Python es un lenguaje de programación de código abierto tipificado e interpretado dinámicamente. Leer y escribir archivos es una parte integral de la programación. En Python, los archivos se leen usando readlines()método. El método readlines() devuelve una lista donde cada elemento de la lista es una oración completa en el archivo. Este método es útil cuando el tamaño del archivo es pequeño. Dado que el método readlines() agrega cada línea a la lista y luego devuelve la lista completa, llevará mucho tiempo si el tamaño del archivo es extremadamente grande, digamos en GB. Además, la lista consumirá una gran parte de la memoria, lo que puede provocar una pérdida de memoria si no hay suficiente memoria disponible. Para evitar este problema, podemos usar el objeto de archivo como un iterador para iterar sobre el archivo y realizar la tarea requerida. Dado que el iterador solo itera sobre todo el archivo y no requiere ninguna estructura de datos adicional para el almacenamiento de datos, la memoria consumida es comparativamente menor. Además, el iterador no realiza operaciones costosas como agregar, por lo que también es eficiente en el tiempo.
Los siguientes dos programas demuestran cómo se pueden leer archivos de texto grandes usando Python.
Método 1:
El primer enfoque hace uso del iterador para iterar sobre el archivo. En esta técnica, usamos el módulo de entrada de archivos en Python. El método input() del módulo fileinput se puede usar para leer archivos. La ventaja de usar este método sobre readlines() es que fileinput.input() no carga el archivo completo en la memoria. Por lo tanto, no hay posibilidad de pérdida de memoria. El método fileinput.input() toma una lista de nombres de archivo y, si no se pasa ningún parámetro, acepta la entrada de la entrada estándar. El método devuelve un iterador que devuelve líneas individuales del archivo de texto que se está escaneando.
Implementación de código:
Python3
# import module
import fileinput
import time
#time at the start of program is noted
start = time.time()
#keeps a track of number of lines in the file
count = 0
for lines in fileinput.input(['sample.txt']):
print(lines)
count = count + 1
#time at the end of program execution is noted
end = time.time()
#total time taken to print the file
print("Execution time in seconds: ",(end - start))
print("No. of lines printed: ",count)
Producción:
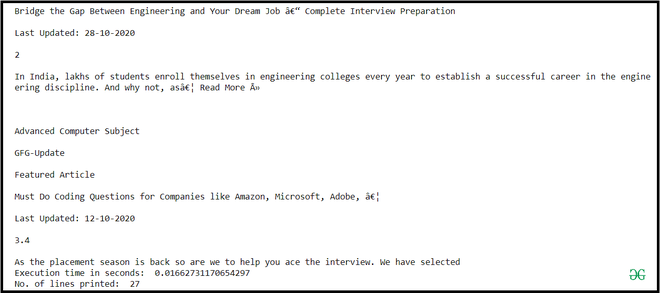
Explicación:
El método input() devuelve un iterador que escanea todo el archivo e imprime cada línea.
Método 2:
El segundo enfoque también usa un iterador para leer el archivo. La única diferencia es que usaremos el iterador de un objeto de archivo. El método utilizado es open() envuelve todo el archivo en un objeto de archivo. A continuación, usamos un iterador para obtener las líneas en el objeto de archivo. Abrimos el archivo en un bloque ‘con’ ya que cierra automáticamente el archivo tan pronto como se ejecuta todo el bloque. A medida que el bloque with se completa, se llama al método __exit__(), que libera los recursos abiertos.
Implementación de código:
Python3
import time
start = time.time()
count = 0
with open("sample.txt") as file:
for line in file:
print(line)
count = count + 1
end = time.time()
print("Execution time in seconds: ",(end-start))
print("No of lines printed: ",count)
Producción:
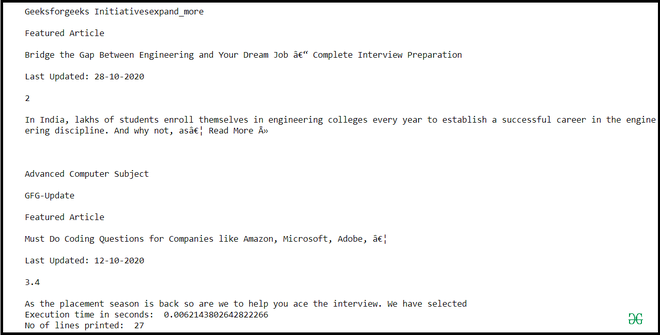
Explicación:
El tiempo requerido en este enfoque es comparativamente menor. Este programa también se puede escribir sin el bloque, pero en ese caso, debemos asegurarnos de cerrar el recurso de archivo explícitamente.
Publicación traducida automáticamente
Artículo escrito por Shreyasi_Chakraborty y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA