La distancia de Mahalanobis se define como la distancia entre dos puntos dados siempre que se encuentren en un espacio multivariante. Esta distancia se utiliza para determinar el análisis estadístico que contiene un montón de variables.
El usuario debe instalar e importar las siguientes bibliotecas para calcular la distancia de Mahalanobis en Python:
- entumecido
- pandas
- espía
Sintaxis para instalar todos los paquetes anteriores:
pip3 install numpy pandas scipy
Paso 1: El primer paso es importar todas las bibliotecas instaladas anteriormente.
Python3
# Importing libraries import numpy as np import pandas as pd import scipy as stats
Paso 2: Creación de un conjunto de datos. Considere los datos de 10 autos de diferentes marcas. Los datos tienen cinco secciones:
- Precio
- Distancia
- Emisión generada
- Actuación
- Kilometraje
Python3
# data
data = { 'Price': [100000, 800000, 650000, 700000,
860000, 730000, 400000, 870000,
780000, 400000],
'Distance': [16000, 60000, 300000, 10000,
252000, 350000, 260000, 510000,
2000, 5000],
'Emission': [300, 400, 1230, 300, 400, 104,
632, 221, 142, 267],
'Performance': [60, 88, 90, 87, 83, 81, 72,
91, 90, 93],
'Mileage': [76, 89, 89, 57, 79, 84, 78, 99,
97, 99]
}
# Creating dataset
df = pd.DataFrame(data,columns=['Price', 'Distance',
'Emission','Performance',
'Mileage'])
Paso 3: Determinación de la distancia de Mahalanobis para cada observación.
Python3
# Importing libraries import numpy as np import pandas as pd import scipy as stats # calculateMahalanobis function to calculate # the Mahalanobis distance def calculateMahalanobis(y=None, data=None, cov=None): y_mu = y - np.mean(data) if not cov: cov = np.cov(data.values.T) inv_covmat = np.linalg.inv(cov) left = np.dot(y_mu, inv_covmat) mahal = np.dot(left, y_mu.T) return mahal.diagonal() # create new column in dataframe that contains # Mahalanobis distance for each row df['calculateMahalanobis'] = mahalanobis(x=df, data=df[['Price', 'Distance', 'Emission','Performance', 'Mileage']])
Combinando todos los pasos:
Ejemplo:
Python3
# Importing libraries
import numpy as np
import pandas as pd
import scipy as stats
# calculateMahalanobis function to calculate
# the Mahalanobis distance
def calculateMahalanobis(y=None, data=None, cov=None):
y_mu = y - np.mean(data)
if not cov:
cov = np.cov(data.values.T)
inv_covmat = np.linalg.inv(cov)
left = np.dot(y_mu, inv_covmat)
mahal = np.dot(left, y_mu.T)
return mahal.diagonal()
# data
data = { 'Price': [100000, 800000, 650000, 700000,
860000, 730000, 400000, 870000,
780000, 400000],
'Distance': [16000, 60000, 300000, 10000,
252000, 350000, 260000, 510000,
2000, 5000],
'Emission': [300, 400, 1230, 300, 400, 104,
632, 221, 142, 267],
'Performance': [60, 88, 90, 87, 83, 81, 72,
91, 90, 93],
'Mileage': [76, 89, 89, 57, 79, 84, 78, 99,
97, 99]
}
# Creating dataset
df = pd.DataFrame(data,columns=['Price', 'Distance',
'Emission','Performance',
'Mileage'])
# Creating a new column in the dataframe that holds
# the Mahalanobis distance for each row
df['calculateMahalanobis'] = calculateMahalanobis(y=df, data=df[[
'Price', 'Distance', 'Emission','Performance', 'Mileage']])
# Display the dataframe
print(df)
Producción:

Cálculo del valor p para cada distancia de Mahalanobis
Ahora calculemos el valor p para cada distancia de Mahalanobis de cada observación del conjunto de datos. Como se desprende del resultado anterior, algunas de las distancias de Mahalanobis son significativamente mayores que otros valores. Para calcular si algunas de las distancias son estadísticamente significativas, necesitamos encontrar su valor p. El p-valor para cada una de las distancias es igual al p-valor que pertenece al estadístico Chi-Cuadrado de la distancia de Mahalanobis teniendo grados de libertad iguales a k-1, donde k = número de variables. Entonces, en este caso, usaremos un grado de libertad de 5-1 = 4.
Ejemplo:
Python3
# Importing libraries
import numpy as np
import pandas as pd
import scipy as stats
from scipy.stats import chi2
# calculateMahalanobis Function to calculate
# the Mahalanobis distance
def calculateMahalanobis(y=None, data=None, cov=None):
y_mu = y - np.mean(data)
if not cov:
cov = np.cov(data.values.T)
inv_covmat = np.linalg.inv(cov)
left = np.dot(y_mu, inv_covmat)
mahal = np.dot(left, y_mu.T)
return mahal.diagonal()
# data
data = { 'Price': [100000, 800000, 650000, 700000,
860000, 730000, 400000, 870000,
780000, 400000],
'Distance': [16000, 60000, 300000, 10000,
252000, 350000, 260000, 510000,
2000, 5000],
'Emission': [300, 400, 1230, 300, 400, 104,
632, 221, 142, 267],
'Performance': [60, 88, 90, 87, 83, 81, 72,
91, 90, 93],
'Mileage': [76, 89, 89, 57, 79, 84, 78, 99,
97, 99]
}
# Creating dataset
df = pd.DataFrame(data,columns=['Price', 'Distance',
'Emission','Performance',
'Mileage'])
# Creating a new column in the dataframe that holds
# the Mahalanobis distance for each row
df['Mahalanobis'] = calculateMahalanobis(y=df, data=df[[
'Price', 'Distance', 'Emission','Performance', 'Mileage']])
# calculate p-value for each mahalanobis distance
df['p'] = 1 - chi2.cdf(df['Mahalanobis'], 3)
# display first five rows of dataframe
print(df)
Producción:
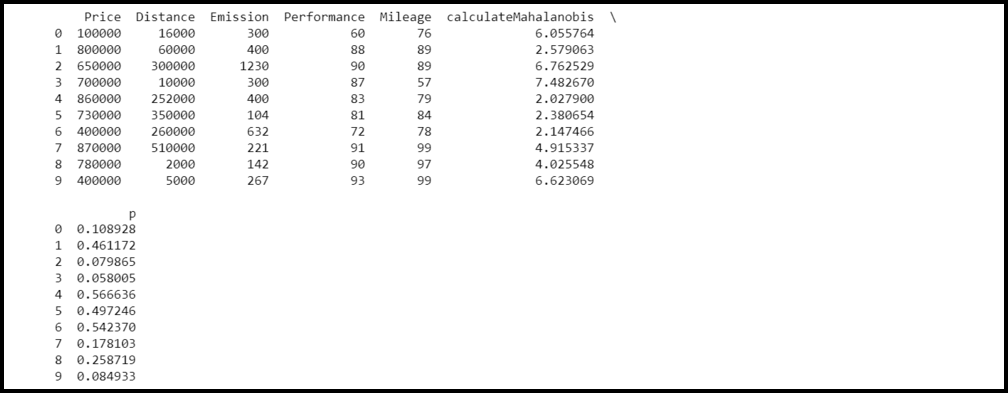
Interpretación:
En general, se supone que la observación que tiene un valor de p inferior a 0,001 es un valor atípico. En este ejemplo, no hay ningún valor atípico ya que todos los valores p son mayores que 0,001.