En los proyectos reales de ciencia de datos, se tratará con grandes cantidades de datos y se intentarán cosas una y otra vez, por lo que, para mayor eficiencia, utilizamos el concepto Groupby . El concepto Groupby es realmente importante porque su capacidad para agregar datos de manera eficiente, tanto en el rendimiento como en la cantidad de código, es magnífica. Groupby se refiere principalmente a un proceso que involucra uno o más de los siguientes pasos:
- División: es un proceso en el que dividimos los datos en grupos aplicando algunas condiciones en los conjuntos de datos.
- Aplicar: Es un proceso en el que aplicamos una función a cada grupo de forma independiente.
- Combinación: es un proceso en el que combinamos diferentes conjuntos de datos después de aplicar groupby y resultados en una estructura de datos.
Sintaxis: groupby(by=Ninguno, axis=0, level=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parámetros:
- por: mapeo, función, str, o iterable
- eje: int, por defecto 0
- level : si el eje es un MultiIndex (jerárquico), agrupar por un nivel o niveles en particular
- as_index : para la salida agregada, devuelva el objeto con etiquetas de grupo como índice. Solo relevante para la entrada de DataFrame. as_index=False es efectivamente una salida agrupada de «estilo SQL»
- sort : Ordenar claves de grupo. Obtenga un mejor rendimiento desactivando esto. Tenga en cuenta que esto no influye en el orden de las observaciones dentro de cada grupo. groupby conserva el orden de las filas dentro de cada grupo.
- group_keys: al llamar a apply, agregue claves de grupo al índice para identificar piezas
- squeeze : reduce la dimensionalidad del tipo de retorno si es posible, de lo contrario, devuelve un tipo consistente
Devuelve: objeto GroupBy
Aquí, usamos un marco de datos ficticio simple que se muestra a continuación:
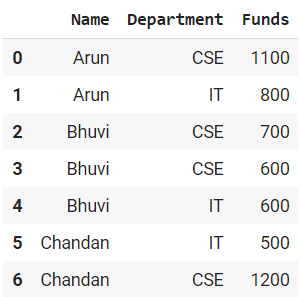
Además, usamos algunos métodos para contar las observaciones del grupo en Pandas que se explican a continuación con ejemplos.
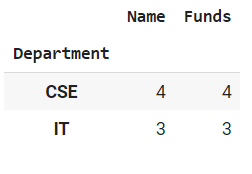
Ejemplo 1: Usar group.count (Contar por una variable)
En este ejemplo, usaremos el método group.count() que cuenta el número total de miembros en cada grupo.
Python3
# import libraries
import pandas as pd
#create pandas DataFrame
df = pd.DataFrame({'Name': ['Arun', 'Arun', 'Bhuvi', 'Bhuvi',
'Bhuvi', 'Chandan', 'Chandan'],
'Department':['CSE', 'IT', 'CSE', 'CSE',
'IT', 'IT', 'CSE'],
'Funds': [1100, 800, 700, 600, 600, 500, 1200]})
# create a group using groupby
group = df.groupby("Department")
# count the observations
group.count()
Producción:
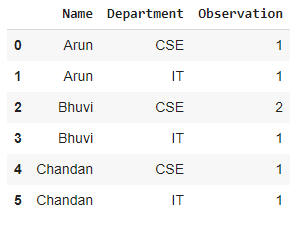
Ejemplo 2: Usar group.size (Recuento por múltiples variables)
En este ejemplo, usaremos las entradas/filas del método group.size()
Python3
# import libraries
import pandas as pd
#create pandas DataFrame
df = pd.DataFrame({'Name': ['Arun', 'Arun', 'Bhuvi', 'Bhuvi',
'Bhuvi', 'Chandan', 'Chandan'],
'Department':['CSE', 'IT', 'CSE', 'CSE',
'IT', 'IT', 'CSE'],
'Funds': [1100, 800, 700, 600, 600, 500, 1200]})
# create a group using groupby
group = df.groupby(['Name', 'Department'])
# size of group to count observations
group = group.size()
# make a column name
group.reset_index(name='Observation')
Producción :
Publicación traducida automáticamente
Artículo escrito por biswasarkadip y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA