El Muestreo Estratificado es una técnica de muestreo utilizada para obtener muestras que mejor representen a la población. Reduce el sesgo en la selección de muestras al dividir la población en subgrupos homogéneos llamados estratos y muestrear aleatoriamente los datos de cada estrato (forma singular de estratos).
En estadística, el muestreo estratificado se utiliza cuando los valores medios de cada estrato difieren. En el aprendizaje automático, el muestreo estratificado se usa comúnmente para crear conjuntos de datos de prueba para evaluar modelos, especialmente cuando el conjunto de datos es significativamente grande y desequilibrado.
Pasos involucrados en el muestreo estratificado
- Separación de la población en estratos: en este paso, la población se divide en estratos en función de características similares y cada miembro de la población debe pertenecer exactamente a un estrato (singular de estratos).
- Determine el tamaño de la muestra: decida cuán pequeña o grande debe ser la muestra.
- Muestreo aleatorio de cada estrato: Las muestras aleatorias de cada estrato se seleccionan utilizando un muestreo desproporcionado en el que el tamaño de la muestra de cada estrato es igual independientemente del tamaño de la población del estrato o un muestreo proporcional en el que el tamaño de la muestra de cada estrato es proporcional al tamaño de la población de cada estrato . el estrato
Ejemplo 1:
En este ejemplo, tenemos un conjunto de datos ficticio de 10 estudiantes y tomaremos una muestra de 6 estudiantes en función de sus calificaciones, utilizando un muestreo estratificado desproporcionado y proporcional.
Paso 1: cree el conjunto de datos ficticio a partir de un diccionario de python usando pandas DataFrame
Python3
import pandas as pd
# Create a dictionary of students
students = {
'Name': ['Lisa', 'Kate', 'Ben', 'Kim', 'Josh',
'Alex', 'Evan', 'Greg', 'Sam', 'Ella'],
'ID': ['001', '002', '003', '004', '005', '006',
'007', '008', '009', '010'],
'Grade': ['A', 'A', 'C', 'B', 'B', 'B', 'C',
'A', 'A', 'A'],
'Category': [2, 3, 1, 3, 2, 3, 3, 1, 2, 1]
}
# Create dataframe from students dictionary
df = pd.DataFrame(students)
# view the dataframe
df
Producción:
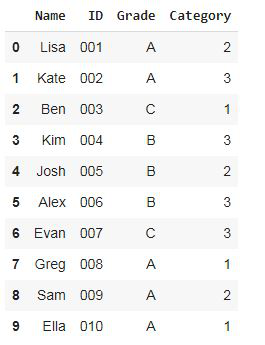
Observe que hay un 50 % de estudiantes de grado A, un 30 % de estudiantes de grado B y un 20 % de estudiantes de grado C.
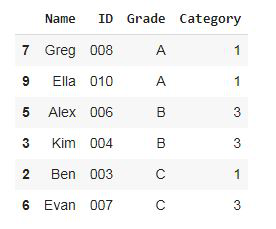
Paso 2: Crear una muestra de 6 estudiantes de manera desproporcionada (igual número de estudiantes de cada estrato de grado)
Muestreo desproporcionado: usando pandas groupby, separe a los estudiantes en grupos según su calificación, es decir, A, B, C y muestree aleatoriamente a 2 estudiantes de cada grupo de grado usando la función de muestra
Python3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(2))
Producción:
Paso 3: Muestree el 60% de los estudiantes proporcionalmente (cree muestras proporcionales de cada estrato en función de su proporción en la población)
Muestreo proporcional: utilizando pandas groupby, separe a los estudiantes en grupos según su calificación, es decir, A, B, C, y una muestra aleatoria de cada grupo según la proporción de la población. El tamaño total de la muestra es 60%(0.6) de la población
Python3
df.groupby('Grade', group_keys=False).apply(lambda x: x.sample(frac=0.6))
Producción:
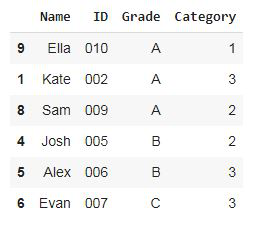
Observe que, incluso en la muestra, hay un 50 % de estudiantes de grado A, un 30 % de estudiantes de grado B y un 20 % de estudiantes de grado C.
Ejemplo 2:
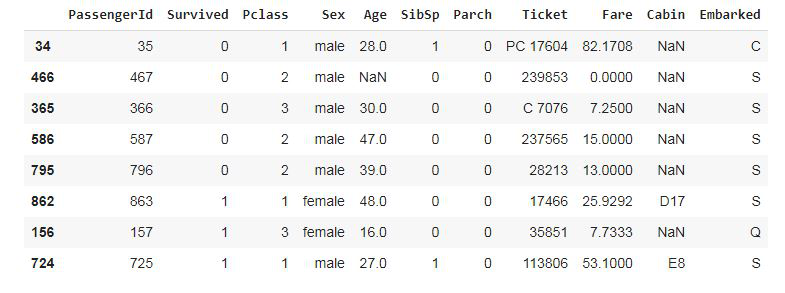
En este ejemplo , crearemos datos de muestra a partir del conjunto de datos del tren . Titanic fue un pasajero británico que se hundió en el Océano Atlántico Norte tras chocar contra un iceberg. El conjunto de datos contiene información sobre todos los pasajeros que abordaron el Titanic, un pasajero murió o sobrevivió al accidente, por lo que usaremos la columna Sobrevivientes como nuestra columna de estratificación.
Paso 1: Lea el conjunto de datos del archivo CSV
Python3
import pandas as pd
# read the dataset as csv file
data = pd.read_csv('Titanic.csv')
# drop the name column as it is of no importance here
data.drop('Name', axis=1, inplace=True)
# view the first 5 rows of the titanic dataset
data.head()
Producción:
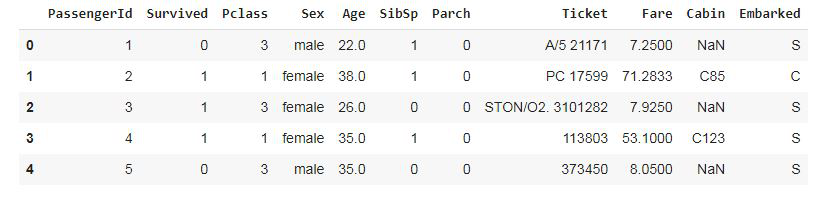
Paso 2: Comprobar el porcentaje de pasajeros muertos/sobrevivientes
Verifique la proporción/porcentaje de pasajeros que murieron o sobrevivieron, esto da un número de pasajeros muertos o vivos / número total de pasajeros * 100
Python3
(data['Survived'].value_counts()) / len(data) * 100
Producción:
0 61.616162 1 38.383838
donde 0 representa pasajeros que fallecieron (61,6%) y 1 representa pasajeros que sobrevivieron (38,4%)
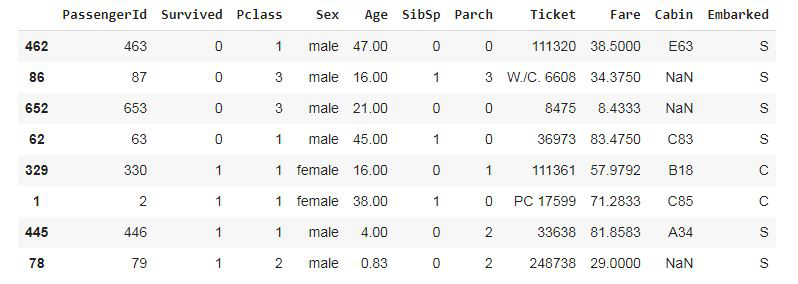
Paso 3: Muestra desproporcionadamente de 8 pasajeros (4 que murieron y 4 que sobrevivieron)
Python3
# Disproportionate sampling:
# randomly select 4 samples from each stratum
data.groupby('Survived', group_keys=False).apply(lambda x: x.sample(4))
Producción:
Paso 4: Muestra proporcional del 1 % (0,01) de los pasajeros (el 0,6 % murió y el 0,4 % sobrevivió)
Python3
data.groupby('Survived', group_keys=False).
apply(lambda x: x.sample(frac=0.01))
Producción: