El uso del método size() o count() con pandas.DataFrame.groupby() generará el recuento de una cantidad de ocurrencias de datos presentes en una columna particular del marco de datos. Sin embargo, esta operación también se puede realizar usando pandas.Series.value_counts() y pandas.Index.value_counts() .
Acercarse
- Módulo de importación
- Crear o importar marco de datos
- Aplicar grupo por
- Usa cualquiera de los dos métodos.
- Mostrar resultado
Método 1: Usar pandas.groupyby().si ze()
El enfoque básico para usar este método es asignar los nombres de columna como parámetros en el método groupby() y luego usar size() con él. A continuación se muestran varios ejemplos que muestran cómo contar las ocurrencias en una columna para diferentes conjuntos de datos.
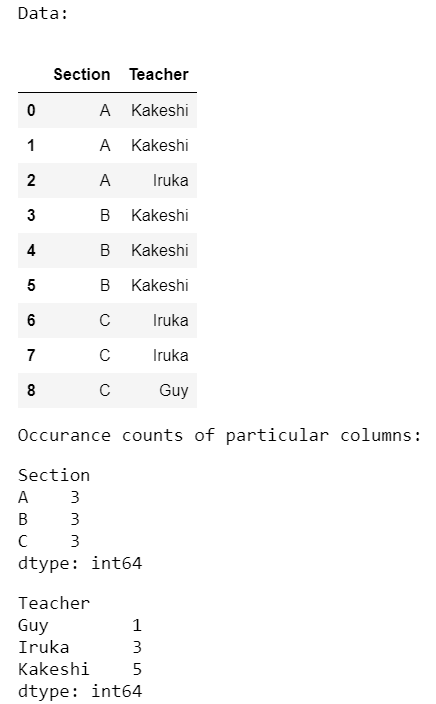
Ejemplo 1:
En este ejemplo, contamos por separado las ocurrencias de todas las columnas presentes en un conjunto de datos.
Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B',
'B', 'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of particular columns:')
# count occurrences a particular column
occur = data.groupby(['Section']).size()
# display occurrences of a particular column
display(occur)
# count occurrences a particular column
occur = data.groupby(['Teacher']).size()
# display occurrences of a particular column
display(occur)
Producción:
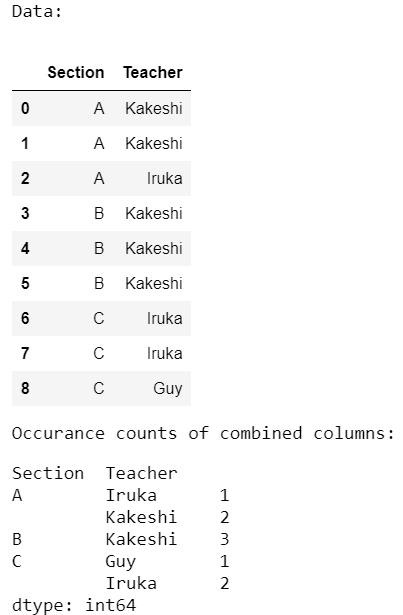
Ejemplo 2:
En el siguiente programa, contamos las ocurrencias de todas las columnas combinadas del mismo conjunto de datos que se usó en el programa anterior.
Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)
Producción:
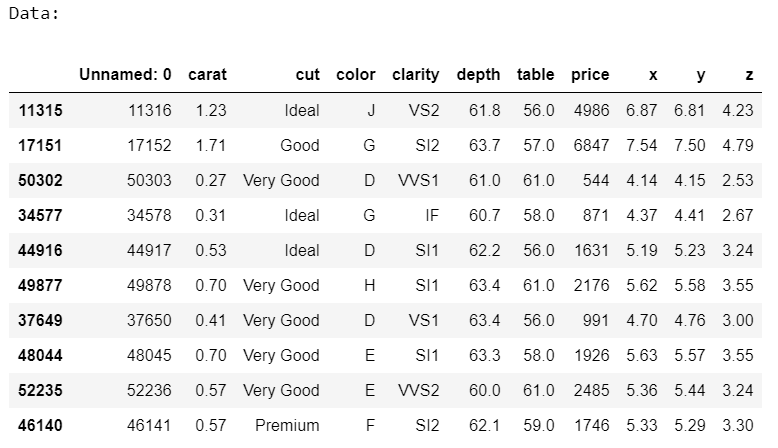
Ejemplo 3:
Aquí, separamos las ocurrencias de recuento y las ocurrencias de recuento combinadas de las columnas categóricas presentes en un archivo CSV .
Python3
# import module
import pandas as pd
# assign data
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
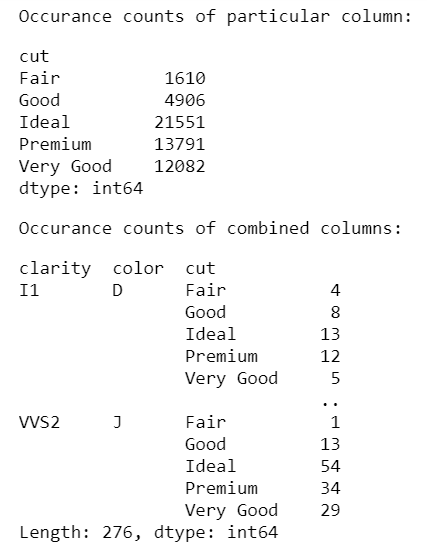
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)
Producción:
Método 2: Usar pandas.groupyby().count ()
El enfoque básico para usar este método es asignar los nombres de las columnas como parámetros en el método groupby() y luego usar count() con él. A continuación se muestran varios ejemplos que muestran cómo contar las ocurrencias en una columna para diferentes conjuntos de datos.
Ejemplo 1:
En este ejemplo, contamos por separado las ocurrencias de todas las columnas presentes en un conjunto de datos.
Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
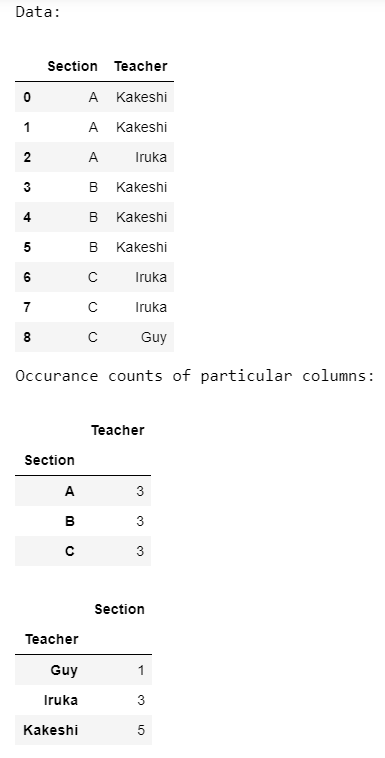
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of particular columns:')
# count occurrences a particular column
occur = data.groupby(['Section']).size()
# display occurrences of a particular column
display(occur)
# count occurrences a particular column
occur = data.groupby(['Teacher']).size()
# display occurrences of a particular column
display(occur)
Producción:
Ejemplo 2:
En el siguiente programa, contamos las ocurrencias de todas las columnas combinadas del mismo conjunto de datos que se usó en el programa anterior.
Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)
Producción:

Ejemplo 3:
Aquí, separamos las ocurrencias de recuento y las ocurrencias de recuento combinadas de las columnas categóricas presentes en un archivo CSV .
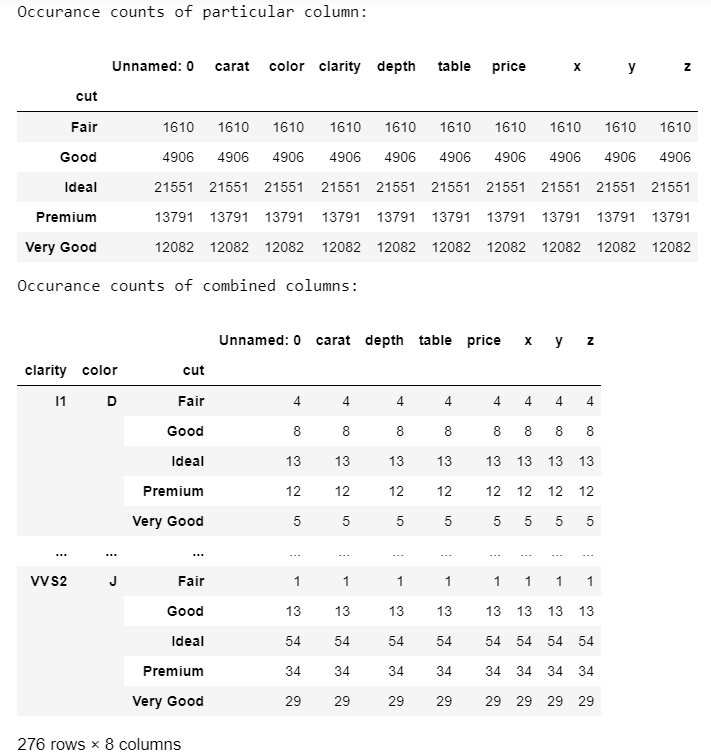
Python3
# import module
import pandas as pd
# assign data
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)
Producción:
Publicación traducida automáticamente
Artículo escrito por riturajsaha y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA