Los sistemas de bases de datos comprenden estructuras de datos complejas. Para hacer que el sistema sea eficiente en términos de recuperación de datos y reducir la complejidad en términos de usabilidad de los usuarios, los desarrolladores utilizan la abstracción, es decir, ocultan detalles irrelevantes a los usuarios. Este enfoque simplifica el diseño de la base de datos.
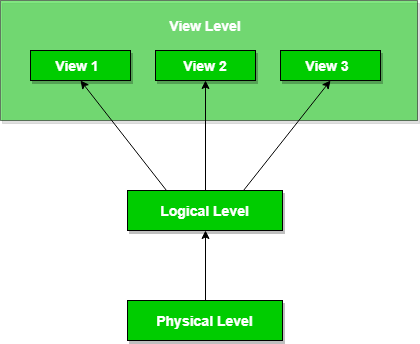
Existen principalmente 3 niveles de abstracción de datos:
Físico : este es el nivel más bajo de abstracción de datos. Nos dice cómo se almacenan realmente los datos en la memoria. Los métodos de acceso como acceso secuencial o aleatorio y métodos de organización de archivos como árboles B+, hash utilizados para los mismos. La usabilidad, el tamaño de la memoria y la cantidad de veces que los registros son factores que debemos conocer al diseñar la base de datos.
Supongamos que necesitamos almacenar los detalles de un empleado. Los bloques de almacenamiento y la cantidad de memoria utilizada para estos fines se mantienen ocultos para el usuario.
Lógico : este nivel comprende la información que realmente se almacena en la base de datos en forma de tablas. También almacena la relación entre las entidades de datos en estructuras relativamente simples. En este nivel, la información disponible para el usuario en el nivel de vista es desconocida.
Podemos almacenar los diversos atributos de un empleado y las relaciones, por ejemplo, con el gerente también se pueden almacenar.
Vista : Este es el nivel más alto de abstracción. Los usuarios solo ven una parte de la base de datos real. Este nivel existe para facilitar el acceso a la base de datos por parte de un usuario individual. Los usuarios ven los datos en forma de filas y columnas. Las tablas y las relaciones se utilizan para almacenar datos. Pueden existir múltiples vistas de la misma base de datos. Los usuarios pueden simplemente ver los datos e interactuar con la base de datos, los detalles de almacenamiento e implementación están ocultos para ellos.
El objetivo principal de la abstracción de datos es lograr la independencia de los datos para ahorrar el tiempo y el costo necesarios cuando se modifica o altera la base de datos.
Tenemos dos niveles de independencia de datos que surgen de estos niveles de abstracción:
Independencia de los datos a nivel físico : se refiere a la característica de poder modificar el esquema físico sin alterar el esquema conceptual o lógico, hecho con fines de optimización, por ejemplo, la estructura conceptual de la base de datos no se vería afectada por ningún cambio en el tamaño de almacenamiento. del servidor del sistema de base de datos. Cambiar de archivos de acceso secuencial a aleatorio es uno de esos ejemplos. Estas alteraciones o modificaciones a la estructura física pueden incluir:
- Uso de nuevos dispositivos de almacenamiento.
- Modificación de las estructuras de datos utilizadas para el almacenamiento.
- Alterar índices o usar técnicas alternativas de organización de archivos, etc.
Independencia de datos a nivel lógico: Se refiere a la característica de poder modificar el esquema lógico sin afectar el esquema externo o programa de aplicación. La vista del usuario de los datos no se vería afectada por ningún cambio en la vista conceptual de los datos. Estos cambios pueden incluir la inserción o eliminación de atributos, la alteración de estructuras de tablas, entidades o relaciones con el esquema lógico, etc.
Este artículo es una contribución de Avneet Kaur . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA