La visualización de datos es la presentación de datos en formato pictórico. Es extremadamente importante para el análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Y ayuda a comprender los datos, por complejos que sean, la importancia de los datos al resumir y presentar una gran cantidad de datos en un formato simple y fácil de entender y ayuda a comunicar la información de manera clara y efectiva.

Pandas and Seaborn es uno de esos paquetes y facilita mucho la importación y el análisis de datos. En este artículo, usaremos Pandas y Seaborn para analizar datos.
pandas
Pandas ofrece herramientas para limpiar y procesar sus datos. Es la biblioteca de Python más popular que se utiliza para el análisis de datos. En pandas, una tabla de datos se llama marco de datos.
Entonces, comencemos con la creación del marco de datos de Pandas:
Ejemplo 1:
Python3
# Python code demonstrate creating
import pandas as pd
# initialise data of lists.
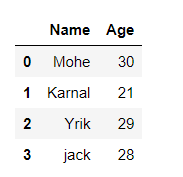
data = {'Name':[ 'Mohe' , 'Karnal' , 'Yrik' , 'jack' ],
'Age':[ 30 , 21 , 29 , 28 ]}
# Create DataFrame
df = pd.DataFrame( data )
# Print the output.
df
Producción:
Ejemplo 2: cargue los datos CSV del sistema y muéstrelos a través de pandas.
Python3
# import module
import pandas
# load the csv
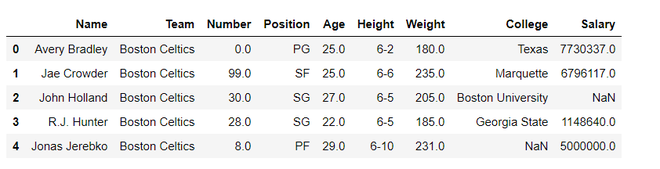
data = pandas.read_csv("nba.csv")
# show first 5 column
data.head()
Producción:
nacido en el mar
Seaborn es una increíble biblioteca de visualización para el trazado de gráficos estadísticos en Python. Está construido en la parte superior de la biblioteca matplotlib y también está estrechamente integrado en las estructuras de datos de pandas .
Instalación
Para el entorno de Python:
pip install seaborn
Para el entorno de conda:
conda install seaborn
Vamos a crear algunas tramas básicas usando seaborn:
Python3
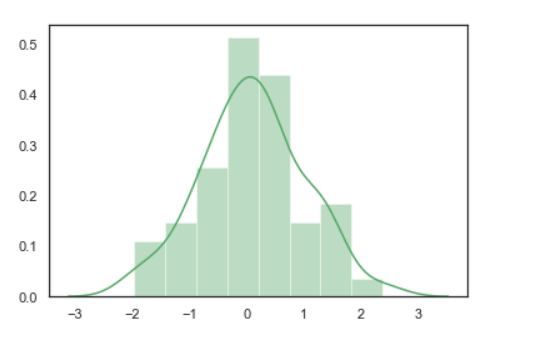
# Importing libraries import numpy as np import seaborn as sns # Selecting style as white, # dark, whitegrid, darkgrid # or ticks sns.set( style = "white" ) # Generate a random univariate # dataset rs = np.random.RandomState( 10 ) d = rs.normal( size = 50 ) # Plot a simple histogram and kde # with binsize determined automatically sns.distplot(d, kde = True, color = "g")
Producción:
Seaborn: visualización de datos estadísticos
Seaborn ayuda a visualizar las relaciones estadísticas. Para comprender cómo las variables en un conjunto de datos se relacionan entre sí y cómo esa relación depende de otras variables, realizamos un análisis estadístico. Este análisis estadístico ayuda a visualizar las tendencias e identificar varios patrones en el conjunto de datos.
Estos son la trama ayudará a visualizar:
- Gráfico de línea
- Gráfico de dispersión
- diagrama de caja
- Gráfico de puntos
- Parcela de conteo
- Trama de violín
- trama de enjambre
- Parcela de barras
- Parcela KDE
Gráfico de línea:
Lineplot Es el diagrama más popular para dibujar una relación entre x e y con la posibilidad de varias agrupaciones semánticas.
Sintaxis: sns.lineplot(x=Ninguno, y=Ninguno)
Parámetros:
x, y: variables de datos de entrada; debe ser numérico. Puede pasar datos directamente o hacer referencia a columnas en los datos.
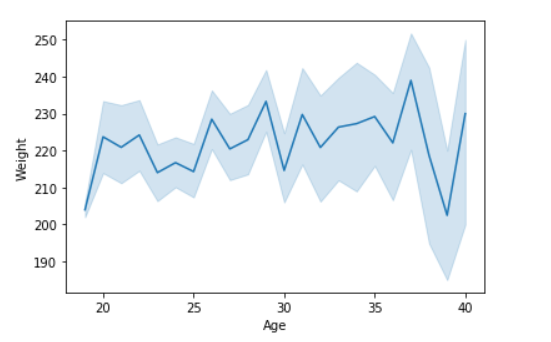
Visualicemos los datos con un gráfico de líneas y pandas:
Ejemplo 1:
Python3
# import module
import seaborn as sns
import pandas
# loading csv
data = pandas.read_csv("nba.csv")
# plotting lineplot
sns.lineplot( data['Age'], data['Weight'])
Producción:
Ejemplo 2: use el parámetro de tono para trazar el gráfico.
Python3
# import module
import seaborn as sns
import pandas
# read the csv data
data = pandas.read_csv("nba.csv")
# plot
sns.lineplot(data['Age'],data['Weight'], hue =data["Position"])
Producción:
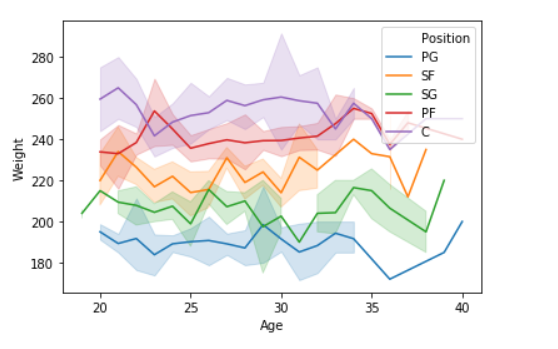
Gráfico de dispersión:
Diagrama de dispersión Se puede usar con varias agrupaciones semánticas que pueden ayudar a comprender bien un gráfico frente a datos continuos/categóricos. Puede dibujar un gráfico bidimensional.
Sintaxis: seaborn.scatterplot(x=Ninguno, y=Ninguno)
Parámetros:
x, y: Variables de datos de entrada que deben ser numéricos.Devoluciones: este método devuelve el objeto Axes con el gráfico dibujado en él.
Visualicemos los datos con un diagrama de dispersión y pandas:
Ejemplo 1:
Python3
# import module
import seaborn
import pandas
# load csv
data = pandas.read_csv("nba.csv")
# plotting
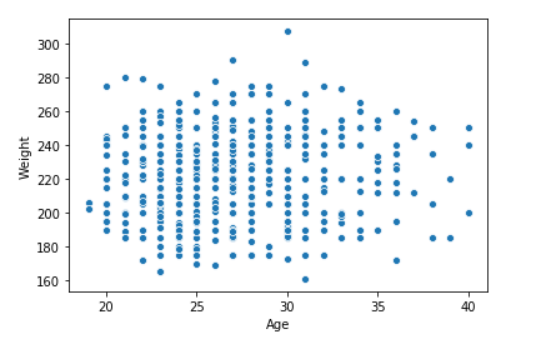
seaborn.scatterplot(data['Age'],data['Weight'])
Producción:
Ejemplo 2: use el parámetro de tono para trazar el gráfico.
Python3
import seaborn
import pandas
data = pandas.read_csv("nba.csv")
seaborn.scatterplot( data['Age'], data['Weight'], hue =data["Position"])
Producción:
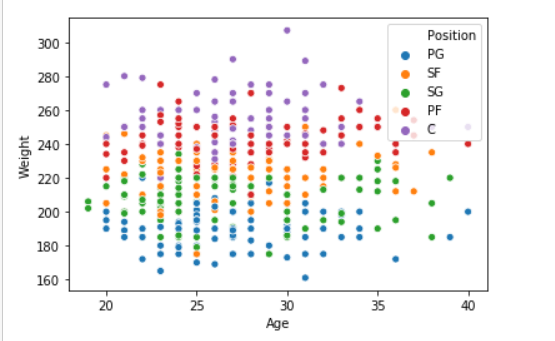
Diagrama de caja:
Un diagrama de caja (o diagrama de caja y bigotes) es la representación visual de los grupos de representación de datos numéricos a través de sus cuartiles contra datos continuos/categóricos.
Un diagrama de caja consta de 5 cosas.
- Mínimo
- Primer Cuartil o 25%
- Mediana (Segundo Cuartil) o 50%
- Tercer Cuartil o 75%
- Máximo
Sintaxis:
seaborn.boxplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y, hue: entradas para trazar datos de formato largo.
- datos: conjunto de datos para el trazado. Si x e y están ausentes, esto se interpreta como formato ancho.
Devoluciones: Devuelve el objeto Axes con la trama dibujada en él.
Dibuja el diagrama de caja con Pandas:
Ejemplo 1:
Python3
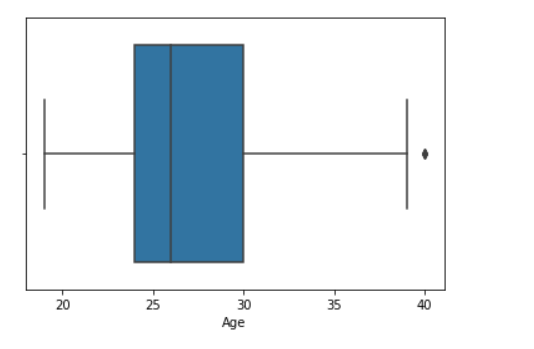
# import module import seaborn as sns import pandas # read csv and plotting data = pandas.read_csv( "nba.csv" ) sns.boxplot( data['Age'] )
Producción:
Ejemplo 2:
Python3
# import module import seaborn as sns import pandas # read csv and plotting data = pandas.read_csv( "nba.csv" ) sns.boxplot( data['Age'], data['Weight'])
Producción:
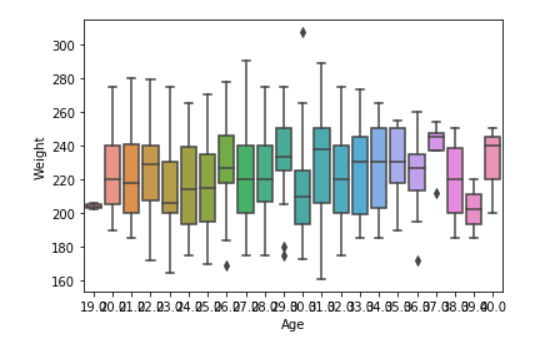
Argumento de violín:
Un diagrama de violín es similar a un diagrama de caja. Muestra varios datos cuantitativos a través de una o más variables categóricas, de modo que esas distribuciones se pueden comparar.
Sintaxis: seaborn.violinplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y, hue: entradas para trazar datos de formato largo.
- datos: conjunto de datos para el trazado.
Dibuja la trama del violín con Pandas:
Ejemplo 1:
Python3
# import module
import seaborn as sns
import pandas
# read csv and plot
data = pandas.read_csv("nba.csv")
sns.violinplot(data['Age'])
Producción:
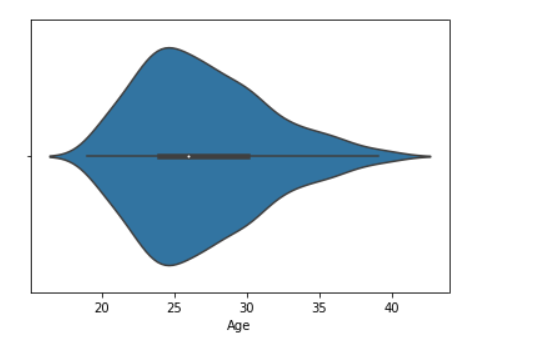
Ejemplo 2:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.violinplot(x ="Age", y ="Weight",data = data)
Producción:
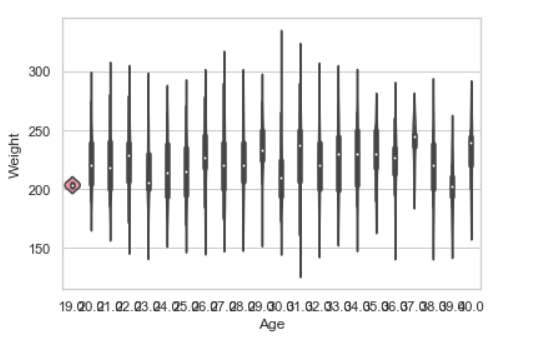
Parcela de enjambre:
Un diagrama de enjambre es similar a un diagrama de franjas. Podemos dibujar un diagrama de enjambre con puntos que no se superponen contra datos categóricos.
Sintaxis: seaborn.swarmplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y, hue: entradas para trazar datos de formato largo.
- datos: conjunto de datos para el trazado.
Dibuja la trama del enjambre con Pandas:
Ejemplo 1:
Python3
# import module import seaborn seaborn.set(style = 'whitegrid') # read csv and plot data = pandas.read_csv( "nba.csv" ) seaborn.swarmplot(x = data["Age"])
Producción:
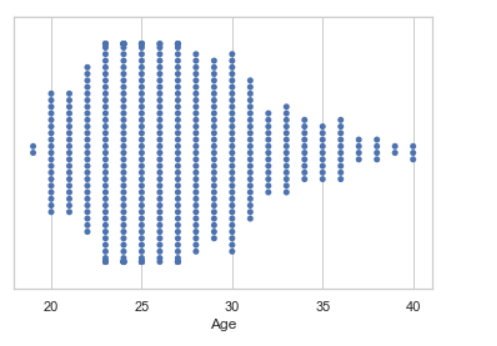
Ejemplo 2:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.swarmplot(x ="Age", y ="Weight",data = data)
Producción:
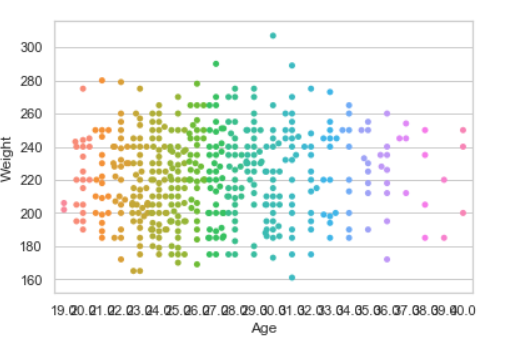
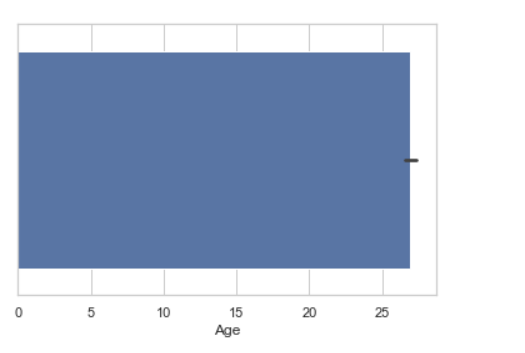
Parcela de barras:
Barplot representa una estimación de la tendencia central de una variable numérica con la altura de cada rectángulo y proporciona alguna indicación de la incertidumbre en torno a esa estimación utilizando barras de error.
Sintaxis: seaborn.barplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y : este parámetro toma nombres de variables en datos o datos vectoriales, Entradas para trazar datos de formato largo.
- matiz: (opcional) Este parámetro toma el nombre de la columna para la codificación de colores.
- datos: (opcional) este parámetro toma DataFrame, array o lista de arrays, conjunto de datos para trazar. Si x e y están ausentes, esto se interpreta como formato ancho. De lo contrario, se espera que sea de formato largo.
Devoluciones: devuelve el objeto Axes con el gráfico dibujado en él.
Dibuja el gráfico de barras con Pandas:
Ejemplo 1:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x =data["Age"])
Producción:
Ejemplo 2:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.barplot(x ="Age", y ="Weight", data = data)
Producción:
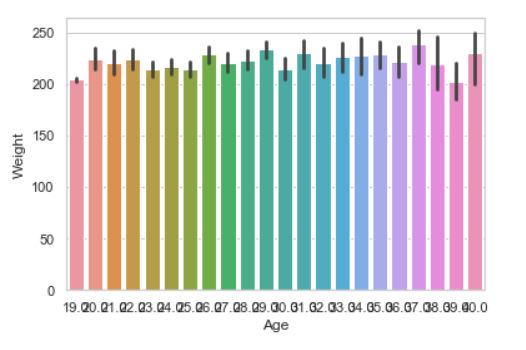
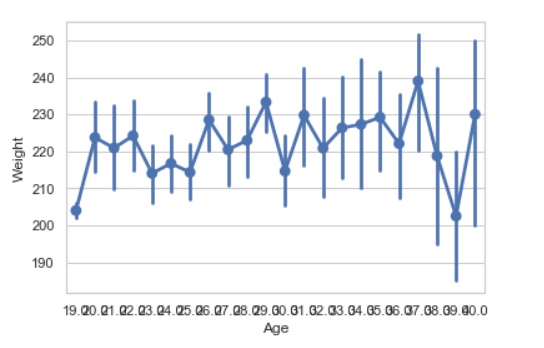
Gráfico de puntos:
Gráfico de puntos utilizado para mostrar estimaciones de puntos e intervalos de confianza utilizando glifos de gráficos de dispersión. Un gráfico de puntos representa una estimación de la tendencia central de una variable numérica por la posición de los puntos del gráfico de dispersión y proporciona alguna indicación de la incertidumbre en torno a esa estimación utilizando barras de error.
Sintaxis: seaborn.pointplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y: Entradas para trazar datos de formato largo.
- matiz: (opcional) nombre de columna para la codificación de color.
- datos: marco de datos como un conjunto de datos para trazar.
Retorno: El objeto Axes con la trama dibujada en él.
Dibuja el diagrama de puntos con Pandas:
Ejemplo:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
seaborn.pointplot(x = "Age", y = "Weight", data = data)
Producción:
Parcela de conteo:
Gráfica de recuento utilizada para mostrar los recuentos de observaciones en cada intervalo categórico mediante barras.
Sintaxis: seaborn.countplot(x=Ninguno, y=Ninguno, hue=Ninguno, data=Ninguno)
Parámetros:
- x, y: Este parámetro toma nombres de variables en datos o datos vectoriales, opcional, Entradas para graficar datos de formato largo.
- matiz: (opcional) Este parámetro toma el nombre de la columna para la codificación de color.
- datos: (opcional) este parámetro toma DataFrame, array o lista de arrays, conjunto de datos para trazar. Si x e y están ausentes, esto se interpreta como formato ancho. De lo contrario, se espera que sea de formato largo.
Devoluciones: devuelve el objeto Axes con el gráfico dibujado en él.
Dibuja el diagrama de conteo con Pandas:
Ejemplo:
Python3
# import module
import seaborn
seaborn.set(style = 'whitegrid')
# read csv and plot
data = pandas.read_csv("nba.csv")
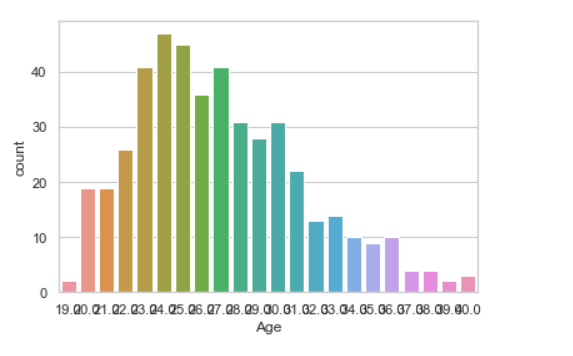
seaborn.countplot(data["Age"])
Producción:
Parcela KDE:
El gráfico de KDE descrito como estimación de la densidad del núcleo se utiliza para visualizar la densidad de probabilidad de una variable continua. Representa la densidad de probabilidad en diferentes valores en una variable continua. También podemos trazar un solo gráfico para múltiples muestras, lo que ayuda a una visualización de datos más eficiente.
Sintaxis: seaborn.kdeplot(x=Ninguno, *, y=Ninguno, vertical=Falso, palette=Ninguno, **kwargs)
Parámetros:
x, y : vectores o claves en datos
vertical: booleano (Verdadero o Falso)
datos: pandas.DataFrame, numpy.ndarray, mapeo o secuencia
Dibuje el diagrama de KDE con Pandas:
Ejemplo 1:
Python3
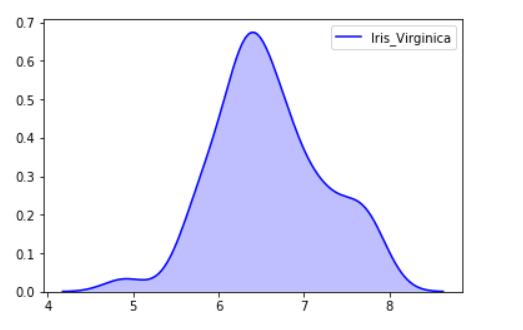
# importing the required libraries from sklearn import datasets import pandas as pd import seaborn as sns # Setting up the Data Frame iris = datasets.load_iris() iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Patal_Length', 'Petal_Width']) iris_df['Target'] = iris.target iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True) iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True) iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True) # Plotting the KDE Plot sns.kdeplot(iris_df.loc[(iris_df['Target'] =='Iris_Virginica'), 'Sepal_Length'], color = 'b', shade = True, Label ='Iris_Virginica')
Producción:
Ejemplo 2:
Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
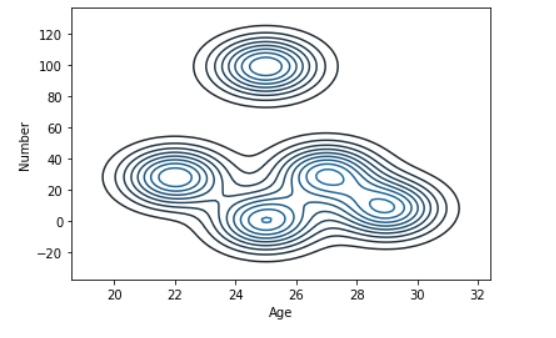
sns.kdeplot( data['Age'], data['Number'])
Producción:
Datos bivariados y univariados usando seaborn y pandas:
Antes de comenzar, tengamos una pequeña introducción de datos bivariados y univariados:
Datos bivariados: este tipo de datos involucran dos variables diferentes . El análisis de este tipo de datos se ocupa de las causas y las relaciones y el análisis se realiza para averiguar la relación entre las dos variables.
Datos univariados: este tipo de datos consta de una sola variable . El análisis de datos univariados es, por lo tanto, la forma más simple de análisis, ya que la información se ocupa de una sola cantidad que cambia. No se ocupa de causas o relaciones y el objetivo principal del análisis es describir los datos y encontrar patrones que existen dentro de ellos.
Veamos un ejemplo de datos bivariados:
Ejemplo 1: Usando el diagrama de caja.
Python3
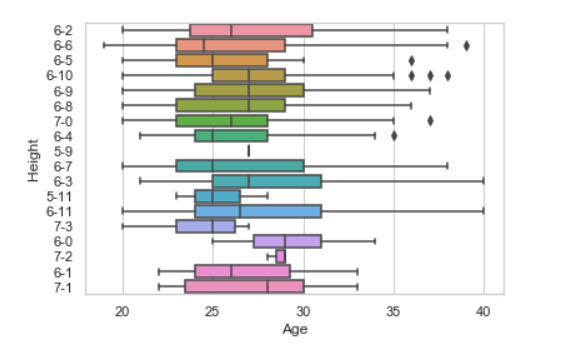
# import module import seaborn as sns import pandas # read csv and plotting data = pandas.read_csv( "nba.csv" ) sns.boxplot( data['Age'], data['Height'])
Producción:
Ejemplo 2: usando el diagrama de KDE.
Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.kdeplot( data['Age'], data['Weight'])
Producción:
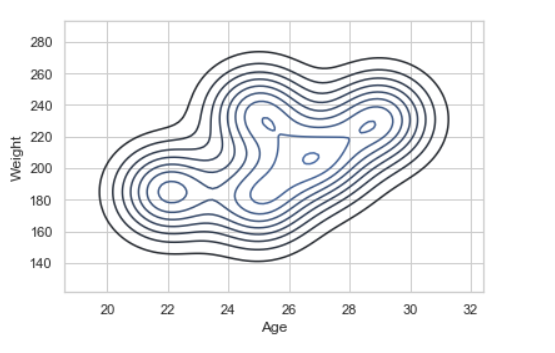
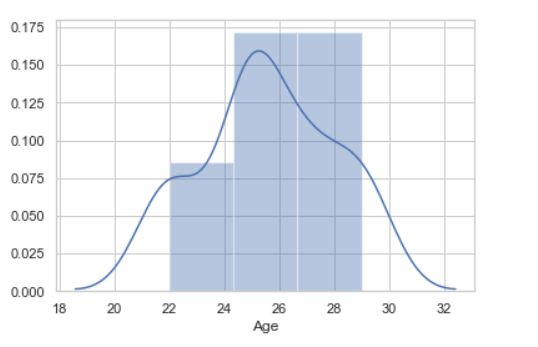
Veamos un ejemplo de distribución de datos univariados:
Ejemplo: uso del diagrama de distancia
Python3
# import module
import seaborn as sns
import pandas
# read top 5 column
data = pandas.read_csv("nba.csv").head()
sns.distplot( data['Age'])
Producción:
Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA