En este artículo, aprenderemos cómo seleccionar columnas en el marco de datos de PySpark.
Función utilizada:
En PySpark podemos seleccionar columnas usando la función select() . La función select() nos permite seleccionar una o varias columnas en diferentes formatos.
Sintaxis: dataframe_name.select( column_names )
Nota: estamos especificando nuestra ruta al directorio de chispa usando la función findspark.init() para permitir que nuestro programa encuentre la ubicación de apache spark en nuestra máquina local. Ignore esta línea si está ejecutando el programa en la nube. Supongamos que tenemos nuestra carpeta chispa en la unidad c con el nombre de chispa, por lo que la función se vería así: findspark.init(‘c:/spark’) . No especificar la ruta a veces puede provocar el error py4j.protocol.Py4JError al ejecutar el programa localmente.
Ejemplo 1: seleccione columnas únicas o múltiples
Podemos seleccionar columnas únicas o múltiples usando la función select() especificando el nombre de la columna en particular. Aquí estamos utilizando nuestro conjunto de datos personalizado, por lo que debemos especificar nuestro esquema junto con él para crear el conjunto de datos.
Python3
# select single and multiple columns
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# slelct columns
df.select("Name", "Marks").show()
# stop the session
spark.stop()
Producción:
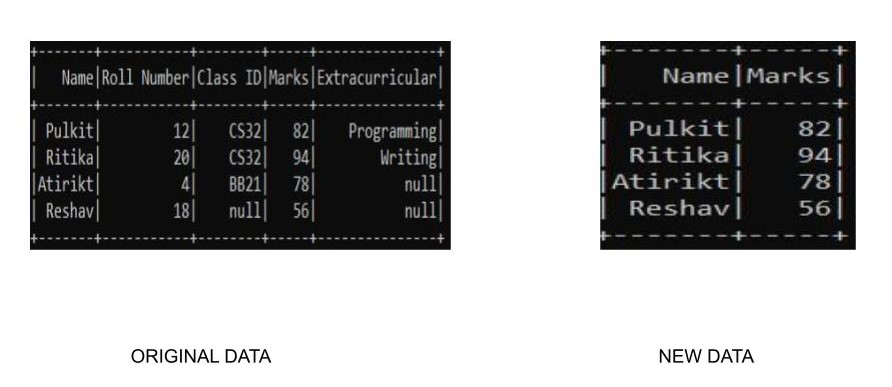
Nota: Hay muchas formas de especificar los nombres de las columnas para la función select(). Aquí usamos «column_name» para especificar la columna. Otras formas incluyen (Todos los ejemplos como se muestra con referencia al código anterior):
- df.select(df.Nombre,df.Marcas)
- df.select(df[“Nombre”],df[“Marcas”])
- Podemos usar la función col() del módulo pyspark.sql.functions para especificar las columnas particulares
Python3
from pyspark.sql.functions import col
df.select(col("Name"),col("Marks")).show()
Nota: Todos los métodos anteriores producirán el mismo resultado que el anterior
Ejemplo 2: Seleccionar columnas usando la indexación
La indexación proporciona una manera fácil de acceder a las columnas dentro de un marco de datos. La indexación comienza desde 0 y tiene números n-1 totales que representan cada columna con 0 como primera y n-1 como última columna n. Podemos usar df.columns para acceder a todas las columnas y usar la indexación para pasar las columnas requeridas dentro de una función de selección. Así es como se verá el código. Estamos utilizando nuestro conjunto de datos personalizado, por lo que debemos especificar nuestro esquema junto con él para crear el conjunto de datos.
Python3
# select spark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# Initialize our data
data2 = [("Pulkit", 12, "CS32", 82, "Programming"),
("Ritika", 20, "CS32", 94, "Writing"),
("Atirikt", 4, "BB21", 78, None),
("Reshav", 18, None, 56, None)
]
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# Define schema
schema = StructType([
StructField("Name", StringType(), True),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# read the dataframe
df = spark.createDataFrame(data=data2, schema=schema)
# select the columns
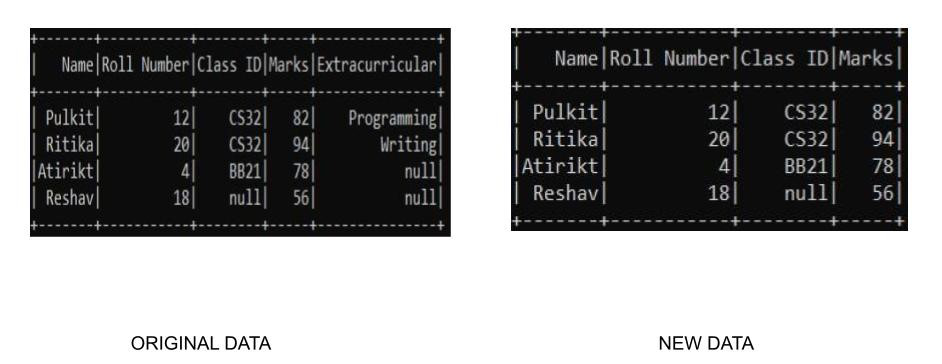
df.select(df.columns[:4]).show()
# stop session
spark.stop()
Producción:
Ejemplo 3: acceder a columnas anidadas de un marco de datos
Al crear un marco de datos, puede haber una tabla en la que tengamos columnas anidadas como, en un nombre de columna «Marcas», podemos tener subcolumnas de marcas internas o externas, o podemos tener columnas separadas para el primer medio y los apellidos en una columna debajo del nombre. Para acceder a las columnas anidadas dentro de un marco de datos usando la función select(), podemos especificar la subcolumna con la columna asociada. Aquí estamos utilizando nuestro conjunto de datos personalizado, por lo que debemos especificar nuestro esquema junto con él para crear el conjunto de datos.
Python3
# findspark
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql import SparkSession
import findspark
findspark.init('c:/spark')
# initialize the data
data = [
(("Pulkit", "Dhingra"), 12, "CS32", 82, "Programming"),
(("Ritika", "Pandey"), 20, "CS32", 94, "Writing"),
(("Atirikt", "Sans"), 4, "BB21", 78, None),
(("Reshav", None), 18, None, 56, None)
]
# start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# initialize the schema of the data
schema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField("Roll Number", IntegerType(), True),
StructField("Class ID", StringType(), True),
StructField("Marks", IntegerType(), True),
StructField("Extracurricular", StringType(), True)
])
# create a dataframe
df2 = spark.createDataFrame(data=data, schema=schema)
# display the schema
df2.printSchema()
# select operation
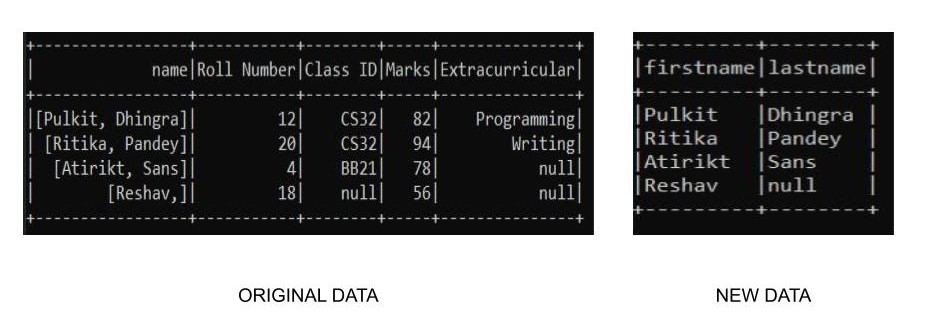
df2.select("name.firstname", "name.lastname").show(truncate=False)
# stop session
spark.stop()
Producción:
Aquí podemos ver que tenemos un conjunto de datos del siguiente esquema
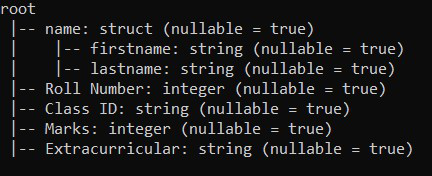
Tenemos un nombre de columna con subcolumnas como nombre y apellido. Ahora, cuando realizamos la operación de selección, tenemos una salida como
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA