La teoría de la información es una rama de la teoría de la probabilidad que se relaciona con la probabilidad de error. Una transmisión sin errores es posible cuando la probabilidad de error en el receptor se aproxima a 0. Es el cálculo numérico de las ideas, límites y reglas que rigen la transmisión de mensajes a través de los sistemas de comunicación. La teoría de la información está relacionada con el concepto de información (entropía), donde la entropía es la información promedio de cualquier fuente de información y se denota por ‘H’.
En un sistema de comunicación, la transmisión del mensaje sin errores es el principal desafío. La mayor parte del error ocurre en el canal o en el ruido. Para superar este problema, se utilizan técnicas de detección y corrección de errores.
- Codificación : La codificación es el proceso de convertir un mensaje en formato binario, es decir, en forma de 0 y 1.
- Decodificación : La decodificación es el proceso de extraer el mensaje original de la palabra clave codificada en binario.
Esta codificación y decodificación se utilizan para la transmisión de datos de un lugar a otro.
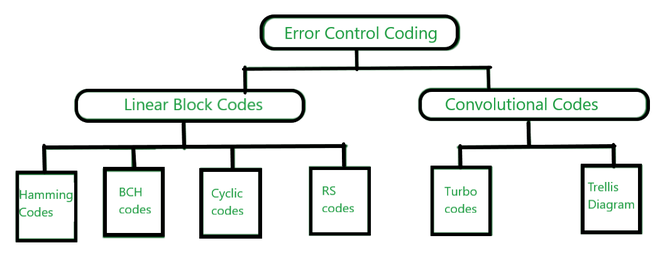
Códigos de bloques lineales:
Es una técnica simple de codificación de control de errores utilizada para la detección y corrección de errores.
- Los datos de información se dividen en bloques de K piezas de longitud, por ejemplo, palabra de información.
- A continuación, cada palabra de información se codifica en un bloque de n bits de longitud llamado palabra de código. Aquí, n > k
- Además, n = k + r, donde ‘r’ denota los bits de paridad o bits de control agregados a cada palabra de información.
- La documentación de vectores se utiliza para la palabra de datos y la palabra de código: mensaje m = (m 1 , m 2 m n ), palabra de código c = (c 1 , c 2 c n ).
- Consta de códigos Hamming , códigos Reed-Solomon (RS) , Bose-Chaudhuri-Hocquenghem (BCH) y códigos cíclicos .
Códigos convolucionales:
El código convolucional es otro tipo de código de corrección de errores en el que los bits resultantes se adquieren mediante la ejecución de un procedimiento lógico ideal en el flujo de bits actual junto con la consideración del bit anterior.
- En los códigos convolucionales, solo los bits de paridad que posiblemente contengan errores son recibidos por el otro usuario o sistema, que luego los decodifica para tener la disposición de bits más ideal, es decir, el bit de mensaje en sí.
- Los registros de desplazamiento se utilizan para almacenar bits de entrada.
- El bloque de palabra clave de ‘n’ dígitos generado en la codificación depende no solo de los dígitos del mensaje ‘k’, sino también de los bloques de mensajes m-1 anteriores.
- Consta de códigos Turbo y un diagrama de Trellis.
Control de errores Codificación
Diferencia entre códigos de bloques lineales y códigos convolucionales:
Los códigos de bloque lineal y los códigos convolucionales son códigos de control de errores que se utilizan para la detección y codificación de corrección de errores. Las principales diferencias entre estos dos códigos se enumeran a continuación:
| S. No | Códigos de bloques lineales | Códigos convolucionales |
|---|---|---|
| 1. | Los códigos de bloque toman k bits de entrada y producen n bits de salida donde k y n son muy grandes. (cuando k>1), k es el número de bits del mensaje | Los códigos convolucionales toman una pequeña cantidad de bits de entrada y producen una pequeña cantidad de bits de salida para cada período. (cuando K=1). |
| 2. | En los códigos de bloque lineal, los bits de información son seguidos inmediatamente por los bits de paridad. | En los códigos convolucionales, los bits de información no van seguidos de bits de paridad, sino que se distribuyen a lo largo de la secuencia. |
| 3. | La codificación del estado actual es independiente del estado anterior y, por lo tanto, no tiene ningún elemento de memoria. Depende únicamente del bit de mensaje presente. | La codificación del estado actual depende del estado anterior y de los elementos pasados, por lo que tiene un elemento de memoria para almacenar información del estado anterior. |
| 4. | Los códigos de bloque se prefieren en forma sistemática y tienen una estructura eficiente, es decir, la posición de paridad o bits de verificación está bien definida | Los códigos convolucionales se prefieren en forma no sistemática y no tienen una estructura tan eficiente, es decir, no se define la posición de paridad o los bits de control. |
| 5. | Los códigos de bloque son adecuados para detectar y prevenir errores aleatorios | Los códigos convolucionales son adecuados para detectar y prevenir errores de ráfaga |
| 6. | El componente de hardware de los códigos de bloque es complejo y el proceso de codificación es un poco difícil. | El componente de hardware de los códigos convolucionales es más simple y el proceso de codificación es fácil. |
| 7. | Los tipos de códigos de bloque lineal son códigos Hamming, códigos BCH, códigos cíclicos, códigos Reed-Solomon | Los tipos de códigos convolucionales son los códigos Turbo y el código Trellis. |
Todos estos códigos utilizan un tipo diferente de algoritmo o técnica para identificar el bit de error y resolverlo agregando o eliminando algunos bits. Además, existen varios tipos de códigos cíclicos también para la generación y detección de un error en el canal debido a diversas razones como ruido, etc.
Tanto los códigos de bloques lineales como los códigos convolucionales se utilizan en varios dominios y tienen una amplia gama de aplicaciones, por ejemplo, ciberseguridad, criptografía, teoría de la computación, biología (representando códigos de ADN), etc.
Publicación traducida automáticamente
Artículo escrito por saraswatgaurang y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA