La duplicación de columnas generalmente ocurre cuando los dos marcos de datos tienen columnas con el mismo nombre y cuando las columnas no se usan en la instrucción JOIN. En este artículo, analicemos los tres métodos diferentes en los que podemos evitar la duplicación de columnas al unir dos marcos de datos.
Sintaxis:
pandas.merge(left, right, how=’inner’, on=Ninguno, left_on=Ninguno, right_on=Ninguno)
Explicación:
- izquierda : marco de datos que debe unirse desde la izquierda
- derecha : marco de datos que debe unirse desde la derecha
- cómo : especifica el tipo de combinación. izquierda, derecha, exterior, interior, cruz
- on : nombres de columna para unir los dos marcos de datos.
- left_on : nombres de columna para unirse en el DataFrame izquierdo.
- right_on : nombres de columna para unirse en el DataFrame derecho.
Normalmente fusionar:
Cuando unimos un conjunto de datos usando la función pd.merge() con el tipo ‘interior’, la salida tendrá un prefijo y un sufijo adjuntos a las columnas idénticas en dos marcos de datos, como se muestra en la salida.
Python3
# import python pandas package import pandas as pd # import the numpy package import numpy as np # Create sample dataframe data1 and data2 data1 = pd.DataFrame(np.random.randint(1000, size=(1000, 3)), columns=['EMI', 'Salary', 'Debt']) data2 = pd.DataFrame(np.random.randint(1000, size=(1000, 3)), columns=['Salary', 'Debt', 'Bonus']) # Merge the DataFrames merged = pd.merge(data1, data2, how='inner', left_index=True, right_index=True) print(merged)
Producción:
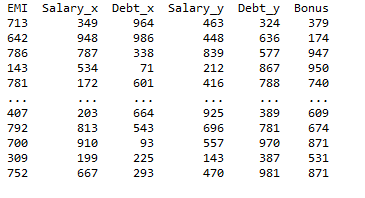
Método 1: use las columnas que tienen los mismos nombres en la declaración de combinación
En este enfoque para evitar que las columnas duplicadas se unan a los dos marcos de datos, el usuario simplemente necesita usar la función pd.merge() y pasar sus parámetros a medida que se unen usando la unión interna y los nombres de las columnas que se van a unir. de los marcos de datos izquierdo y derecho en python.
Ejemplo:
En este ejemplo, primero creamos un marco de datos de muestra data1 y data2 usando la función pd.DataFrame como se muestra y luego usando la función pd.merge() para unir los dos marcos de datos mediante unión interna y mencionar explícitamente los nombres de las columnas que se van a se unió desde los marcos de datos izquierdo y derecho.
Python3
# import python pandas package import pandas as pd # import the numpy package import numpy as np # Create sample dataframe data1 and data2 data1 = pd.DataFrame(np.random.randint(100, size=(1000, 3)), columns=['EMI', 'Salary', 'Debt']) data2 = pd.DataFrame(np.random.randint(100, size=(1000, 3)), columns=['Salary', 'Debt', 'Bonus']) # Merge the DataFrames merged = pd.merge(data1, data2, how='inner', left_on=['Salary', 'Debt'], right_on=['Salary', 'Debt']) print(merged)
Producción:
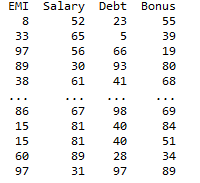
Método 2: Evitar duplicados mencionando nombres de sufijos explícitos para columnas
En este método para evitar la duplicación al unir las columnas de los dos marcos de datos diferentes, el usuario debe usar la función pd.merge() que es responsable de unir las columnas del marco de datos, y luego el usuario debe llamar la función drop() con la condición requerida pasada como parámetro, como se muestra a continuación, para eliminar todos los duplicados del marco de datos final.
función soltar():
Esta función se usa para eliminar etiquetas específicas de filas o columnas.
Sintaxis:
DataFrame.drop(self, etiquetas=Ninguno, eje=0, índice=Ninguno, columnas=Ninguno, nivel=Ninguno, en el lugar=Falso, errores=’aumentar’)
Parámetros:
- etiquetas: Índice o etiquetas de columna para soltar.
- eje: Ya sea para eliminar etiquetas del índice (0 o ‘índice’) o columnas (1 o ‘columnas’). {0 o ‘índice’, 1 o ‘columnas’}
- índice: Alternativa a especificar eje (etiquetas, eje=0 es equivalente a índice=etiquetas).
- columnas: Alternativa a especificar eje (etiquetas, eje=1 es equivalente a columnas=etiquetas).
- level: para MultiIndex, el nivel del que se eliminarán las etiquetas.
- en el lugar: si es verdadero, realice la operación en el lugar y devuelva Ninguno.
- errores: si se ‘ignora’, se suprime el error y solo se eliminan las etiquetas existentes.
Ejemplo:
En este ejemplo, estamos usando la función pd.merge() para unir los dos marcos de datos mediante unión interna. Ahora, agregue un sufijo llamado ‘eliminar’ para las columnas recién unidas que tienen el mismo nombre en ambos marcos de datos. Utilice la función drop() para eliminar las columnas con el sufijo ‘eliminar’. Esto asegurará que no existan columnas idénticas en el nuevo marco de datos.
Python3
# import python pandas package
import pandas as pd
# import the numpy package
import numpy as np
# Create sample dataframe data1 and data2
data1 = pd.DataFrame(np.random.randint(100, size=(1000, 3)),
columns=['EMI', 'Salary', 'Debt'])
data2 = pd.DataFrame(np.random.randint(100, size=(1000, 3)),
columns=['Salary', 'Debt', 'Bonus'])
# Merge the DataFrames
df_merged = pd.merge(data1, data2, how='inner', left_index=True,
right_index=True, suffixes=('', '_remove'))
# remove the duplicate columns
df_merged.drop([i for i in df_merged.columns if 'remove' in i],
axis=1, inplace=True)
print(merged)
Producción:
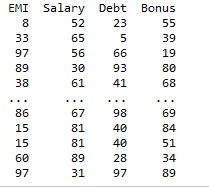
Método 3: elimine las columnas duplicadas antes de fusionar dos columnas
En este método, el usuario necesita llamar a la función merge() que simplemente unirá las columnas del marco de datos y luego el usuario necesita llamar a la función difference() para eliminar las columnas idénticas de ambos marcos de datos y conservar el únicos en el lenguaje python.
Función de diferencia:
Esta función devuelve un conjunto que contiene la diferencia entre dos conjuntos.
Sintaxis:
set.difference(set)
Parámetros:
- conjunto: El conjunto para verificar las diferencias en
Ejemplo:
En este ejemplo. estamos utilizando la función de diferencia para eliminar las columnas idénticas de los marcos de datos dados y almacenar aún más el marco de datos con la columna única como un nuevo marco de datos. Ahora, use la función pd.merge() para unir el marco de datos izquierdo con el marco de datos de la columna única usando la unión ‘interna’. Esto garantizará que no se dupliquen columnas en el conjunto de datos fusionado.
Python3
# import python pandas package import pandas as pd # import the numpy package import numpy as np # Create sample dataframe data1 and data2 data1 = pd.DataFrame(np.random.randint(100, size=(1000, 3)), columns=['EMI', 'Salary', 'Debt']) data2 = pd.DataFrame(np.random.randint(100, size=(1000, 3)), columns=['Salary', 'Debt', 'Bonus']) # Find the columns that aren't in the first DataFrame different_cols = data2.columns.difference(data1.columns) # Filter out the columns that are different. # You could pass in the df2[diff_cols] # directly into the merge as well. data3 = data2[diff_cols] # Merge the DataFrames df_merged = pd.merge(data1, data3, left_index=True, right_index=True, how='inner')
Producción:
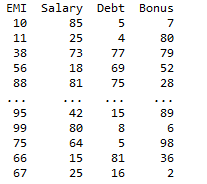
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA