CosmosDB es una base de datos NoSQL de Azure. En este artículo, analizaremos el escalado horizontal de alto nivel, la replicación, el particionamiento y el esquema de la base de datos. Y luego nos sumergiremos en algunos de los modelos de datos que admite Cosmos DB. Entonces empecemos.
Las aplicaciones solían ser relativamente simples. Tendríamos una aplicación, una capa API y un goteo lento de datos cayendo en nuestra base de datos. Ahora, de vez en cuando, es posible que hayamos necesitado mostrar esos datos y buscar información del dispositivo en un catálogo o buscar una cita en un calendario. Pero a menudo los datos permanecían en la base de datos hasta que se los solicitaba, sin importar cuántos días, meses o incluso años después.
En la era de los grandes datos, donde los conjuntos de datos ahora han crecido de unos pocos gigabytes a decenas de gigabytes e incluso petabytes para algunas de nuestras aplicaciones más exigentes. Los datos están llegando a nuestras bases de datos y las aplicaciones exigen que los datos se muestren rápida y frecuentemente para cumplir con las expectativas de los usuarios de una experiencia de aplicación rápida y personalizada.
Ahora, Azure Cosmos DB se ha disparado como la respuesta a las demandas de big data de las aplicaciones nativas de la nube. Debido a que las bases de datos no relacionales o NoSQL como Azure Cosmos DB se escalan horizontalmente en lugar de verticalmente, básicamente podemos liberar el rendimiento y el volumen de datos en nuestra base de datos. En lugar de actualizar el hardware en un solo Node para atender las requests más rápido, Cosmos DB distribuye ese trabajo entre varios Nodes para que las requests se puedan atender simultáneamente. El escalado horizontal frente al escalado vertical es la mayor diferencia entre las bases de datos relacionales y las bases de datos no relacionales como Cosmos DB.
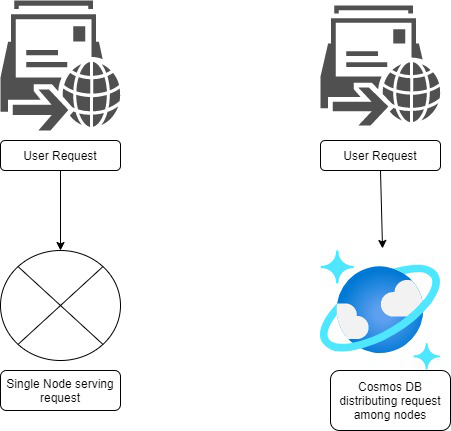
El escalado horizontal o escalado horizontal es la consecuencia de dos técnicas: el particionamiento y la replicación . Ahora hay dos tipos de particiones en Azure Cosmos DB: lógicas y físicas .
Una partición física es una unidad de almacenamiento real que se encuentra físicamente en la región de Azure que dictamos. Esta es una pieza de hardware que contiene nuestros datos en algún lugar de la nube. Las particiones lógicas son grupos lógicos entre elementos dentro de nuestro conjunto de datos, y hacemos referencia a estos grupos a través de algo llamado clave de partición . La clave de partición es importante porque le dice a nuestro motor de base de datos dónde buscar nuestros datos. Elegir la clave de partición correcta es una parte simple pero importante de la optimización de nuestra base de datos, y cuando se hace correctamente, podemos esperar ver ganancias de rendimiento proporcionales a la cantidad adicional de Nodes que atienden nuestras requests. En pocas palabras, la partición de nuestros datos entre Nodes mejora la latencia y el rendimiento de la base de datos.
Ahora, al igual que con las particiones, también hay dos tipos de replicación en Cosmos DB: replicación dentro de una región y replicación geográfica fuera de una región . Ahora, dentro de una región, nuestros datos se replican cuatro veces como medida de redundancia, lo que mejora la tolerancia a fallas. Fuera de una región, nuestros datos se replican geográficamente en cualquier región de Azure adicional que seleccionemos, lo que da como resultado una mayor disponibilidad. La replicación dentro de una sola región aumenta la tolerancia a fallas. La replicación geográfica en regiones adicionales de Azure aumenta la disponibilidad. Ahora bien, estas dos técnicas, la replicación y el particionamiento, son en gran parte lo que hace posible el escalado horizontal.
Ahora, lo que hace que NoSQL sea atractivo para los desarrolladores operativos modernos, aparte de las ganancias de rendimiento y disponibilidad, son las restricciones relajadas para mantener nuestros datos relacionales. Cosmos DB es una estructura de significado sin esquema que no se aplica a los datos que ingresan a la base de datos. Dos documentos en la misma colección pueden tener una estructura completamente diferente sin ningún problema. Y como resultado, los desarrolladores pueden ingresar datos estructuralmente variables en la base de datos y luego crear, cambiar o agregar funcionalidad a medida que evoluciona el uso de esos datos. Esta combinación de esquema flexible y escalamiento horizontal es lo que hace que NoSQL sea diferente.
Cosmos DB facilita la ingesta y el resurgimiento de grandes volúmenes de datos variables sin comprometer el rendimiento o la disponibilidad. Además del esquema flexible, Cosmos también admite múltiples modelos de datos. Cosmos se ha creado para ser el centro de todos los tipos de datos NoSQL.
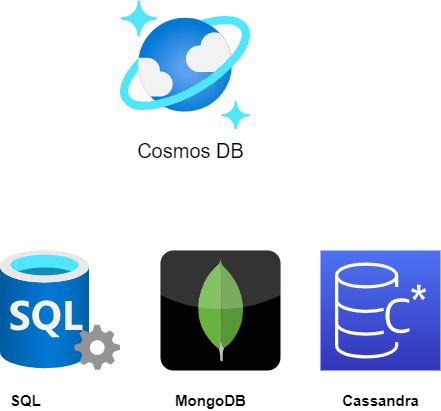
Cosmos tiene una API de SQL con soporte para documentos y valores clave incorporado. Los documentos y los pares clave-valor van de la mano en la mayoría de las bases de datos NoSQL porque los documentos son solo pares clave-valor en los que la clave es un documento y el valor es un objeto JSON que simplemente llamamos documento. Ahora, para obtener los beneficios de rendimiento de un verdadero almacén de clave-valor, con una API de SQL, podemos realizar lecturas puntuales rápidas y rentables siempre que sepamos el ID del documento y la clave de partición del elemento que queremos leer. Esta es una gran herramienta de optimización para aplicaciones. Se puede acceder al siguiente modelo de datos, el modelo de datos de gráfico, a través de la API de Gremlin, que utiliza bordes y vértices, así como un recorrido para modelar sistemas complejos con muchas relaciones. Piense en un gráfico como una web o una red de Nodes. La API es para Mongo DB y Cassandra respectivamente, se crean para que los desarrolladores familiarizados con ambas bases de datos de código abierto puedan trabajar con las herramientas, los SDK y los controladores a los que ya están acostumbrados. API para Mongo DB también aprovecha los documentos, y Cassandra API es una tienda de columna ancha, que orienta datos de manera eficiente en columnas en lugar de filas para optimizar el análisis. Eso es todo para nuestro primer episodio. Cosmos DB es nuestra base de datos NoSQL de escala horizontal. El particionamiento lo hace rápido, la replicación lo hace disponible y el esquema flexible hace que sea fácil trabajar con él. Base de datos NoSQL. El particionamiento lo hace rápido, la replicación lo hace disponible y el esquema flexible hace que sea fácil trabajar con él. Base de datos NoSQL. El particionamiento lo hace rápido, la replicación lo hace disponible y el esquema flexible hace que sea fácil trabajar con él.
Publicación traducida automáticamente
Artículo escrito por ddeevviissaavviittaa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA