En MongoDB, las operaciones de agregación procesan los registros/documentos de datos y devuelven los resultados calculados. Recopila valores de varios documentos y los agrupa y luego realiza diferentes tipos de operaciones en esos datos agrupados como suma, promedio, mínimo, máximo, etc. para devolver un resultado calculado. Es similar a la función agregada de SQL.
MongoDB proporciona tres formas de realizar la agregación
- Tubería de agregación
- Función de reducción de mapa
- Agregación de propósito único
Tubería de agregación
En MongoDB, la canalización de agregación consta de etapas y cada etapa transforma el documento. O, en otras palabras, la canalización de agregación es una canalización de varias etapas, por lo que en cada estado, los documentos se toman como entrada y producen el conjunto resultante de documentos ahora en la siguiente etapa (id disponible) los documentos resultantes se toman como entrada y producen salida , este proceso continúa hasta la última etapa. Las etapas básicas de la canalización proporcionan filtros que funcionarán como consultas y la transformación del documento modifica el documento resultante y la otra canalización proporciona herramientas para agrupar y clasificar documentos. También puede usar la canalización de agregación en la colección fragmentada.
Analicemos la canalización de agregación con la ayuda de un ejemplo:
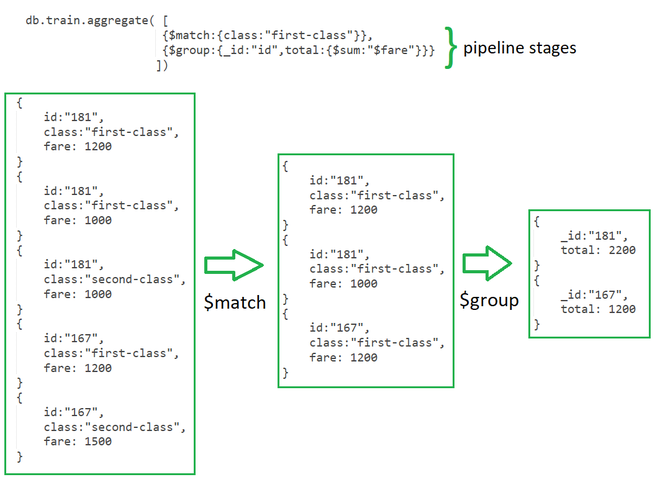
En el ejemplo anterior de una colección de tarifas de tren en la primera etapa. Aquí, la etapa $match filtra los documentos por el valor en el campo de clase, es decir, clase: «primera clase» y pasa el documento a la segunda etapa. En la Segunda Etapa, la etapa $group agrupa los documentos por el campo id para calcular la suma de la tarifa para cada id único.
Aquí, la función de agregado() se usa para realizar la agregación; puede tener tres etapas de operadores, expresión y acumulador.

Etapas: Cada etapa comienza con operadores de etapa que son:
- $match: se utiliza para filtrar los documentos y puede reducir la cantidad de documentos que se dan como entrada para la siguiente etapa.
- $proyecto: Se utiliza para seleccionar algunos campos específicos de una colección.
- $group: se utiliza para agrupar documentos en función de algún valor.
- $sort: Se utiliza para ordenar el documento que los está reorganizando.
- $skip: Se usa para saltar n número de documentos y pasa los documentos restantes
- $limit: se utiliza para pasar el primer número n de documentos, limitándolos así.
- $unwind: se utiliza para desenrollar documentos que usan arrays, es decir, deconstruye un campo de array en los documentos para devolver documentos para cada elemento.
- $out: se utiliza para escribir documentos resultantes en una nueva colección
Expresiones: se refiere al nombre del campo en los documentos de entrada, por ejemplo, { $grupo : { _id : “ $id “, total:{$sum:” $tarifa “}}} aquí $id y $tarifa son expresiones.
Acumuladores: Se utilizan básicamente en la fase de grupos
- sum: Suma los valores numéricos de los documentos de cada grupo
- count: cuenta el número total de documentos
- avg: Calcula el promedio de todos los valores dados de todos los documentos
- min: Obtiene el valor mínimo de todos los documentos
- max: Obtiene el valor máximo de todos los documentos
- primero: Obtiene el primer documento de la agrupación
- last: Obtiene el último documento de la agrupación
Nota:
- en $group _id es un campo obligatorio
- $out debe ser la última etapa en la canalización
- $sum:1 contará el número de documentos y $sum:”$tarifa” dará la suma de la tarifa total generada por id.
Ejemplos:
En los siguientes ejemplos, estamos trabajando con:
Base de datos: GeeksForGeeks
Colección: estudiantes
Documentos: Siete documentos que contienen los datos de los alumnos en forma de pares campo-valor.
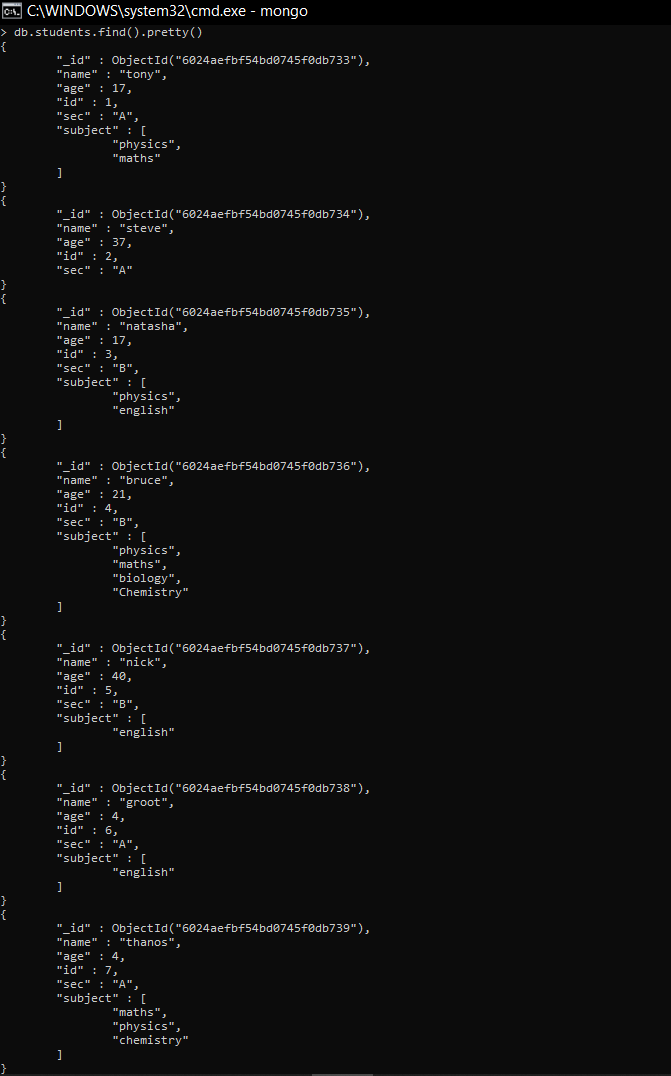
- Mostrar el número total de estudiantes en una sola sección
db.students.aggregate([{$match:{sec:"B"}},{$count:"Total student in sec:B"}])
En este ejemplo, para contar la cantidad de estudiantes en la sección B, primero filtramos los documentos usando el operador $match y luego usamos el acumulador $count para contar la cantidad total de documentos que se pasan después de filtrar desde $juego.
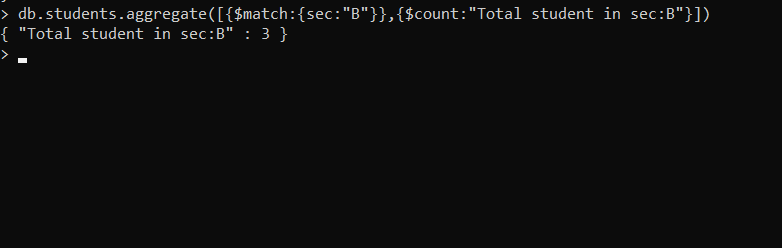
- Mostrar el número total de estudiantes en ambas secciones y la edad máxima de ambas secciones
db.students.aggregate([{$group: {_id:"$sec", total_st: {$sum:1}, max_age:{$max:"$age"} } }])
En este ejemplo, usamos $group to group, de modo que podamos contar para cada otra sección en los documentos, aquí $sum resume el documento en cada grupo y $max acumulador se aplica en la expresión de edad que encontrará la edad máxima en cada documento.
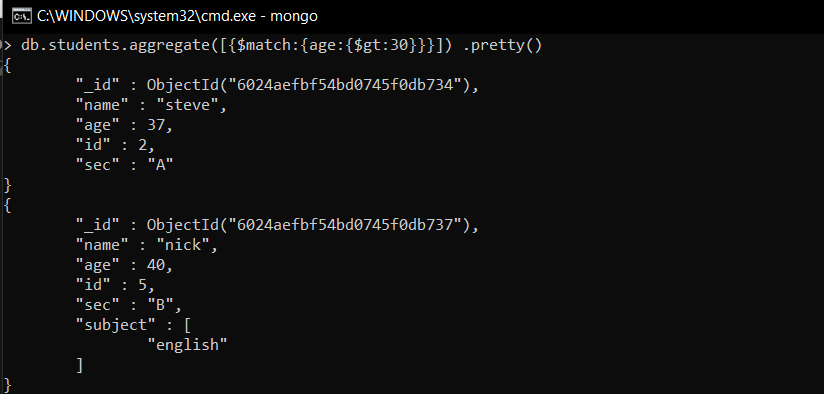
- Mostrar detalles de los estudiantes cuya edad es mayor de 30 años usando la etapa de coincidencia
db.students.aggregate([{$match:{age:{$gt:30}}}])
En este ejemplo, mostramos los estudiantes cuya edad es mayor de 30 años. Por lo tanto, usamos el operador $match para filtrar los documentos.
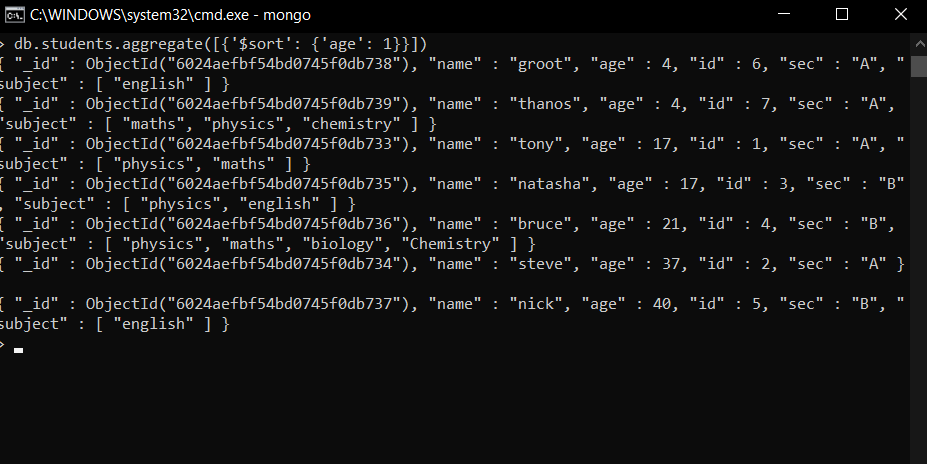
- Clasificación de los alumnos según la edad.
db.students.aggregate([{'$sort': {'age': 1}}])
En este ejemplo, estamos usando el operador $sort para ordenar en orden ascendente. Proporcionamos ‘edad’:1. Si queremos ordenar en orden descendente, simplemente podemos cambiar 1 a -1, es decir, ‘edad’:-1.
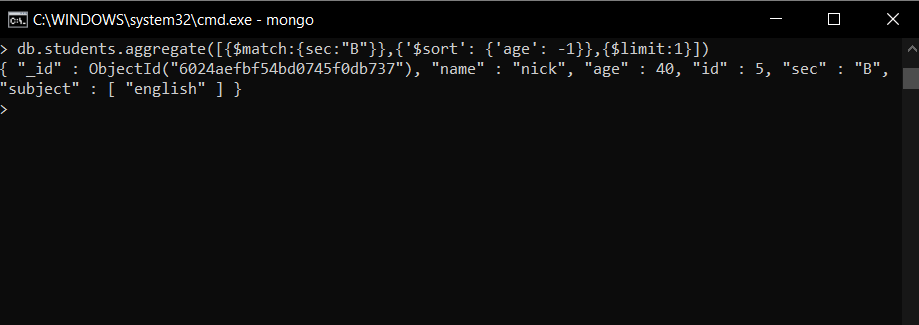
- Mostrar detalles de un estudiante que tiene la mayor edad en la sección – B
db.students.aggregate([{$match:{sec:"B"}},{'$sort': {'age': -1}},{$limit:1}])
En este ejemplo, primero, solo seleccionamos aquellos documentos que tienen la sección B, por lo que, para eso, usamos el operador $match , luego ordenamos los documentos en orden descendente usando $sort configurando ‘edad’: -1 y luego para mostrar solo el resultado superior usamos $limit .
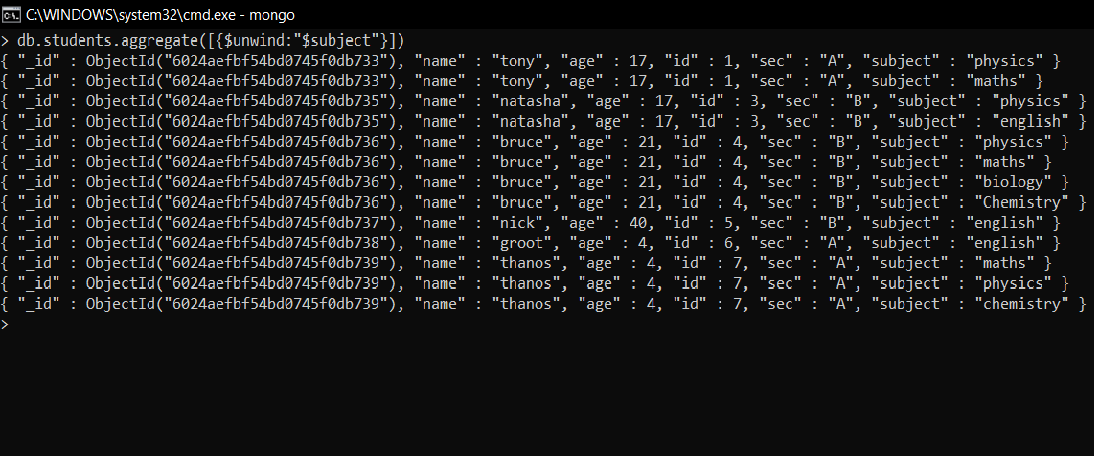
- Relajar a los estudiantes sobre la base de la materia
El desenredado funciona en la array aquí en nuestra colección, tenemos una variedad de temas (que consta de diferentes temas dentro de él, como matemáticas, física, inglés, etc.), por lo que el desenrollado se realizará en eso, es decir, la array se deconstruirá y la salida tendrá solo una tema no una serie de temas que estaban allí antes.
db.students.aggregate([{$unwind:"$subject"}])
Mapa reducido
Map reduce se usa para agregar resultados para el gran volumen de datos. Map reduce tiene dos funciones principales, una es un mapa que agrupa todos los documentos y la segunda es reduce , que realiza operaciones en los datos agrupados.
Sintaxis:
db.collectionName.mapReduce(mappingFunction, reduceFunction, {out:'Result'});
Ejemplo:
En el siguiente ejemplo, estamos trabajando con:
Base de datos: GeeksForGeeks
Colección: estudiantesMark
Documentos: Siete documentos que contienen los datos de los alumnos en forma de pares campo-valor.
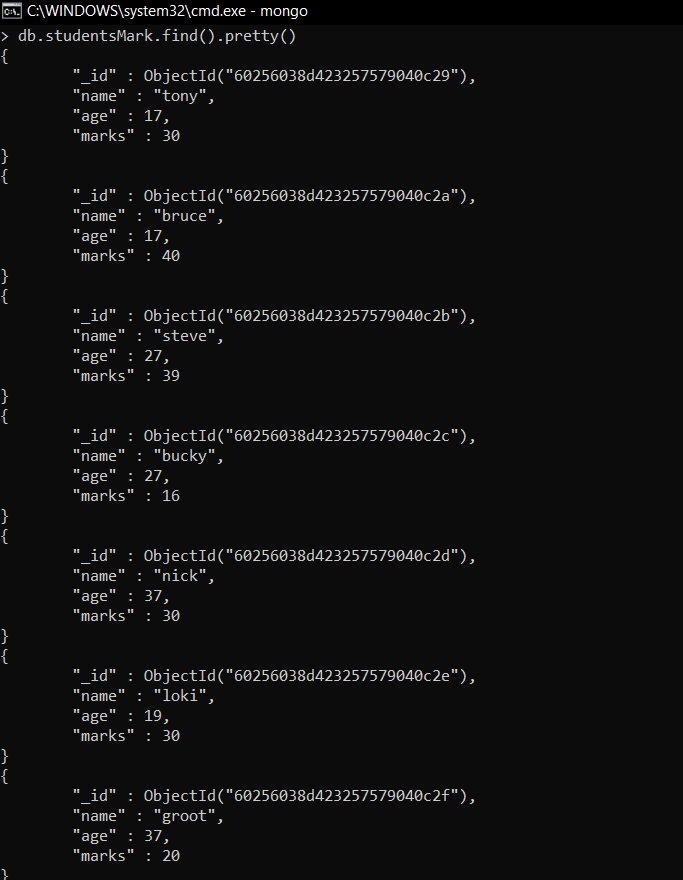
var mapfunction = function(){emit(this.age, this.marks)}
var reducefunction = function(key, values){return Array.sum(values)}
db.studentsMarks.mapReduce(mapfunction, reducefunction, {'out':'Result'})
Ahora, agruparemos los documentos según la edad y encontraremos las calificaciones totales en cada grupo de edad. Entonces, crearemos dos variables, primero mapfunction que emitirá la edad como una clave (expresada como «_id» en la salida) y marcará como valor. Estos datos emitidos se pasan a nuestra función reduce, que toma la clave y el valor como datos agrupados, y luego realiza operaciones sobre él. Después de realizar la reducción, los resultados se almacenan en una colección aquí, en este caso, la colección es Resultados.
Agregación de propósito único
Se usa cuando necesitamos un acceso simple al documento, como contar la cantidad de documentos o para encontrar todos los valores distintos en un documento. Simplemente proporciona el acceso al proceso de agregación común mediante los métodos count(), distint() y estimadaDocumentCount(), por lo que carece de la flexibilidad y las capacidades de la canalización.
Ejemplo:
En el siguiente ejemplo, estamos trabajando con:
Base de datos: GeeksForGeeks
Colección: estudiantesMark
Documentos: Siete documentos que contienen los datos de los alumnos en forma de pares campo-valor.
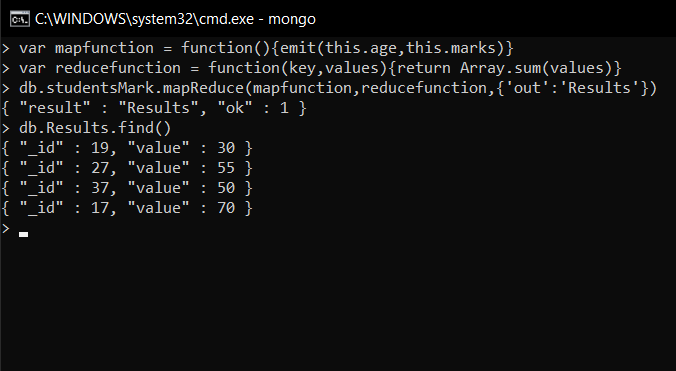
- Mostrar nombres y edades distintos (no repetitivos)
db.studentsMarks.distinct("name")
Aquí, usamos un método distinto() que encuentra valores distintos del campo especificado (es decir, nombre).
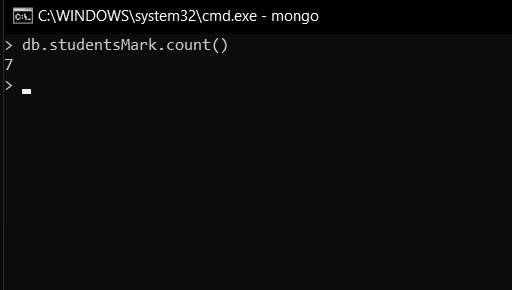
- Contar el número total de documentos
db.studentsMarks.count()
Aquí, usamos count() para encontrar el número total del documento, a diferencia del método find(), no encuentra todo el documento, sino que los cuenta y devuelve un número.
Publicación traducida automáticamente
Artículo escrito por darksiderrohan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA