Los datos de series temporales se caracterizan generalmente por su naturaleza temporal. Esta naturaleza temporal agrega una tendencia o estacionalidad a los datos que los hace compatibles para el análisis y pronóstico de series temporales. Se dice que los datos de series temporales son estacionarios si no cambian con el tiempo o si no tienen una estructura temporal. Por lo tanto, es muy necesario verificar si los datos son estacionarios. En el pronóstico de series de tiempo, no podemos obtener información valiosa de los datos si son estacionarios.
Gráfico de ejemplo de datos estacionarios:
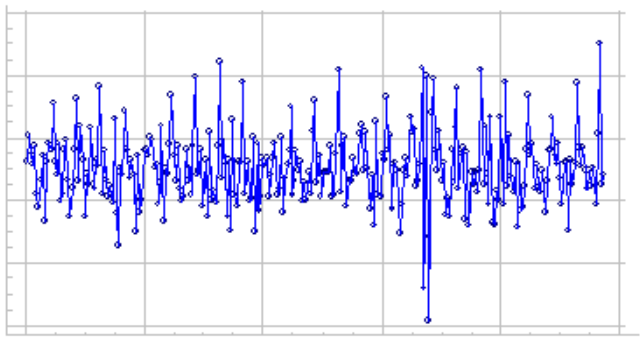
Tipos de estacionariedad:
Cuando se trata de identificar si los datos son estacionarios, significa identificar las nociones detalladas de estacionariedad en los datos. Los tipos de estacionariedad observados en los datos de series de tiempo incluyen
- Tendencia estacionaria: una serie de tiempo que no muestra una tendencia.
- Estacionario Estacional – Una serie de tiempo que no muestra cambios estacionales.
- Estrictamente estacionario: la distribución conjunta de las observaciones es invariable al cambio de tiempo.
Implementación paso a paso
Los siguientes pasos le permitirán al usuario comprender fácilmente el método para verificar que los datos de la serie de tiempo dados sean estacionarios.
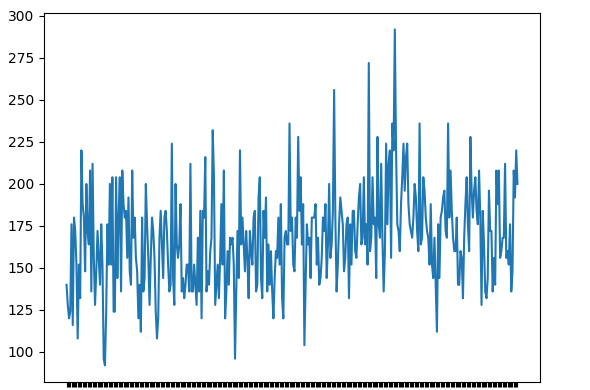
Paso 1: Trazar los datos de la serie temporal
Haga clic aquí para descargar el conjunto de datos de práctica daily-female-births-IN.csv.
Python3
# import python pandas library
import pandas as pd
# import python matplotlib library for plotting
import matplotlib.pyplot as plt
# read the dataset using pandas read_csv()
# function
data = pd.read_csv("daily-total-female-births-IN.csv",
header=0, index_col=0)
# use simple line plot to see the distribution
# of the data
plt.plot(data)
Producción:
Paso 2: Evaluación de las estadísticas descriptivas
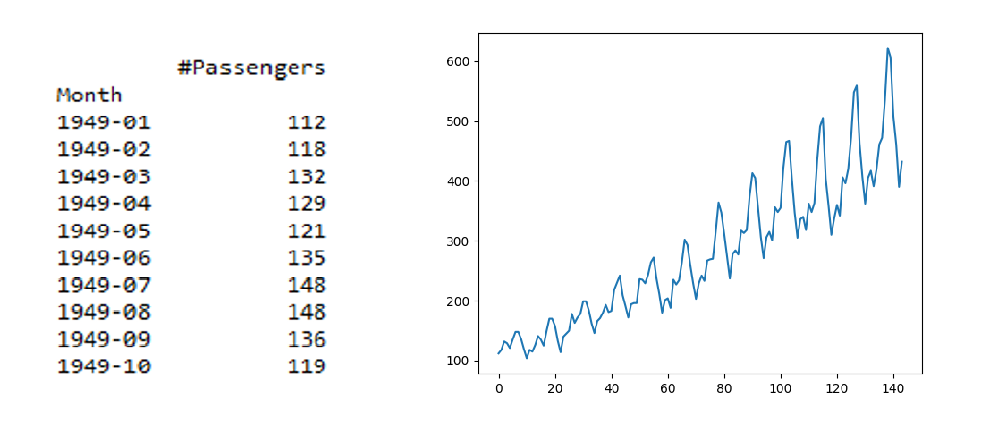
Esto generalmente se hace dividiendo los datos en dos o más particiones y calculando la media y la varianza para cada grupo. Si estos momentos de primer orden son consistentes entre estas particiones, entonces podemos asumir que los datos son estacionarios. Usemos el conjunto de datos de conteo de pasajeros de las aerolíneas entre 1949 y 1960.
Haga clic aquí para descargar el conjunto de datos de práctica AirPassengers.csv.
Python3
# import python pandas library
import pandas as pd
# import python matplotlib library for
# plotting
import matplotlib.pyplot as plt
# read the dataset using pandas read_csv()
# function
data = pd.read_csv("AirPassengers.csv",
header=0, index_col=0)
# print the first 6 rows of data
print(data.head(10))
# use simple line plot to understand the
# data distribution
plt.plot(data)
Producción:
Ahora, dividamos estos datos en diferentes grupos y calculemos la media y la varianza de diferentes grupos y verifiquemos la consistencia.
Python3
# import the python pandas library
import pandas as pd
# use pandas read_csv() function to read the dataset.
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
# extracting only the air passengers count from
# the dataset using values function
values = data.values
# getting the count to split the dataset into 3
parts = int(len(values)/3)
# splitting the data into three parts
part_1, part_2, part_3 = values[0:parts], values[parts:(
parts*2)], values[(parts*2):(parts*3)]
# calculating the mean of the separated three
# parts of data individually.
mean_1, mean_2, mean_3 = part_1.mean(), part_2.mean(), part_3.mean()
# calculating the variance of the separated
# three parts of data individually.
var_1, var_2, var_3 = part_1.var(), part_2.var(), part_3.var()
# printing the mean of three groups
print('mean1=%f, mean2=%f, mean2=%f' % (mean_1, mean_2, mean_3))
# printing the variance of three groups
print('variance1=%f, variance2=%f, variance2=%f' % (var_1, var_2, var_3))
Producción:

El resultado implica claramente que la media y la varianza de los tres grupos son considerablemente diferentes entre sí, lo que describe que los datos no son estacionarios. Digamos, por ejemplo, si las medias donde media_1 = 150, media_2 = 160, media_3 = 155 y varianza_1 = 33, varianza_2 = 35, varianza_3 = 37, entonces podemos concluir que los datos son estacionarios. A veces, este método puede fallar para algunas distribuciones, como las distribuciones log-norm.
Probemos el mismo ejemplo anterior, pero tomemos el registro del conteo de pasajeros usando la función log() de NumPy y verifiquemos los resultados.
Python3
# import python pandas library
import pandas as pd
# import python matplotlib library for plotting
import matplotlib.pyplot as plt
# import python numpy library
import numpy as np
# read the dataset using pandas read_csv()
# function
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
# extracting only the air passengers count
# from the dataset using values function
values = log(data.values)
# printing the first 15 passenger count values
print(values[0:15])
# using simple line plot to understand the
# data distribution
plt.plot(values)
Producción:
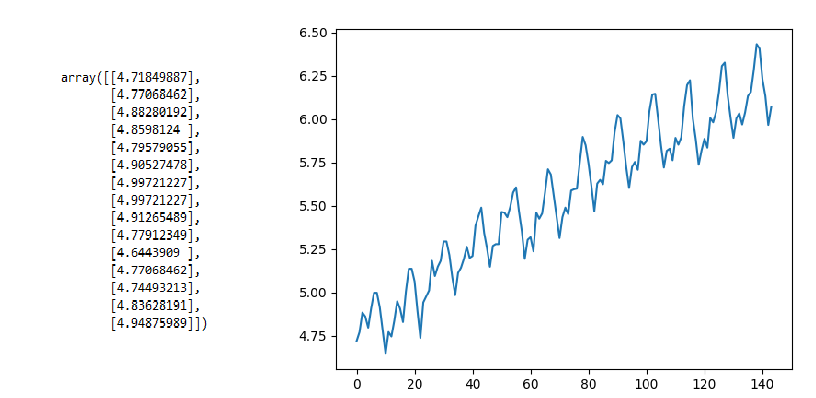
La salida significa que hay alguna tendencia pero no muy pronunciada como en el caso anterior, ahora calculemos la media y la varianza de la partición.
Python3
# getting the count to split the dataset
# into 3 parts
parts = int(len(values)/3)
# splitting the data into three parts.
part_1, part_2, part_3 = values[0:parts], values[parts:(parts*2)], values[(parts*2):(parts*3)]
# calculating the mean of the separated three
# parts of data individually.
mean_1, mean_2, mean_3 = part_1.mean(), part_2.mean(), part_3.mean()
# calculating the variance of the separated three
# parts of data individually.
var_1, var_2, var_3 = part_1.var(), part_2.var(), part_3.var()
# printing the mean of three groups
print('mean1=%f, mean2=%f, mean2=%f' % (mean_1, mean_2, mean_3))
# printing the variance of three groups
print('variance1=%f, variance2=%f, variance2=%f' % (var_1, var_2, var_3))
Producción:
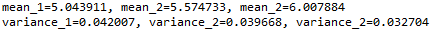
Idealmente, habríamos esperado que la media y la varianza fueran muy diferentes, pero son lo mismo, en tales casos, este método puede fallar terriblemente. Para evitar esto, tenemos otra prueba estadística que se analiza a continuación.
Paso 3: prueba de Dickey-Fuller aumentada
Esta es una prueba estadística que está diseñada específicamente para probar si los datos de series temporales univariadas son estacionarios o no. Esta prueba se basa en una hipótesis y puede decirnos el grado de probabilidad con el que se puede aceptar. A menudo se clasifica bajo una de las pruebas de raíz unitaria. Determina con qué fuerza, los datos de una serie temporal univariante siguen una tendencia. Definamos las hipótesis nula y alterna,
- Ho (hipótesis nula): los datos de la serie temporal no son estacionarios
- H1 (hipótesis alternativa): los datos de la serie temporal son estacionarios
Asuma alfa = 0.05, es decir (95% de confianza). Los resultados de la prueba se interpretan con un valor p si p > 0,05 no se rechaza la hipótesis nula, de lo contrario, si p <= 0,05 se rechaza la hipótesis nula. Ahora, usemos el mismo conjunto de datos de pasajeros aéreos y probémoslo usando la función estadística adfuller() proporcionada por el paquete del modelo de estadísticas, para verificar si los datos son estacionarios o no.
Python3
# import python pandas package
import pandas as pd
# import the adfuller function from statsmodel
# package to perform ADF test
from statsmodels.tsa.stattools import adfuller
# read the dataset using pandas read_csv() function
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
# extracting only the passengers count using values function
values = data.values
# passing the extracted passengers count to adfuller function.
# result of adfuller function is stored in a res variable
res = adfuller(values)
# Printing the statistical result of the adfuller test
print('Augmneted Dickey_fuller Statistic: %f' % res[0])
print('p-value: %f' % res[1])
# printing the critical values at different alpha levels.
print('critical values at different levels:')
for k, v in res[4].items():
print('\t%s: %.3f' % (k, v))
Producción:
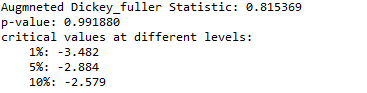
Según nuestra hipótesis, la estadística ADF es mucho mayor que los valores críticos en diferentes niveles, y también el valor p también es mayor que 0.05, lo que significa que podemos fallar al rechazar la hipótesis nula al 90%, 95% y 99 % de confianza, lo que significa que los datos de la serie temporal son fuertemente no estacionarios.
Ahora, intentemos ejecutar la prueba ADF en los valores normalizados de registro y cotejemos nuestros resultados.
Python3
# import python pandas package
import pandas as pd
# import the adfuller function from statsmodel
# package to perform ADF test
from statsmodels.tsa.stattools import adfuller
# import python numpy package
import numpy as np
# read the dataset using pandas read_csv() function
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
# extracting only the passengers count using
# values function and applying log transform on it.
values = log(data.values)
# passing the extracted passengers count to adfuller function.
# result of adfuller function is stored in a res variable
res = adfuller(values)
# Printing the statistical result of the adfuller test
print('Augmneted Dickey_fuller Statistic: %f' % res[0])
print('p-value: %f' % res[1])
# printing the critical values at different alpha levels.
print('critical values at different levels:')
for k, v in res[4].items():
print('\t%s: %.3f' % (k, v))
Producción:

Como puede ver, la prueba ADF muestra una vez más que la estadística ADF es mucho mayor que los valores críticos en diferentes niveles, y también el valor p es mucho mayor que 0.05, lo que significa que podemos fallar al rechazar la hipótesis nula en 90%, 95% y 99% de confianza, lo que significa que los datos de la serie temporal son fuertemente no estacionarios.
Por lo tanto, la prueba de raíz unitaria ADF se destaca como una prueba sólida para verificar si los datos de una serie de tiempo son estacionarios o no.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA