En un entorno de programación múltiple, a menudo sucede que más de un proceso compite por los recursos de la CPU al mismo tiempo. Si solo hay una CPU disponible, se debe elegir entre los procesos que se ejecutarán a continuación. La parte del sistema operativo responsable de elegir el proceso se denomina Programador y el algoritmo que utiliza se denomina Algoritmo de programación.
El objetivo de la programación múltiple es maximizar la utilización de la CPU. Se sugieren criterios como el tiempo de respuesta, el tiempo de respuesta, el tiempo de espera y los rendimientos sobre la base de los cuales se juzgan los algoritmos de programación. Hay muchos algoritmos de programación de CPU, dos de los cuales son:
Diferencia entre los algoritmos de programación de CPU de la cola multinivel (MLQ) y la cola de retroalimentación multinivel (MLFQ):
| Programación de colas multinivel (MLQ) | Programación de colas de retroalimentación multinivel (MLFQ) |
|---|---|
| Es un algoritmo de programación de colas en el que la cola lista se divide en varias colas más pequeñas y los procesos se asignan permanentemente a estas colas. Los procesos se dividen en función de sus características intrínsecas, como el tamaño de la memoria, la prioridad, etc. | En este algoritmo, la cola lista se divide en colas más pequeñas en función de las características de ráfaga de CPU. Los procesos no se asignan permanentemente a una cola y se les permite moverse entre colas. |
| En esta cola de algoritmos, se clasifican en dos grupos, el primero que contiene procesos en segundo plano y el segundo que contiene procesos en primer plano. El 80 % del tiempo de CPU se asigna a la cola en primer plano mediante el algoritmo Round Robin y el 20 % del tiempo se asigna a los procesos en segundo plano mediante el algoritmo First Come First Serve. |
Aquí, las colas se clasifican como colas de mayor prioridad y colas de menor prioridad. Si el proceso tarda más tiempo en ejecutarse, se mueve a una cola de menor prioridad. Por lo tanto, este algoritmo deja los procesos interactivos y vinculados a E/S en la cola de mayor prioridad. |
| La prioridad se fija en este algoritmo. Cuando todos los procesos en una cola se ejecutan por completo, solo se ejecutan los procesos en otra cola. Por lo tanto, el hambre puede ocurrir. |
La prioridad para el proceso es dinámica ya que el proceso puede moverse entre colas. Un proceso que lleva más tiempo en la cola de menor prioridad puede cambiarse a una cola de mayor prioridad y viceversa. Por lo tanto, previene el hambre. |
| Dado que los procesos no se mueven entre las colas, tiene una sobrecarga de programación baja y es inflexible. | Dado que los procesos pueden moverse entre colas, tiene una gran sobrecarga de programación y es flexible. |
1. Ejemplo de programación de colas multinivel (MLQ):
una cola multinivel con cinco colas se enumera a continuación según el orden de prioridad.
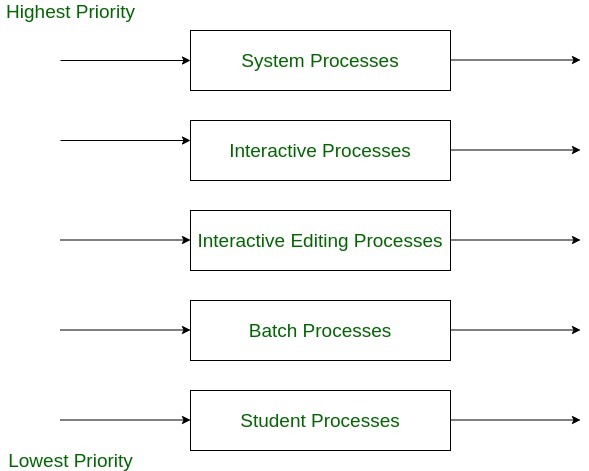
- Cola de proceso del sistema
- Cola de Procesos Interactivos
- Cola de procesos de edición interactiva
- Cola de procesos por lotes
- Cola de procesos de estudiantes
Aquí, todas las colas tienen su propio algoritmo de programación y el proceso se elige con la máxima prioridad. Entonces se ejecuta de forma preventiva o no preventiva. Ningún proceso en la cola de prioridad más baja puede ejecutarse hasta que la cola de procesos más alta esté vacía.
Por ejemplo, si la cola del proceso por lotes se está ejecutando y el proceso interactivo viene en estado listo, el proceso por lotes se reemplaza y se permite que se ejecute el proceso interactivo.
2. Ejemplo de programación de colas de comentarios multinivel (MLFQ):
Ahora, consideremos una cola de comentarios multinivel con tres colas.
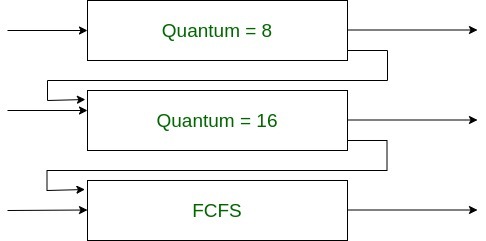
- Una cola Round Robin con un cuanto de tiempo de 8 milisegundos, digamos Q1.
- Una cola Round Robin con un cuanto de tiempo de 16 milisegundos, digamos Q2.
- Una cola por orden de llegada, digamos Q3.
Ahora, cuando el proceso ingresa a Q1, se le permite ejecutar y si no se completa en 8 milisegundos, se cambia a Q2 y recibe 16 milisegundos. Nuevamente, se adelanta a Q3 si no se completa en 16 segundos. De esta manera, la programación se lleva a cabo en este esquema.