En este artículo, discutiremos rbind() en python.
Método 1: Usar la función rbind() con columnas iguales
Aquí tenemos que tomar 2 marcos de datos con columnas iguales y aplicar la función concat() . Esto combinará las filas en función de las columnas.
Sintaxis :
pandas.concat([dataframe1, dataframe2])
dónde
- dataframe1 es el primer marco de datos
- dataframe2 es el segundo marco de datos
Ejemplo:
Python3
# import pandas module
import pandas as pd
# create first dataframe
data1 = pd.DataFrame({'fruits': ['apple', 'guava', 'mango', 'banana'],
'cost': [34, 56, 65, 45]})
# create second dataframe
data2 = pd.DataFrame({'fruits': ['cuatard apple', 'guava', 'mango', 'papaya'],
'cost': [314, 86, 65, 51]})
# concat two columns
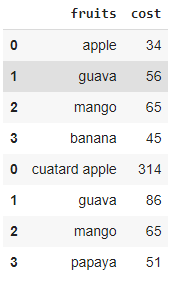
pd.concat([data1, data2])
Salida :
Método 2: Usar la función rbind() con columnas desiguales
Aquí las dos columnas de marcos de datos no son iguales. En este escenario, la columna no coincidente obtendrá filas reemplazadas por NAN en su columna.
Sintaxis :
pandas.concat([dataframe1, dataframe2])
dónde,
- dataframe1 es el primer marco de datos
- dataframe2 es el segundo marco de datos
Ejemplo:
Python3
# import pandas module
import pandas as pd
# create first dataframe with 2 columns
data1 = pd.DataFrame({'fruits': ['apple', 'guava', 'mango', 'banana'],
'cost': [34, 56, 65, 45]})
# create second dataframe with 3 columns
data2 = pd.DataFrame({'fruits': ['cuatard apple', 'guava', 'mango', 'papaya'],
'cost': [314, 86, 65, 51],
'city': ['guntur', 'tenali', 'ponnur', 'hyd']})
# concat two columns
pd.concat([data1, data2])
Salida :
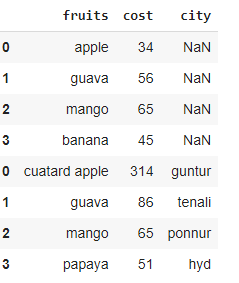
Aquí observamos que el índice de las filas nuevamente comienza desde 0, para evitar esto, tenemos que usar el método .reset_index() . Esto restablecerá el índice del nuevo marco de datos.
Sintaxis :
pandas.concat([dataframe1, dataframe2]).reset_index(drop=True)
Ejemplo :
Python3
# import pandas module
import pandas as pd
# create first dataframe with 2 columns
data1 = pd.DataFrame({'fruits': ['apple', 'guava', 'mango', 'banana'],
'cost': [34, 56, 65, 45]})
# create second dataframe with 3 columns
data2 = pd.DataFrame({'fruits': ['cuatard apple', 'guava', 'mango', 'papaya'],
'cost': [314, 86, 65, 51],
'city': ['guntur', 'tenali', 'ponnur', 'hyd']})
# concat two columns
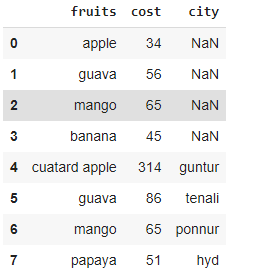
pd.concat([data1, data2]).reset_index(drop=True)
Salida :
Publicación traducida automáticamente
Artículo escrito por manojkumarreddymallidi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA