GroupBy es un concepto bastante simple. Podemos crear una agrupación de categorías y aplicar una función a las categorías. Es un concepto simple, pero es una técnica extremadamente valiosa que se usa ampliamente en la ciencia de datos. En los proyectos reales de ciencia de datos, se tratará con grandes cantidades de datos y se probarán cosas una y otra vez, por lo que, para mayor eficiencia, utilizamos el concepto Groupby. El concepto Groupby es realmente importante debido a su capacidad para resumir, agregar y agrupar datos de manera eficiente.
Resumir
El resumen incluye contar, describir todos los datos presentes en el marco de datos. Podemos resumir los datos presentes en el marco de datos usando el método describe(). Este método se utiliza para obtener valores mínimos, máximos, de suma y de conteo del marco de datos junto con los tipos de datos de esa columna en particular.
- describe(): Este método elabora el tipo de datos y sus atributos.
Sintaxis:
dataframe_name.describe()
- unique(): este método se utiliza para obtener todos los valores únicos de la columna dada.
Sintaxis:
dataframe[‘column_name].unique()
- nunique(): este método es similar a unique pero devolverá el recuento de valores únicos.
Sintaxis:
dataframe_name[‘column_name].nunique()
- info(): este comando se usa para obtener los tipos de datos y la información de las columnas
Sintaxis:
dataframe.info()
- columnas: este comando se usa para mostrar todos los nombres de columna presentes en el marco de datos
Sintaxis:
dataframe.columns
Ejemplo:
Vamos a analizar los datos de calificaciones de los estudiantes en este ejemplo.
Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
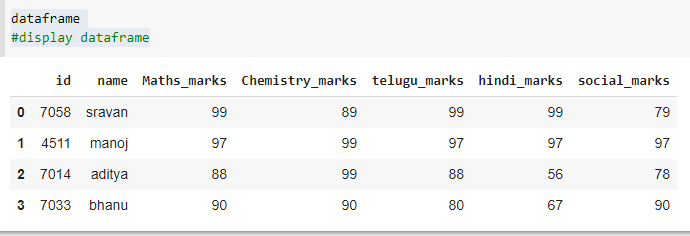
dataframe
Producción:
Python3
# describing the data frame
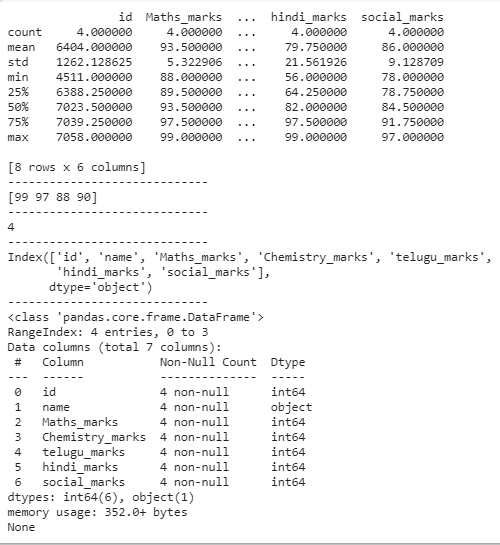
print(dataframe.describe())
print("-----------------------------")
# finding unique values
print(dataframe['Maths_marks'].unique())
print("-----------------------------")
# counting unique values
print(dataframe['Maths_marks'].nunique())
print("-----------------------------")
# display the columns in the data frame
print(dataframe.columns)
print("-----------------------------")
# information about dataframe
print(dataframe.info())
Producción:
Agregación
La agregación se usa para obtener la media, el promedio, la varianza y la desviación estándar de todas las columnas en un marco de datos o una columna particular en un marco de datos.
- sum(): Devuelve la suma del marco de datos
Sintaxis:
marco de datos [‘columna]. sum()
- mean(): devuelve la media de la columna particular en un marco de datos
Sintaxis:
marco de datos [‘columna]. significa()
- std(): Devuelve la desviación estándar de esa columna.
Sintaxis:
marco de datos[‘columna].std()
- var(): Devuelve la varianza de esa columna
dataframe[‘columna’].var()
- min(): Devuelve el valor mínimo en la columna
Sintaxis:
marco de datos[‘columna’].min()
- max(): devuelve el valor máximo en la columna
Sintaxis:
marco de datos[‘columna’].max()
Ejemplo:
En el siguiente programa agregaremos datos.
Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframe
Producción:
Python3
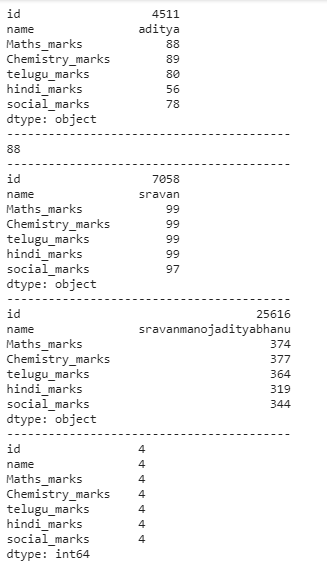
# getting all minimum values from
# all columns in a dataframe
print(dataframe.min())
print("-----------------------------------------")
# minimum value from a particular
# column in a data frame
print(dataframe['Maths_marks'].min())
print("-----------------------------------------")
# computing maximum values
print(dataframe.max())
print("-----------------------------------------")
# computing sum
print(dataframe.sum())
print("-----------------------------------------")
# finding count
print(dataframe.count())
print("-----------------------------------------")
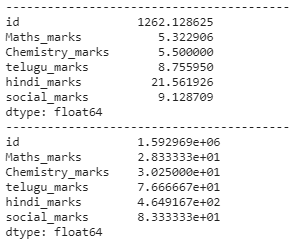
# computing standard deviation
print(dataframe.std())
print("-----------------------------------------")
# computing variance
print(dataframe.var())
Producción:
Agrupamiento
Se usa para agrupar una o más columnas en un dataframe usando el método groupby() . Groupby se refiere principalmente a un proceso que involucra uno o más de los siguientes pasos:
- División: es un proceso en el que dividimos los datos en grupos aplicando algunas condiciones en los conjuntos de datos.
- Aplicar: Es un proceso en el que aplicamos una función a cada grupo de forma independiente
- Combinar: Es un proceso en el que combinamos diferentes conjuntos de datos después de aplicar groupby y da como resultado una estructura de datos.
Ejemplo 1:
Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
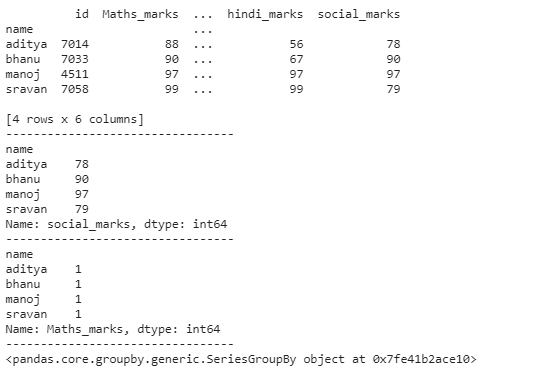
print(dataframe.groupby('name').first())
print("---------------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("---------------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
print("---------------------------------")
# group by name with maths_marks
print(dataframe.groupby('name')['Maths_marks'])
Producción:
Ejemplo 2:
Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
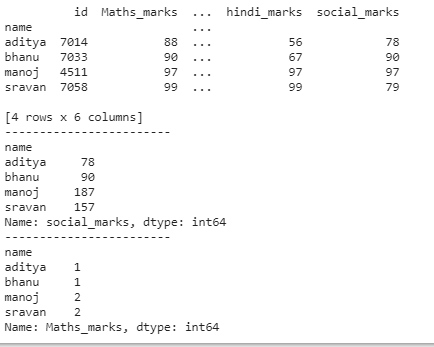
print(dataframe.groupby('name').first())
print("------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA