En este artículo, discutiremos cómo evitar columnas duplicadas en DataFrame después de unirse a PySpark usando Python.
Cree el primer marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
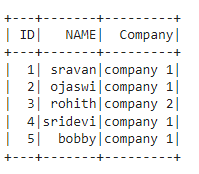
data = [["1", "sravan", "company 1"],
["2", "ojaswi", "company 1"],
["3", "rohith", "company 2"],
["4", "sridevi", "company 1"],
["5", "bobby", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
Producción:
Cree un segundo marco de datos para la demostración:
Python3
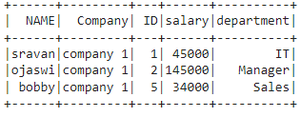
# list of employee data data1 = [["1", "45000", "IT"], ["2", "145000", "Manager"], ["6", "45000", "HR"], ["5", "34000", "Sales"]] # specify column names columns = ['ID', 'salary', 'department'] # creating a dataframe from the lists of data dataframe1 = spark.createDataFrame(data1, columns) dataframe1.show()
Producción:

Método 1: Usar la función drop()
Podemos unir los marcos de datos usando uniones como unión interna y después de esta unión, podemos usar el método de soltar para eliminar una columna duplicada.
Sintaxis : dataframe.join(dataframe1,dataframe.column_name == dataframe1.column_name,”inner”).drop(dataframe.column_name)
dónde,
- dataframe es el primer dataframe
- dataframe1 es el segundo marco de datos
- internal especifica unión interna
- drop() eliminará la columna común y eliminará la primera columna del marco de datos
Ejemplo: unir dos marcos de datos en función de la identificación y eliminar la identificación duplicada en el primer marco de datos
Python3
# inner join on two dataframes # and remove duplicate column dataframe.join(dataframe1, dataframe.ID == dataframe1.ID, "inner").drop(dataframe.ID).show()
Producción:
Método 2: Usar join()
Aquí simplemente estamos usando join para unir dos marcos de datos y luego soltar columnas duplicadas.
Sintaxis : dataframe.join(dataframe1, [‘column_name’]).show()
dónde,
- dataframe es el primer dataframe
- dataframe1 es el segundo marco de datos
- column_name es la columna común que existe en dos marcos de datos
Ejemplo: Únase según la ID y elimine los duplicados
Python3
# join on two dataframes # and remove duplicate column dataframe.join(dataframe1, ['ID']).show()
Producción:

Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA