Supongamos que desea obtener información de un sitio web. Digamos un artículo del sitio web geeksforgeeks o algún artículo de noticias, ¿qué harás? Lo primero que se te puede ocurrir es copiar y pegar la información en tus medios locales. Pero, ¿qué sucede si desea una gran cantidad de datos diariamente y lo más rápido posible? En tales situaciones, copiar y pegar no funcionará y ahí es donde necesitará web scraping.
En este artículo, discutiremos cómo realizar web scraping usando la biblioteca de requests y la biblioteca beautifulsoup en Python.
Módulo de Requests
La biblioteca de requests se utiliza para realizar requests HTTP a una URL específica y devuelve la respuesta. Las requests de Python proporcionan funcionalidades integradas para administrar tanto la solicitud como la respuesta.
Instalación
Las requests de instalación dependen del tipo de sistema operativo, el comando básico en cualquier lugar sería abrir una terminal de comando y ejecutar,
pip install requests
Hacer una solicitud
El módulo de requests de Python tiene varios métodos integrados para realizar requests HTTP a un URI específico mediante requests GET, POST, PUT, PATCH o HEAD. Una solicitud HTTP está destinada a recuperar datos de un URI específico o enviar datos a un servidor. Funciona como un protocolo de solicitud-respuesta entre un cliente y un servidor. Aquí usaremos la solicitud GET.
El método GET se usa para recuperar información del servidor dado usando un URI dado. El método GET envía la información de usuario codificada adjunta a la solicitud de página.
Ejemplo: requests de Python que realizan una solicitud GET
Python3
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# print content of request
print(r.content)
Producción:

Objeto de respuesta
Cuando uno realiza una solicitud a un URI, devuelve una respuesta. Este objeto de respuesta en términos de python es devuelto por requestes.method(), siendo el método: obtener, publicar, poner, etc. La respuesta es un objeto poderoso con muchas funciones y atributos que ayudan a normalizar los datos o crear porciones ideales de código. Por ejemplo, response.status_code devuelve el código de estado de los propios encabezados y se puede comprobar si la solicitud se procesó correctamente o no.
Los objetos de respuesta se pueden usar para implicar muchas características, métodos y funcionalidades.
Ejemplo: Python solicita un objeto de respuesta
Python3
import requests
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# print request object
print(r.url)
# print status code
print(r.status_code)
Producción:
https://www.geeksforgeeks.org/python-programming-language/ 200
Para obtener más información, consulte nuestro Tutorial de requests de Python .
Biblioteca BeautifulSoup
BeautifulSoup se utiliza para extraer información de los archivos HTML y XML. Proporciona un árbol de análisis y las funciones para navegar, buscar o modificar este árbol de análisis.
Instalación
Para instalar Beautifulsoup en Windows, Linux o cualquier sistema operativo, se necesitaría el paquete pip. Para verificar cómo instalar pip en su sistema operativo, consulte – Instalación de PIP – Windows || linux Ahora ejecute el siguiente comando en la terminal.
pip install beautifulsoup4
Sitio web de inspección
Antes de sacar cualquier información del HTML de la página, debemos entender la estructura de la página. Esto es necesario para seleccionar los datos deseados de toda la página. Podemos hacer esto haciendo clic derecho en la página que queremos raspar y seleccionando inspeccionar elemento.

Después de hacer clic en el botón de inspección, se abren las herramientas de desarrollo del navegador. Ahora, casi todos los navegadores vienen con las herramientas de desarrollo instaladas, y usaremos Chrome para este tutorial.

Las herramientas del desarrollador permiten ver el Modelo de objetos del documento (DOM) del sitio . Si no conoce DOM, no se preocupe, solo considere el texto que se muestra como la estructura HTML de la página.
Analizando el HTML
Después de obtener el HTML de la página, veamos cómo analizar este código HTML sin procesar para obtener información útil. En primer lugar, crearemos un objeto BeautifulSoup especificando el analizador que queremos usar.
Nota: la biblioteca BeautifulSoup se basa en las bibliotecas de análisis de HTML como html5lib, lxml, html.parser, etc. Por lo tanto, el objeto BeautifulSoup y especificar la biblioteca del analizador se pueden crear al mismo tiempo.
Ejemplo: Python BeautifulSoup analizando HTML
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# check status code for response received
# success code - 200
print(r)
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
Producción:

Esta información todavía no es útil para nosotros, veamos otro ejemplo para hacer una idea clara de esto. Intentemos extraer el título de la página.
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Getting the title tag
print(soup.title)
# Getting the name of the tag
print(soup.title.name)
# Getting the name of parent tag
print(soup.title.parent.name)
# use the child attribute to get
# the name of the child tag
Producción:
<title>Python Programming Language - GeeksforGeeks</title> title html
Encontrar elementos
Ahora, nos gustaría extraer algunos datos útiles del contenido HTML. El objeto de sopa contiene todos los datos en la estructura anidada que podrían extraerse mediante programación. El sitio web que queremos raspar contiene mucho texto, así que ahora vamos a raspar todo ese contenido. Primero, inspeccionemos la página web que queremos raspar.

Encontrar elementos por clase
En la imagen de arriba, podemos ver que todo el contenido de la página está bajo el div con contenido de entrada de clase. Usaremos la clase find. Esta clase encontrará la etiqueta dada con el atributo dado. En nuestro caso, encontrará todos los div que tengan clase como contenido de entrada. Tenemos todo el contenido del sitio, pero puede ver que todas las imágenes y enlaces también se eliminan. Entonces, nuestra próxima tarea es encontrar solo el contenido del HTML analizado anteriormente. Al inspeccionar nuevamente el HTML de nuestro sitio web:
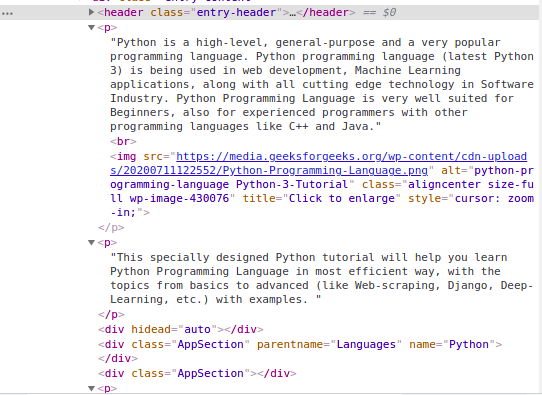
Podemos ver que el contenido de la página está bajo la etiqueta <p>. Ahora tenemos que encontrar todas las etiquetas p presentes en esta clase. Podemos usar la clase find_all de BeautifulSoup.
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
content = s.find_all('p')
print(content)
Producción:

Búsqueda de elementos por ID
En el ejemplo anterior, hemos encontrado los elementos por el nombre de la clase, pero veamos cómo encontrar elementos por id. Ahora, para esta tarea, raspamos el contenido de la barra izquierda de la página. El primer paso es inspeccionar la página y ver la barra izquierda bajo qué etiqueta.

La imagen de arriba muestra que la barra izquierda cae bajo la etiqueta <div> con id como principal. Ahora vamos a obtener el contenido HTML bajo esta etiqueta. Ahora inspeccionemos más de la página para obtener el contenido de la barra izquierda.

Podemos ver que la lista en la barra izquierda está debajo de la etiqueta <ul> con la clase como leftBarList y nuestra tarea es encontrar todos los li debajo de este ul.
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
content = leftbar.find_all('li')
print(content)
Producción:

Extracción de texto de las etiquetas
En los ejemplos anteriores, debe haber visto que al raspar los datos, las etiquetas también se raspan, pero ¿qué sucede si solo queremos el texto sin etiquetas? No se preocupe, discutiremos lo mismo en esta sección. Usaremos la propiedad text. Solo imprime el texto de la etiqueta. Usaremos el ejemplo anterior y eliminaremos todas las etiquetas de ellos.
Ejemplo 1: Eliminar las etiquetas del contenido de la página
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
for line in lines:
print(line.text)
Producción:

Ejemplo 2: Eliminar las etiquetas del contenido de la barra izquierda
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# Finding by id
s = soup.find('div', id= 'main')
# Getting the leftbar
leftbar = s.find('ul', class_='leftBarList')
# All the li under the above ul
lines = leftbar.find_all('li')
for line in lines:
print(line.text)
Producción:

Extracción de enlaces
Hasta ahora hemos visto cómo extraer texto, veamos ahora cómo extraer los enlaces de la página.
Ejemplo: Python BeautifulSoup extrayendo enlaces
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
# find all the anchor tags with "href"
for link in soup.find_all('a'):
print(link.get('href'))
Producción:

Extracción de información de la imagen
Al inspeccionar nuevamente la página, podemos ver que las imágenes se encuentran dentro de la etiqueta img y el enlace de esa imagen está dentro del atributo src. Vea la imagen de abajo –

Ejemplo: Imagen de extracto de Python BeautifulSoup
Python3
import requests
from bs4 import BeautifulSoup
# Making a GET request
r = requests.get('https://www.geeksforgeeks.org/python-programming-language/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
images_list = []
images = soup.select('img')
for image in images:
src = image.get('src')
alt = image.get('alt')
images_list.append({"src": src, "alt": alt})
for image in images_list:
print(image)
Producción:

Raspado de varias páginas
Ahora, pueden surgir varios casos en los que es posible que desee obtener datos de varias páginas del mismo sitio web o también de varias URL diferentes, y escribir código manualmente para cada página web es una tarea tediosa y que requiere mucho tiempo. Además, define todos los principios básicos de la automatización. ¡Eh!
Para resolver este problema exacto, veremos dos técnicas principales que nos ayudarán a extraer datos de múltiples páginas web:
- el mismo sitio web
- Diferente URL del sitio web
Ejemplo 1: recorrer los números de página

números de página en la parte inferior del sitio web GeeksforGeeks
La mayoría de los sitios web tienen páginas etiquetadas del 1 al N. Esto hace que sea realmente sencillo para nosotros recorrer estas páginas y extraer datos de ellas, ya que estas páginas tienen estructuras similares. Por ejemplo:

números de página en la parte inferior del sitio web GeeksforGeeks
Aquí, podemos ver los detalles de la página al final de la URL. Con esta información, podemos crear fácilmente un bucle for iterando en tantas páginas como queramos (colocando página/(i)/ en la string de URL e iterando “i” hasta N) y extrayendo todos los datos útiles de ellas. El siguiente código le dará más claridad sobre cómo raspar datos usando un For Loop en Python.
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/1/'
req = requests.get(URL)
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs = {'class','head'})
print(titles[4].text)
Producción:
7 Most Common Time Wastes During Software Development
Ahora, usando el código anterior, podemos obtener los títulos de todos los artículos simplemente intercalando esas líneas con un bucle.
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = 'https://www.geeksforgeeks.org/page/'
for page in range(1, 10):
req = requests.get(URL + str(page) + '/')
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
for i in range(4, 19):
if page > 1:
print(f"{(i-3)+page*15}" + titles[i].text)
else:
print(f"{i-3}" + titles[i].text)
Producción:

Ejemplo 2: recorrer una lista de diferentes URL
La técnica anterior es absolutamente maravillosa, pero ¿qué sucede si necesita raspar diferentes páginas y no sabe sus números de página? Tendrá que raspar esas diferentes URL una por una y codificar manualmente un script para cada una de esas páginas web.
En su lugar, podría simplemente hacer una lista de estas URL y recorrerlas. Simplemente iterando los elementos de la lista, es decir, las URL, podremos extraer los títulos de esas páginas sin tener que escribir código para cada página. Aquí hay un código de ejemplo de cómo puedes hacerlo.
Python3
import requests
from bs4 import BeautifulSoup as bs
URL = ['https://www.geeksforgeeks.org','https://www.geeksforgeeks.org/page/10/']
for url in range(0,2):
req = requests.get(URL[url])
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div',attrs={'class','head'})
for i in range(4, 19):
if url+1 > 1:
print(f"{(i - 3) + url * 15}" + titles[i].text)
else:
print(f"{i - 3}" + titles[i].text)
Producción:

Para obtener más información, consulte nuestro Tutorial de Python BeautifulSoup .
Guardar datos en CSV
Primero crearemos una lista de diccionarios con los pares clave-valor que queremos agregar en el archivo CSV. Luego usaremos el módulo csv para escribir la salida en el archivo CSV. Vea el siguiente ejemplo para una mejor comprensión.
Ejemplo: Python BeautifulSoup guardando en CSV
Python3
import requests
from bs4 import BeautifulSoup as bs
import csv
URL = 'https://www.geeksforgeeks.org/page/'
soup = bs(req.text, 'html.parser')
titles = soup.find_all('div', attrs={'class', 'head'})
titles_list = []
count = 1
for title in titles:
d = {}
d['Title Number'] = f'Title {count}'
d['Title Name'] = title.text
count += 1
titles_list.append(d)
filename = 'titles.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['Title Number','Title Name'])
w.writeheader()
w.writerows(titles_list)
Producción:

Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA