Prerrequisito: Seaborn
El gráfico Ridgeline es un conjunto de gráficos de densidad superpuestos que ayudan a comparar distribuciones múltiples entre conjuntos de datos. Los diagramas de Ridgeline se ven como una string montañosa, pueden ser bastante útiles para visualizar cambios en las distribuciones a lo largo del tiempo o el espacio. A veces también se conoce como «joyplot», en referencia a la icónica portada del álbum Unknown Pleasures de Joy Division. En este artículo, veremos cómo generar gráficos Ridgeline para el conjunto de datos.
Instalación
Como cualquier otra biblioteca de python, seaborn se puede instalar fácilmente usando pip:
pip install seaborn
Esta biblioteca es parte de la distribución de Anaconda y, por lo general, funciona solo con la importación si su IDE es compatible con Anaconda, pero también se puede instalar con el siguiente comando:
conda install seaborn
Procedimiento
- Cargue los paquetes necesarios para generar el gráfico de Ridgeline con Python.
- Leer el conjunto de datos. En este ejemplo, usamos el método read_csv() para cargar el conjunto de datos. En el ejemplo dado, solo mostraremos las 5 entradas principales usando el método head() .
- Generar RidgePlot. Ridgeline Plot utiliza facetas, lo que significa que crea múltiplos pequeños, en una sola columna. Para generar Ridgeline Plot, Seaborn usa el método FacetGrid() y se le debe pasar toda la información requerida
Sintaxis: seaborn.FacetGrid(datos, fila, columna, tono, paleta, aspecto, altura)
Parámetros:
- datos: marco de datos ordenado («formato largo») donde cada columna es una variable y cada fila es una observación.
- fila, columna, tonalidad : Variables que definen subconjuntos de los datos, que se dibujarán en facetas separadas en la cuadrícula.
- altura: Altura (en pulgadas) de cada faceta.
- aspecto: relación de aspecto de cada faceta, de modo que aspecto * altura da el ancho de cada faceta en pulgadas.
- paleta: Colores a utilizar para los diferentes niveles de la variable matiz.
- Utilice el método map() para crear un gráfico de densidad en cada elemento de la cuadrícula. En este ejemplo, necesitamos un gráfico de densidad, así que use el método kdeplot() que está disponible en Seaborn.
Base de datos de muestra: el conjunto de datos utilizado en el siguiente ejemplo se descarga de kaggle.com. El siguiente enlace se puede utilizar para el mismo.
Base de datos: titanic_train.csv
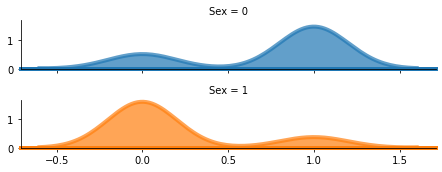
Ejemplo:
Python3
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import preprocessing
df = pd.read_csv("titanic_train.csv")
df.dropna()
le = preprocessing.LabelEncoder()
df["Sex"] = le.fit_transform(df["Sex"])
rp = sns.FacetGrid(df, row="Sex", hue="Sex", aspect=5, height=1.25)
rp.map(sns.kdeplot, 'Survived', clip_on=False,
shade=True, alpha=0.7, lw=4, bw=.2)
rp.map(plt.axhline, y=0, lw=4, clip_on=False)
Producción :
Publicación traducida automáticamente
Artículo escrito por abhijitmahajan772 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA