Una operación groupby implica agrupar grandes cantidades de datos y operaciones informáticas en estos grupos. Generalmente está involucrado en alguna combinación de dividir el objeto, aplicar una función y combinar los resultados. En este artículo, veamos cómo obtener el recuento del último valor en el grupo usando pandas.
Sintaxis:
DataFrame.groupby(by, axis, as_index)
Parámetros:
- por (lista de tipos de datos, tuplas, dict, serie, array): mapeo, función, etiqueta o lista de etiquetas. La función pasada se usa tal cual para determinar los grupos.
- eje (tipo de datos int, predeterminado 0): 1: divide columnas y 0: divide filas.
- as_index (tipo de datos bool, predeterminado True.): Devuelve un objeto con etiquetas de grupo como índice, para toda la salida agregada,
Método 1: Usar la función GroupBy & Aggregate
En este enfoque, el usuario debe llamar a la función DataFrame.groupby() para demostrar cómo obtener el recuento del último valor en el grupo usando pandas en el lenguaje python.
Ejemplo:
En este ejemplo, creamos un marco de datos de muestra con los nombres y precios de los autos como se muestra y aplicamos la función groupby en los autos, establecer as_index falso no crea un nuevo índice y luego agregamos la función agrupada por el último precio de los autos usando el ‘último’ parámetro en la función agregada y nombre la columna ‘Price_last’. Seguido de eso, agregue otra función lambda para obtener la cantidad de veces que el automóvil obtuvo el último precio.
El marco de datos utilizado en el siguiente ejemplo:
cars Price_in_million 0 benz 15 1 benz 12 2 benz 23 3 benz 23 4 bmw 63 5 bmw 34 6 bmw 63
Python3
# import python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23,
63, 34, 63]})
# use groupby function to groupby cars, setting
# as_index false doesnt create an index.
# use aggregate function with 'last; parameter
# to get the last price im the group of cars.
# apply lambda function to get the number of
# times the car got the last price.
data.groupby('cars', as_index=False).agg(Price_last=('Price_in_million', 'last'),
Price_last_count=('Price_in_million',
lambda x: sum(x == x.iloc[-1])))
Producción:
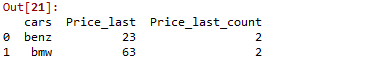
Método 2: Uso de la función Lambda
En este método, el usuario debe llamar a la función lambda utilizada anteriormente para devolver el recuento de las filas correspondientes presentes en el marco de datos en el lenguaje de programación R.
Ejemplo:
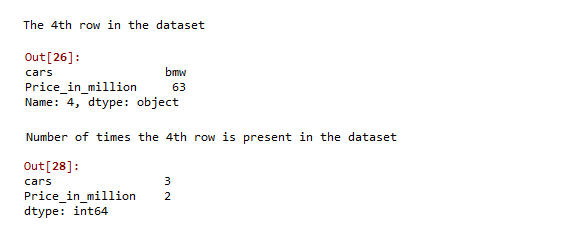
En este ejemplo, como puede ver, el automóvil: BMW y el precio 63 corresponde a la cuarta fila del conjunto de datos. Al aplicar la función lambda como se indicó anteriormente, se obtiene que el automóvil BMW está presente tres veces y el precio 63 está presente 2 veces.
Python3
# import python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# get the 4th row present in the data
data.iloc[4]
# Now apply lambda function to get the number
# of times the row is present in the dataset
data.apply(lambda x: sum(x==x.iloc[4]))
Producción:
Método 3: Usando GroupBy, pandas Merge & Aggregate función
El conteo del último valor en el grupo que usa pandas también se puede obtener usando la función de combinación de pandas de la siguiente manera.
Sintaxis:
DataFrame.merge(right, how='inner', on=None)
Parámetros:
- derecha : objeto con el que fusionarse. (trama de datos u objeto de serie).
- cómo : combinación izquierda, combinación derecha, combinación externa, Predeterminado: combinación interna
- on – (etiqueta o lista). Especifique los nombres de columna para unirse.
Ejemplo:
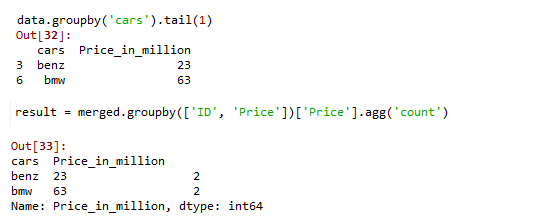
En este ejemplo, creamos un marco de datos de muestra con los nombres y precios de los autos como se muestra y aplicamos la función groupby en los autos, y usamos la función tail() para calcular el valor final del grupo. Ahora, realice una combinación interna con el conjunto de datos agrupados y el conjunto de datos original. Finalmente, aplique una función groupby agregada de conteo para obtener el no. de ocurrencias del último valor.
Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# perform inner merge with the grouped and original dataset
merged = pd.merge(data.groupby('cars').tail(1), data, how='inner')
# apply a count aggregated groupby function to
# get the no. of. occurrences of last value.
result = merged.groupby(['cars', 'Price_in_million'])[
'Price_in_million'].agg('count')
print(result)
Producción:
Método 4: usar la función GroupBy, pandas Merge y Sum
También podemos obtener el mismo resultado alterando ligeramente el enfoque anterior, usando la función last() en lugar de tail() , como se muestra a continuación,
Ejemplo:
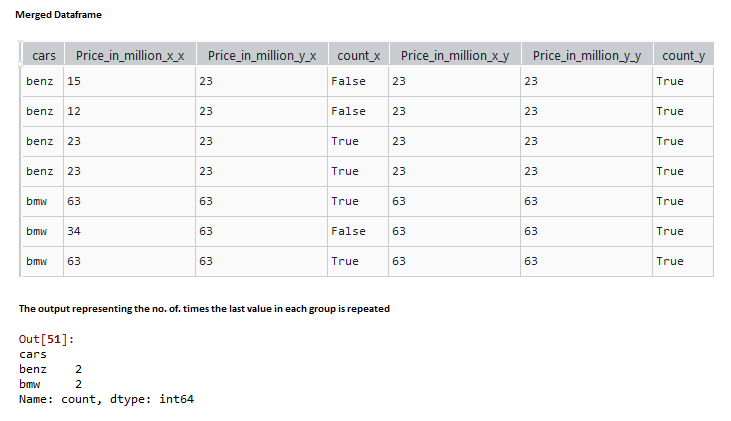
En este ejemplo, creamos un marco de datos de muestra con los nombres y precios de los autos como se muestra, aplicamos la función groupby en los autos y usamos la función last() para encontrar el elemento final de cada grupo y combinar internamente el conjunto de datos agrupados con el conjunto de datos original. Ahora compare los dos precios en las columnas fusionadas y cree una nueva columna de tipo de datos bool, donde los precios coincidan. Ahora use la función groupby para obtener el número de veces que se repite el último valor del grupo.
Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# computes the final value of each group
grouped = data.groupby('cars').last()
# Merge dataset named "data" with this result
data = data.merge(grouped, left_on='cars', right_index=True, how='inner')
# Now compare the merged columns for same price
# and create a new column of boolean values
# where prices match
data['count'] = data['Price_in_million_x'] == data['Price_in_million_y']
# Use groupby function to return the aggregated
# sum of count column where the price matches
data.groupby('cars')['count'].sum()
Producción:
Publicación traducida automáticamente
Artículo escrito por jssuriyakumar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA