En este artículo, veremos cómo exportar diferentes DataFrames a diferentes hojas de Excel usando python.
Pandas proporciona una función llamada xlsxwriter para este propósito. ExcelWriter() es una clase que le permite escribir objetos DataFrame en hojas de Microsoft Excel. El texto, los números, las strings y las fórmulas se pueden escribir con ExcelWriter(). También se puede utilizar en varias hojas de trabajo.
Sintaxis:
pandas.ExcelWriter(ruta, formato_fecha=Ninguno, modo=’w’)
Parámetro:
- ruta: (str) Ruta al archivo xls o xlsx o ods.
- date_format: string de formato para fechas escritas en archivos de Excel (por ejemplo, ‘YYYY-MM-DD’). str, predeterminado Ninguno
- modo: {‘w’, ‘a’}, predeterminado ‘w’. Modo de archivo a usar (escribir o agregar). Append no funciona con direcciones URL de fsspec.
El método to_excel() se usa para exportar el DataFrame al archivo de Excel. Para escribir un solo objeto en el archivo de Excel, debemos especificar el nombre del archivo de destino. Si queremos escribir en varias hojas, debemos crear un objeto ExcelWriter con el nombre de archivo de destino y también debemos especificar la hoja en el archivo en el que tenemos que escribir. Las hojas múltiples también se pueden escribir especificando el único sheet_name. Es necesario guardar los cambios para todos los datos escritos en el archivo.
Sintaxis:
DataFrame.to_excel(excel_writer, sheet_name=’Sheet1′,index=True)
Parámetro:
- excel_writer: objeto similar a una ruta, similar a un archivo o ExcelWriter (nuevo o existente)
- sheet_name: (str, por defecto ‘Hoja1’). Nombre de la hoja que contendrá DataFrame.
- índice: (bool, por defecto True). Escriba los nombres de las filas (índice).
Cree algunos marcos de datos de muestra usando la función pandas.DataFrame . Ahora, cree una variable de escritor y especifique la ruta en la que desea almacenar el archivo de Excel y el nombre del archivo , dentro de la función excelwriter de pandas .
Ejemplo: escriba el marco de datos de Pandas en varias hojas de Excel
Python3
# import the python pandas package
import pandas as pd
# create data_frame1 by creating a dictionary
# in which values are stored as list
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
# create data_frame2 by creating a dictionary
# in which values are stored as list
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
# create data_frame3 by creating a dictionary
# in which values are stored as list
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
print(data_frame1)
print(data_frame2)
print(data_frame3)
# create a excel writer object
with pd.ExcelWriter("path to file\filename.xlsx") as writer:
# use to_excel function and specify the sheet_name and index
# to store the dataframe in specified sheet
data_frame1.to_excel(writer, sheet_name="Fruits", index=False)
data_frame2.to_excel(writer, sheet_name="Vegetables", index=False)
data_frame3.to_excel(writer, sheet_name="Baked Items", index=False)
Producción:

La salida que muestra el archivo de Excel con diferentes hojas se guardó en la ubicación especificada .

Ejemplo 2: A continuación se muestra otro método para almacenar el marco de datos en un archivo de Excel existente usando excelwriter ,
Cree marcos de datos y agréguelos al archivo de Excel existente que se muestra arriba usando mode= ‘a’ (que significa agregar ) en la función excelwriter. El uso del modo ‘a’ agregará la nueva hoja como la última hoja en el archivo de Excel existente.
Python3
# import the python pandas package
import pandas as pd
# create data_frame1 by creating a dictionary
# in which values are stored as list
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
# create data_frame2 by creating a dictionary
# in which values are stored as list
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
# create data_frame3 by creating a dictionary
# in which values are stored as list
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
# create data_frame3 by creating a dictionary
# in which values are stored as list
data_frame4 = pd.DataFrame({'Cool drinks': ['Pepsi', 'Coca-cola', 'Fanta',
'Miranda', '7up', 'Sprite'],
'Sales in count': [1209, 1230, 1359, 3310, 2150, 1402]})
# create a excel writer object as shown using
# Excelwriter function
with pd.ExcelWriter("path_to_file.xlsx", mode="a", engine="openpyxl") as writer:
# use to_excel function and specify the sheet_name and index to
# store the dataframe in specified sheet
data_frame4.to_excel(writer, sheet_name="Cool drinks")
Producción:

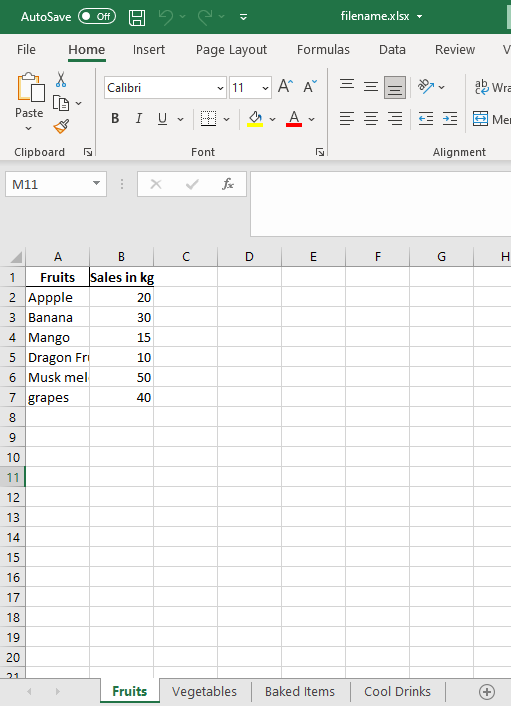
Escribiendo Large Pandas DataFrame en un archivo de Excel en un formato comprimido.
Si el marco de datos de salida es grande , también puede almacenar el archivo de Excel como un archivo comprimido . Guardemos el marco de datos que creamos para este ejemplo. como excel y guárdelo como un archivo zip. El formato de archivo ZIP es un estándar común de archivo y compresión.
Sintaxis:
ZipFile(archivo, modo=’r’)
Parámetro:
- archivo: el archivo puede ser una ruta a un archivo (una string), un objeto similar a un archivo o un objeto similar a una ruta.
- modo: el parámetro de modo debe ser ‘r’ para leer un archivo existente, ‘w’ para truncar y escribir un archivo nuevo, ‘a’ para agregar a un archivo existente o ‘x’ para crear y escribir exclusivamente un archivo nuevo.
Importe el paquete zipfile y cree marcos de datos de muestra. Ahora, especifique la ruta en la que se debe almacenar el archivo zip. Esto crea un archivo zip en la ruta especificada. Cree un nombre de archivo en el que se debe almacenar el archivo de Excel. Use la función to_excel() y especifique el nombre de la hoja y el índice para almacenar el marco de datos en varias hojas
Ejemplo: escribir grandes marcos de datos en formato ZIP
Python3
# import zipfile package
import zipfile
# import the python pandas package
import pandas as pd
# create data_frame1 by creating a dictionary
# in which values are stored as list
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
# create data_frame2 by creating a dictionary
# in which values are stored as list
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
# create data_frame3 by creating a dictionary
# in which values are stored as list
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
# create data_frame3 by creating a dictionary
# in which values are stored as list
data_frame4 = pd.DataFrame({'Cool drinks': ['Pepsi', 'Coca-cola', 'Fanta',
'Miranda', '7up', 'Sprite'],
'Sales in count': [1209, 1230, 1359, 3310, 2150, 1402]})
# specify the path in which the zip file has to be stored
with zipfile.ZipFile("path_to_file.zip", "w") as zf:
# in open function specify the name in which
# the excel file has to be stored
with zf.open("filename.xlsx", "w") as buffer:
with pd.ExcelWriter(buffer) as writer:
# use to_excel function and specify the sheet_name and
# index to store the dataframe in specified sheet
data_frame1.to_excel(writer, sheet_name="Fruits", index=False)
data_frame2.to_excel(writer, sheet_name="Vegetables", index=False)
data_frame3.to_excel(writer, sheet_name="Baked Items", index=False)
data_frame4.to_excel(writer, sheet_name="Cool Drinks", index=False)
Producción:
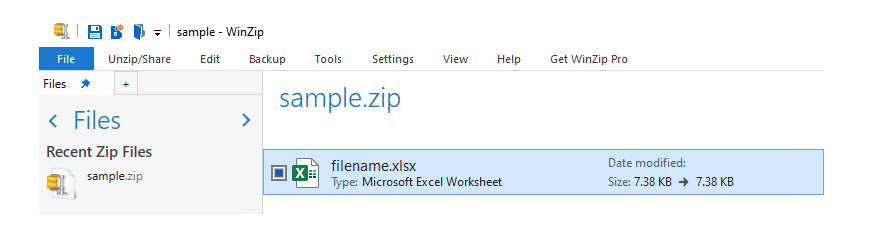
Salida de muestra de un archivo de Excel comprimido
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA