna definición (v).
7. Live-In: Una variable ‘v’ está en vivo en el Node ‘n’ si la variable está en vivo en cualquiera de los bordes de entrada de n.
8. Live-Out: una variable ‘v’ está activa en un Node ‘n’ si está activa en cualquiera de los extremos de n.
Para evaluar Live-In y Live-Out, definimos
-> in[n]: As set of all the variables live-in at 'n' and -> out[n]: As set of all the variables live-out at 'n', where both in[n] and out[n] are initialised to NULL.
Nota:
1. Si se usa una variable en una declaración de programa que existe en un Node, entonces la variable está activa en ese Node. La definición se expresa como una expresión a continuación:
v ∈ use[n] ⇒ v live-in at n
2. En general, asumimos que todas las variables han sido inicializadas previamente. Además, si una variable está activa en un Node determinado, entonces está activa en todos los Nodes predecesores que se dirigen al Node en un CFG.
v live-in at n ⇒ v live-out at all m ∈ pred[n]
3. Una variable ‘v’ está viva en un punto dado de un programa expresado como un Node como ‘n’ si existe una ruta dirigida desde ‘n’ al uso de ‘v’ y la ruta no contiene ninguna definición de ‘v’.
v live-out at n, v ∉ def[n] ⇒ v live-in at n
Algoritmo de vivacidad:
El algoritmo de vivacidad debe ejecutar la funcionalidad requerida y una descripción general de los pasos incluidos en el diseño del algoritmo son los siguientes:
- El primer paso es identificar qué variables están definidas y cuáles son leídas (usadas) por instrucción o sentencia de programa analizando cada Node, paso a paso, en un CFG. Además, inicialice el valor de IN y OUT en NULL. Tenga en cuenta que el paso 1 se ejecuta solo una vez.
- Mantenga un registro de información global que tiene como objetivo especificar cómo las instrucciones transmiten valores en vivo alrededor del programa y calculan los conjuntos IN y OUT a partir de los conjuntos de uso y definición usando las expresiones.
- Ahora, itere (2) hasta que los conjuntos IN y OUT se vuelvan constantes para iteraciones sucesivas. ¡Recuerde que los conjuntos def y use son constantes y, por lo tanto, independientes de la ruta!
El algoritmo de vivacidad es el siguiente:
N : Set of nodes of CFG;
for each n ∈ N do
in[n] ← φ;
out[n] ← φ;
end
repeat
for each n ∈ Nodes do
// First save the current value for IN and OUT for comparison later.
in'[n] ← in[n];
out'[n] ← out[n];
// For OUT, find out the union of previous variables
in the IN set for each succeeding node of n.
out[n] ← ∪s∈succ[n]in[s] ; // Compute OUT for a node.
in[n] ← use[n]∪(out[n]−def [n]); // Compute IN for a node.
end
// Iterate, until IN and OUT set are constants for last two consecutive iterations.
until ∀n,in'[n] = in[n] ∧ out' [n] = out[n];
Análisis del algoritmo de vivacidad mediante un ejemplo:
Problema: Se dice que una variable x está viva en una declaración Si en un programa si las siguientes tres condiciones se cumplen simultáneamente:
- Existe un enunciado Sj que usa x
- Hay un camino de Si a Sj en el diagrama de flujo correspondiente al programa
- El camino no tiene asignación intermedia a x, incluso en Si y Sj
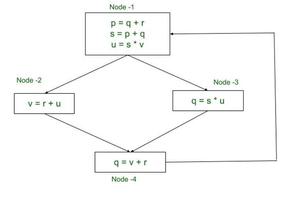
Gráfico de flujo de control (ejemplo de análisis de vivacidad)
Solución:
| NODO(n) | usar[n] | definición | Valor inicial | 1ra Iteración _ | 2ª iteración _ | 3ra iteración _ | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| SALIDA 1 | EN 1 | SALIDA 2 | EN 2 | SALIDA 3 | EN 3 | SALIDA 4 | EN 4 | |||
|
4 |
vr | q | ∅ | ∅ | ∅ | rv | q, r, v | rv | q, r, v | rv |
|
3 |
tu | q | ∅ | ∅ | vr | s,u,r,v | vr | s, tu, v, r | vr | s, tu, v, r |
|
2 |
tu | v | ∅ | ∅ | vr | tu | vr | tu | vr | tu |
|
1 |
q, r, v | p, s, tu | ∅ | ∅ | s,u,r,v | q, r, v | s,u,r,v | q, r, v | s,u,r,v | q, r, v |
Para la primera iteración, cuando comenzamos el procedimiento con el Node-4, tenemos OUT y IN establecidos en ∅. OUT y IN son conjuntos vacíos a partir de ahora. Ahora OUT[n] se evalúa usando la expresión ∪ s∈succ[n] in[s] y como el Node-4 es reemplazado por el Node-1, tenemos:
Using , out[n] ← ∪s∈succ[n]in[s] , we have OUT2[4] ← IN2[1] OUT2[4] ← ∅
Es importante tener en cuenta que IN 2 [1] aún no se ha evaluado para la primera iteración. Aquí, solo usamos el valor inicial para IN 2 [1], que es lo mismo que IN 1 [1] y es un conjunto vacío. Posteriormente, cuando el valor se evalúa por procedimiento, el resultado también se actualiza en la tabla.
De manera similar, evaluamos IN 2 [4] de la siguiente manera:
in[n] ← use[n]∪(out[n]−def [n])
IN2[4] ← use[4]∪(OUT2[4]-def[4])
We know, use[4]← {v,r} , OUT2[4] is ∅ & def[4] ← {q}
IN2[4] ← {v,r}∪( ∅ - {q} )
IN2[4] ← {v,r}
Evaluemos IN y OUT para el Node-1, que es sucedido por el Node-2 y el Node-3, de la siguiente manera:
Using , out[n] ← ∪s∈succ[n]in[s] , we have
OUT2[1] ← IN2[2] ∪ IN2[3]
OUT2[1] ← {s, u, r, v} ∪ {r, u}
OUT2[1] ← { s, u, r, v}
Ahora evaluamos IN 2 [1] de la siguiente manera:
in[n] ← use[n]∪(out[n]−def [n])
IN2[1] ← use[1]∪(OUT2[1]-def[1])
We know, use[1]← {q, r, v} , OUT2[1] is {s,u,r,v} & def[1] ← {p,s,u}
IN2[1] ← {q,r,v}∪( {s,u,r,v}- {p,s,u})
IN2[1] ← {q,r,v}∪( {r,v} )
IN2[1] ← {q,r,v}
Además, tenga en cuenta que para la próxima iteración, OUT para Node-4 se evalúa de la siguiente manera:
Using , out[n] ← ∪s∈succ[n]in[s] , we have
OUT3[4] ← IN3[1]
Note that we use the already evaluated value of IN.
As we begin with Node-4 we use IN3[1] = IN2[1].
IN2[1] is as calculated above.
OUT3[4] ← { q, r ,v}
El procedimiento finaliza después de la tercera iteración ya que el valor de cada conjunto resultante de las últimas dos iteraciones es exactamente el mismo.
Análisis de la Complejidad del Tiempo:
Para un programa de entrada de tamaño N, ≤ N Nodes en CFG y ≤ N variables tenemos:
- N elementos por entrada/salida y, por lo tanto, para el peor de los casos tenemos, O(N) tiempo por conjunto de unión.
- Tenga en cuenta que el ciclo for realiza un número constante de operaciones de conjuntos por Node y, por lo tanto, O(N 2 ) es la complejidad de tiempo total para el ciclo.
- Los tamaños de todos los conjuntos IN y OUT suman 2N 2 , lo que limita el número de iteraciones del bucle de repetición.
- Podemos evaluar la complejidad temporal del peor de los casos del algoritmo de vivacidad como O(N 4 ).
- Es importante tener en cuenta que la ordenación adecuada y el uso de una estructura de datos eficiente pueden reducir el ciclo de repetición a 2 o 3 iteraciones.
- Podemos concluir que la mínima complejidad temporal posible en el peor de los casos del algoritmo de vivacidad es O(N) u O(N 2 ).
Publicación traducida automáticamente
Artículo escrito por medha130101 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA