En este artículo, cubriremos la descripción general de la programación de CUDA y nos centraremos principalmente en el concepto de requisito de CUDA y también discutiremos el modelo de ejecución de CUDA. Finalmente, veremos la aplicación. Discutámoslo uno por uno.
CUDA son las siglas de Compute Unified Device Architecture. Es una extensión de la programación C/C++. CUDA es un lenguaje de programación que utiliza la Unidad de Procesamiento Gráfico (GPU). Es una plataforma de computación paralela y un modelo API (Interfaz de programación de aplicaciones), Compute Unified Device Architecture fue desarrollado por Nvidia. Esto permite que los cálculos se realicen en paralelo mientras proporciona una velocidad bien formada. Con CUDA, se puede aprovechar la potencia de la GPU Nvidia para realizar tareas informáticas comunes, como el procesamiento de arrays y otras operaciones de álgebra lineal, en lugar de simplemente realizar cálculos gráficos.
¿Por qué necesitamos CUDA?
- Las GPU están diseñadas para realizar cálculos paralelos de alta velocidad para mostrar gráficos como juegos.
- Utilice los recursos CUDA disponibles. Ya se han implementado más de 100 millones de GPU.
- Proporciona una aceleración de 30 a 100 veces superior a la de otros microprocesadores para algunas aplicaciones.
- Las GPU tienen Unidades Lógicas Aritméticas (ALU) muy pequeñas en comparación con las CPU algo más grandes. Esto permite muchos cálculos paralelos, como calcular el color de cada píxel de la pantalla, etc.
Arquitectura de CUDA
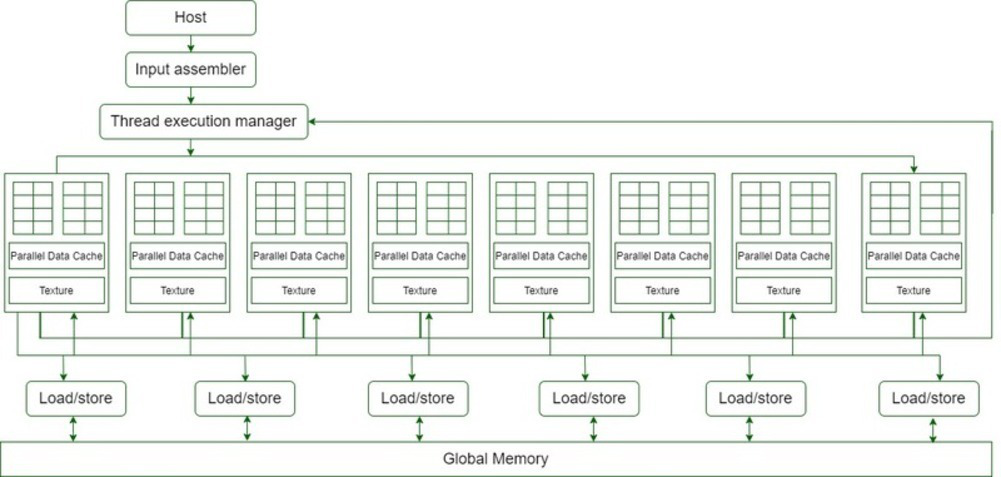
- 16 Los diagramas de multiprocesador de transmisión (SM) se muestran en el diagrama anterior.
- Cada Streaming Multiprocessor tiene 8 Streaming Processors (SP), es decir, obtenemos un total de 128 Streaming Processors (SP).
- Ahora, cada procesador Streaming tiene una unidad MAD (Unidad de multiplicación y suma) y una MU (unidad de multiplicación) adicional.
- El GT200 tiene 240 procesadores de transmisión (SP) y más de 1 TFLOP de potencia de procesamiento.
- Cada Streaming Processor se enhebra con gracia y puede ejecutar miles de hilos por aplicación.
- La tarjeta G80 admite 768 subprocesos por Streaming Multiprocessor (nota: no por SP).
- Eventualmente, después de que cada multiprocesador de transmisión tenga 8 SP, cada SP admite un máximo de 96 subprocesos. Total de subprocesos que pueden ejecutarse: 128 * 96 = 12 228 veces.
- Por lo tanto, estos procesadores se denominan masivamente paralelos.
- Los chips G80 tienen un ancho de banda de memoria de 86,4 GB/s.
- También tiene un canal de comunicación de 8 GB/s con la CPU (4 GB/s para cargar a la RAM de la CPU y 4 GB/s para descargar desde la RAM de la CPU).
¿Cómo funciona CUDA?
- Las GPU ejecutan un kernel (un grupo de tareas) a la vez.
- Cada kernel consta de bloques, que son grupos independientes de ALU.
- Cada bloque contiene subprocesos, que son niveles de cálculo.
- Los subprocesos de cada bloque suelen trabajar juntos para calcular un valor.
- Los subprocesos en el mismo bloque pueden compartir memoria.
- En CUDA, enviar información desde la CPU a la GPU suele ser la parte más típica del cálculo.
- Para cada subproceso, la memoria local es la más rápida, seguida de la memoria compartida, la memoria global, estática y de textura, la más lenta.
¿Cómo se distribuye el trabajo?
- Cada subproceso «conoce» las coordenadas x e y del bloque en el que se encuentra, y las coordenadas en las que se encuentra en el bloque.
- Estas posiciones se pueden usar para calcular una ID de subproceso única para cada subproceso.
- El trabajo computacional realizado dependerá del valor de la identificación del subproceso.
Por ejemplo, el ID de subproceso corresponde a un grupo de elementos de array.
Aplicaciones CUDA
Las aplicaciones CUDA deben ejecutar operaciones paralelas en una gran cantidad de datos y ser intensivas en procesamiento.
- Finanzas computacionales
- Modelado climático, meteorológico y oceánico
- Ciencia de datos y análisis
- Aprendizaje profundo y aprendizaje automático
- Defensa e inteligencia
- Fabricación/AEC
- Medios y entretenimiento
- Imagenes medicas
- Petróleo y gas
- Investigar
- Seguridad y proteccion
- Herramientas y gestión
Beneficios de CUDA
Hay varias ventajas que le dan a CUDA una ventaja sobre las computadoras tradicionales con procesador de gráficos (GPU) de propósito general con API de gráficos:
- Memoria integrada (CUDA 6.0 o posterior) y Memoria virtual integrada (CUDA 4.0 o posterior).
- La memoria compartida proporciona un área rápida de memoria compartida para subprocesos CUDA. Se puede utilizar como mecanismo de almacenamiento en caché y proporciona más ancho de banda que la búsqueda de texturas.
- Los códigos de lectura dispersos se pueden leer desde cualquier dirección en la memoria.
- Rendimiento mejorado en descargas y lecturas, que funciona bien desde la GPU y hacia la GPU.
- CUDA tiene soporte completo para operaciones bit a bit y enteras.
Limitaciones de CUDA
- El código fuente de CUDA se proporciona en la máquina host o GPU, según lo definido por las reglas de sintaxis de C++. Las versiones antiguas de CUDA usan reglas de sintaxis C, lo que significa que el código fuente de CUDA actualizado puede o no funcionar según lo requerido.
- CUDA tiene interoperabilidad unilateral (la capacidad de los sistemas informáticos o el software para intercambiar y hacer uso de la información) con lenguajes de transferencia como OpenGL. OpenGL puede acceder a la memoria registrada de CUDA, pero CUDA no puede acceder a la memoria de OpenGL.
- Las versiones posteriores de CUDA no proporcionan emuladores ni soporte alternativo para versiones anteriores.
- CUDA solo admite hardware NVIDIA.
Publicación traducida automáticamente
Artículo escrito por amitverma2d y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA