En este artículo, discutiremos cómo convertir una tabulación cruzada de pandas en un marco de datos apilado.
Un DataFrame apilado es un índice de varios niveles con uno o más niveles internos nuevos en comparación con el DataFrame original. Si las columnas tienen un solo nivel, el resultado es un objeto de serie.
La función de tabulación cruzada de panda es una tabla de frecuencia que muestra la relación entre dos o más variables mediante la creación de una tabla de tabulación cruzada que calcula la frecuencia entre ciertos grupos de datos.
Sintaxis:
pandas.crosstab(índice, columnas, nombres de filas=Ninguno, nombres de columnas=Ninguno)
Parámetros :
- índice: array o serie o lista de objetos similares a una array. este valor se usa para agrupar en filas
- columnas: array o serie o lista de objetos similares a una array. este valor se usa para agrupar en columnas
- nombres de fila: el nombre especificado aquí debe coincidir con el número de arrays de fila pasadas.
- colnames: el nombre especificado aquí debe coincidir con el número de arrays de columnas pasadas.
Ejemplo:
En este ejemplo, estamos creando 3 arrays de muestra, a saber, car_brand, version, fuel_type como se muestra. Ahora, estamos pasando estas arrays como índice, columnas y nombres de fila y columna a la función de tabla de referencias cruzadas como se muestra.
Finalmente, el marco de datos de tabulación cruzada también se puede visualizar usando la función python plot.bar()
Python3
# import the numpy and pandas package import numpy as np import pandas as pd # create three separate arrays namely car_brand, # version, fuel_type as shown car_brand = np.array(["bmw", "bmw", "bmw", "bmw", "benz", "benz", "bmw", "bmw", "benz", "benz", "benz", "benz", "bmw", "bmw", "bmw", "benz", "benz", ], dtype=object) version = np.array(["one", "one", "one", "two", "one", "one", "one", "two", "one", "one", "one", "two", "two", "two", "one", "two", "one"], dtype=object) fuel_type = np.array(["petrol", "petrol", "petrol", "diesel", "diesel", "petrol", "diesel", "diesel", "diesel", "petrol", "petrol", "diesel", "petrol", "petrol", "petrol", "diesel", "diesel", ], dtype=object) # use pandas crosstab and pass the three arrays # as index and columns to create a crosstab table. cross_tab_data = pd.crosstab(index=car_brand, columns=[version, fuel_type], rownames=['car_brand'], colnames=['version', 'fuel_type']) print(cross_tab_data) barplot = cross_tab_data.plot.bar()
Producción:
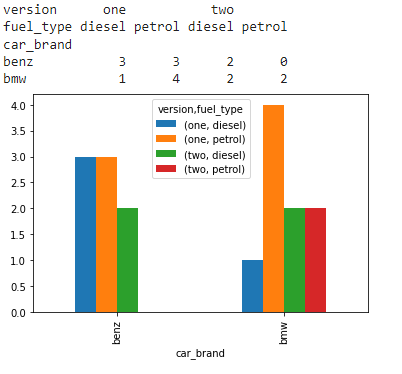
Conversión de tabulación cruzada a marco de datos apilado:
Aquí vamos a especificar el número de niveles a apilar. Esto se convertirá en función de los niveles del eje en las columnas particulares del DataFrame de pandas.
Sintaxis:
pandas.DataFrame.stack(level, dropna)
Parámetros :
- nivel: especifica los niveles que se apilarán desde el eje de la columna hasta el eje del índice en el marco de datos resultante
- dropna – un tipo bool. Si descartar o no las filas en el DataFrame/Series resultante con valores faltantes
Ejemplo 1:
Aquí, convertiremos la tabla de referencias cruzadas en un marco de datos apilado. El nivel fuel_type se apilará como una columna en el marco de datos resultante.
Python3
# import the numpy and pandas package import numpy as np import pandas as pd # create three separate arrays namely car_brand, # version, fuel_type as shown car_brand = np.array(["bmw", "bmw", "bmw", "bmw", "benz", "benz", "bmw", "bmw", "benz", "benz", "benz", "benz", "bmw", "bmw", "bmw", "benz", "benz", ], dtype=object) version = np.array(["one", "one", "one", "two", "one", "one", "one", "two", "one", "one", "one", "two", "two", "two", "one", "two", "one"], dtype=object) fuel_type = np.array(["petrol", "petrol", "petrol", "diesel", "diesel", "petrol", "diesel", "diesel", "diesel", "petrol", "petrol", "diesel", "petrol", "petrol", "petrol", "diesel", "diesel", ], dtype=object) # use pandas crosstab and pass the three # arrays as index and columns # to create a crosstab table. cross_tab_data = pd.crosstab(index=car_brand, columns=[version, fuel_type], rownames=['car_brand'], colnames=['version', 'fuel_type']) barplot = cross_tab_data.plot.bar() # use the created sample crosstab data # to convert it to a stacked dataframe stacked_data = cross_tab_data.stack(level=1) print(stacked_data)
Producción:
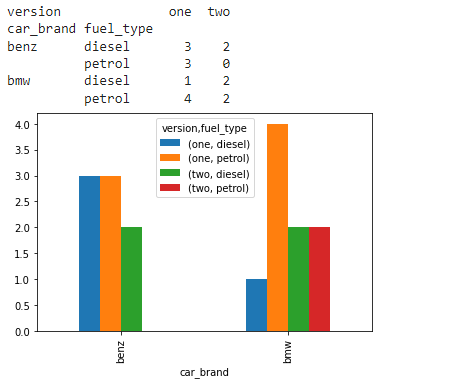
Ejemplo 2 :
En este ejemplo, hemos mostrado los resultados para dos niveles 1 y 2.
Python3
# import the numpy and pandas package import numpy as np import pandas as pd # create three separate arrays namely car_brand, # version, fuel_type as shown car_brand = np.array(["bmw", "bmw", "bmw", "bmw", "benz", "benz", "bmw", "bmw", "benz", "benz", "benz", "benz", "bmw", "bmw", "bmw", "benz", "benz", ], dtype=object) version = np.array(["one", "one", "one", "two", "one", "one", "one", "two", "one", "one", "one", "two", "two", "two", "one", "two", "one"], dtype=object) fuel_type = np.array(["petrol", "petrol", "petrol", "diesel", "diesel", "petrol", "diesel", "diesel", "diesel", "petrol", "petrol", "diesel", "petrol", "petrol", "petrol", "diesel", "diesel", ], dtype=object) year_release = np.array([2000, 2005, 2000, 2007, 2000, 2005, 2007, 2005, 2005, 2000, 2007, 2000, 2007, 2005, 2005, 2007, 2000], dtype=object) # use pandas crosstab and pass the three arrays # as index and columns to create a crosstab table. cross_tab_data = pd.crosstab(index=car_brand, columns=[version, fuel_type, year_release], rownames=['car_brand'], colnames=['version', 'fuel_type', 'year_release']) barplot = cross_tab_data.plot.bar() # use the created sample crosstab data to # convert it to a stacked dataframe with # level 1 stacked_data = cross_tab_data.stack(level=1) barplot = stacked_data.plot.bar() # use the created sample crosstab data to # convert it to a stacked dataframe with # level 2 stacked_data = cross_tab_data.stack(level=2) barplot = stacked_data.plot.bar()
Producción:
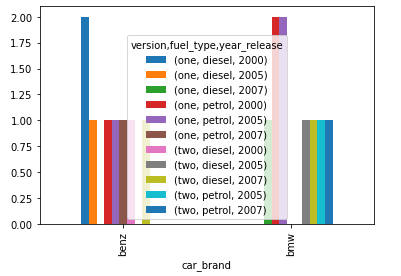
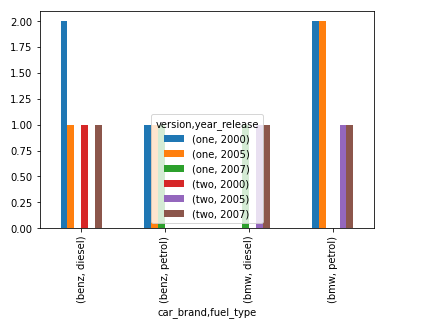
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA