Quizá te interese leer primero: ¡Cómo funciona la Búsqueda de Google!
Ahora echemos un vistazo a alguna terminología importante:
Motor de búsqueda: un programa que busca e identifica elementos en una base de datos que corresponde a palabras clave o caracteres especificados por el usuario, usado especialmente para encontrar sitios particulares en la World Wide Web.
Ejemplo: motor de búsqueda de Google, Yahoo, Bing, etc.
Índice del motor de búsqueda: un índice del motor de búsqueda es una base de datos que correlaciona palabras clave y sitios web para que el motor de búsqueda pueda mostrar sitios web que coincidan con la consulta de búsqueda de un usuario.
Por ejemplo, si un usuario busca la velocidad de carrera de Cheetah, la araña de software busca estos términos en el índice del motor de búsqueda.
Rastreador web: lo primero que debe comprender es qué es un rastreador web o una araña y cómo funciona. Una araña de motor de búsqueda (también conocida como rastreador, robot, robot de búsqueda o simplemente bot) es un programa que la mayoría de los motores de búsqueda utilizan para encontrar las novedades en Internet. El rastreador web de Google se conoce como GoogleBot. El programa comienza en un sitio web y sigue cada hipervínculo en cada página.
Por lo tanto, se puede decir que todo en la web finalmente se encontrará y rastreará, ya que la llamada «araña» se arrastra de un sitio web a otro. Cuando un rastreador web visita una de sus páginas, carga el contenido del sitio en una base de datos. Una vez que se ha obtenido una página, el texto de su página se carga en el índice del motor de búsqueda, que es una base de datos masiva de palabras y dónde aparecen en diferentes páginas web.
Archivo Robots.txt: los rastreadores web rastrean algunos sitios web sin aprobación. Por lo tanto, cada sitio web incluye un archivo robots.txt que contiene instrucciones para la araña (rastreador web) sobre qué partes del sitio web indexar y qué partes ignorar.
Algoritmo PageRank
PageRank funciona contando el número y la calidad de los enlaces a una página para determinar una estimación aproximada de la importancia de la página web. Cuando un rastreador web pasa por cada sitio web, sigue todos los enlaces en el sitio web y verifica cuántos enlaces están conectados a cada sitio. Y luego asigna un porcentaje a cada página web que representa la importancia de la página web utilizando el algoritmo de rango de página. Por ejemplo, si hay tres páginas web llamadas A, B y C. Supongamos que el número de enlaces que conectan a B son de cinco páginas web que tienen menos porcentaje y la página C tiene el enlace de A que tiene mayor porcentaje, ya que el El enlace a C proviene de una página importante y, por lo tanto, a C se le asigna un valor más alto que a B.
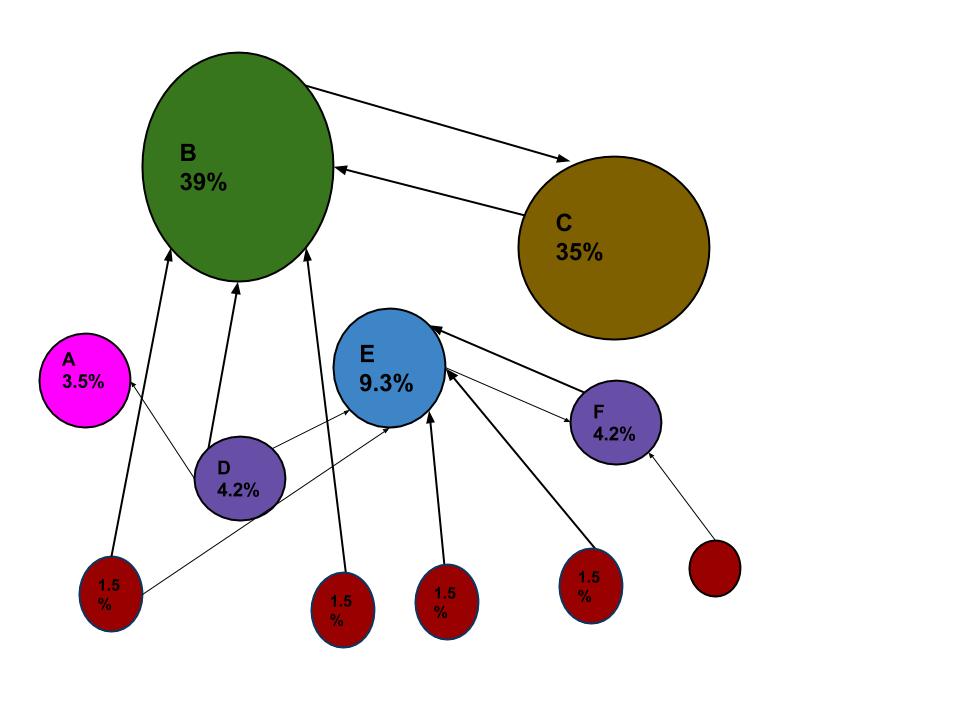
The above image is adapted from Wikipedia.
{kind=link}
PageRank en el gráfico de URL es una distribución de probabilidad utilizada para representar la probabilidad de que una persona que hace clic aleatoriamente en los enlaces llegue a una página en particular.
Básicamente, hay tres pasos que están involucrados en el procedimiento de rastreo web. Primero, el robot de búsqueda comienza rastreando las páginas de su sitio. Luego continúa indexando las palabras y el contenido del sitio, y finalmente visita los enlaces (direcciones de páginas web o URL) que se encuentran en su sitio.
Importancia de “robots.txt”
Lo primero que se supone que debe hacer una araña cuando visita su sitio web es buscar un archivo llamado «robots.txt». Este archivo contiene instrucciones para la araña sobre qué partes del sitio web indexar y qué partes ignorar. La única manera de controlar lo que ve una araña en su sitio es usando un archivo robots.txt. Se supone que todas las arañas siguen algunas reglas, y los principales motores de búsqueda siguen estas reglas en su mayor parte. Afortunadamente, los principales motores de búsqueda como Google o Bing finalmente están trabajando juntos en los estándares.
Cuando realiza una búsqueda, la araña busca en el índice para encontrar todas las páginas que incluyen esos términos de búsqueda. En este caso, encuentra cientos o miles de páginas y Google decide qué pocos documentos son realmente buscados haciendo preguntas a más de 200 de ellos como:
- ¿Cuántas veces la página contiene esta palabra clave?
- ¿Aparecen las palabras en el título, en la URL, directamente adyacentes?
- ¿La página incluye sinónimos para estas palabras?
- ¿Es esta página un sitio web de calidad o de baja calidad?
Y luego obtiene cientos de páginas web y clasifica la importancia de las páginas web mediante el uso del algoritmo PageRank que analiza cuántos enlaces externos apuntan a él y qué tan importantes son esos enlaces. Finalmente, combina todos esos factores para producir la puntuación general de cada página y devolver los resultados de la búsqueda en aproximadamente medio segundo después de enviar la búsqueda.
Cada página incluye el título, URL, fragmento de texto para decidir cuál es la página en particular que estamos buscando. Y si no es relevante, también muestra búsquedas relacionadas en la parte inferior de la página.
Artículos relacionados:
- Cómo muestran los anuncios de Facebook para algo que buscaste
- Optimización de motores de búsqueda (SEO) | Lo esencial
- Cómo se actualiza Google
Links importantes :
Este artículo es una contribución de Brahmani Sai . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo usando contribuya.geeksforgeeks.org o envíe su artículo por correo a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA