En este artículo, vamos a aprender cómo crear su propio lenguaje de programación usando SLY (Sly Lex Yacc) y Python. Antes de profundizar en este tema, se debe tener en cuenta que este no es un tutorial para principiantes y que debe tener algún conocimiento de los requisitos previos que se detallan a continuación.
requisitos previos
- Conocimientos básicos sobre diseño de compiladores.
- Comprensión básica del análisis léxico, el análisis sintáctico y otros aspectos del diseño del compilador.
- Comprensión de expresiones regulares.
- Familiaridad con el lenguaje de programación Python.
Empezando
Instale SLY para Python. SLY es una herramienta de lectura y análisis que facilita mucho nuestro proceso.
pip install sly
Construyendo un Lexer
La primera fase de un compilador es convertir todos los flujos de caracteres (el programa de alto nivel que se escribe) en flujos de tokens. Esto se hace mediante un proceso llamado análisis léxico. Sin embargo, este proceso se simplifica usando SLY
Primero importemos todos los módulos necesarios.
Python3
from sly import Lexer
Ahora construyamos una clase BasicLexer que extienda la clase Lexer de SLY. Hagamos un compilador que haga operaciones aritméticas simples. Por lo tanto, necesitaremos algunos tokens básicos como NOMBRE , NÚMERO , CADENA . En cualquier lenguaje de programación, habrá un espacio entre dos caracteres. Por lo tanto, creamos un literal de ignorar . Luego, también creamos los literales básicos como ‘=’, ‘+’, etc. Los tokens de NOMBRE son básicamente nombres de variables, que se pueden definir mediante la expresión regular [a-zA-Z_][a-zA-Z0-9_] *. Los tokens STRING son valores de string y están delimitados por comillas (» «). Esto se puede definir mediante la expresión regular \».*?\».
Siempre que encontremos un dígito/s, debemos asignarlo al token NÚMERO y el número debe almacenarse como un número entero. Estamos haciendo un script programable básico, así que solo hagámoslo con números enteros, sin embargo, siéntase libre de extender lo mismo para decimales, largos, etc. También podemos hacer comentarios. Cada vez que encontramos «//», ignoramos lo que viene a continuación en esa línea. Hacemos lo mismo con el carácter de nueva línea. Por lo tanto, hemos construido un lexer básico que convierte el flujo de caracteres en un flujo de tokens.
Python3
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = '\t '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
# Define tokens as regular expressions
# (stored as raw strings)
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'\".*?\"'
# Number token
@_(r'\d+')
def NUMBER(self, t):
# convert it into a python integer
t.value = int(t.value)
return t
# Comment token
@_(r'//.*')
def COMMENT(self, t):
pass
# Newline token(used only for showing
# errors in new line)
@_(r'\n+')
def newline(self, t):
self.lineno = t.value.count('\n')
Construyendo un analizador
Primero importemos todos los módulos necesarios.
Python3
from sly import Parser
Ahora construyamos una clase BasicParser que amplíe la clase Lexer . El flujo de tokens de BasicLexer se pasa a tokens variables . Se define la precedencia, que es la misma para la mayoría de los lenguajes de programación. La mayor parte del análisis escrito en el siguiente programa es muy simple. Cuando no hay nada, el enunciado no pasa nada. Esencialmente, puede presionar enter en su teclado (sin escribir nada) e ir a la siguiente línea. A continuación, su idioma debe comprender las tareas que usan el «=». Esto se maneja en la línea 18 del programa a continuación. Se puede hacer lo mismo cuando se asigna a una string.
Python3
class BasicParser(Parser):
#tokens are passed from lexer to parser
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
El analizador también debe analizar operaciones aritméticas, esto se puede hacer mediante expresiones. Digamos que quieres algo como lo que se muestra a continuación. Aquí, todos ellos se convierten en flujo de tokens línea por línea y se analizan línea por línea. Por lo tanto, según el programa anterior, a = 10 se asemeja a la línea 22. Lo mismo para b =20. a + b se parece a la línea 34, que devuelve un árbol de análisis (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Ahora hemos convertido los flujos de tokens en un árbol de análisis. El siguiente paso es interpretarlo.
Ejecución
La interpretación es un procedimiento sencillo. La idea básica es tomar el árbol y recorrerlo para evaluar las operaciones aritméticas jerárquicamente. Este proceso se llama recursivamente una y otra vez hasta que se evalúa todo el árbol y se recupera la respuesta. Digamos, por ejemplo, 5 + 7 + 4. Este flujo de caracteres primero se convierte en token en un lexer. A continuación, el flujo de tokens se analiza para formar un árbol de análisis. El árbol de análisis esencialmente devuelve (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (ver imagen abajo)
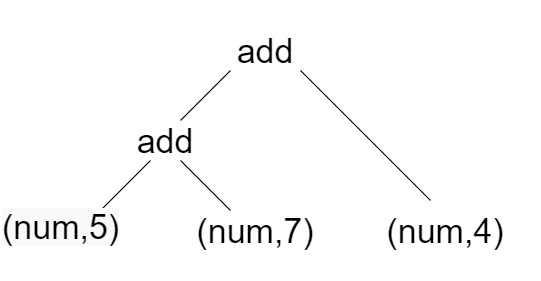
El intérprete sumará primero 5 y 7 y luego llamará recursivamente a walkTree y sumará 4 al resultado de la suma de 5 y 7. Por lo tanto, obtendremos 16. El siguiente código realiza el mismo proceso.
Python3
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0
Visualización de la salida
Para mostrar la salida del intérprete, debemos escribir algunos códigos. El código primero debe llamar al lexer, luego al analizador y luego al intérprete y finalmente recupera la salida. La salida se muestra en el shell.
Python3
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
Es necesario saber que no hemos manejado ningún error. Entonces, SLY mostrará sus mensajes de error cada vez que haga algo que no esté especificado por las reglas que ha escrito.
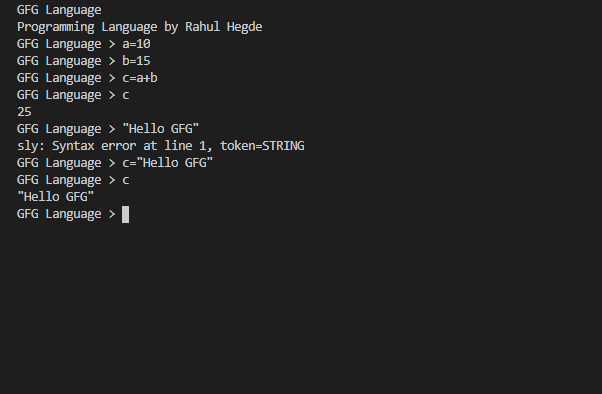
Ejecuta el programa que has escrito usando,
python you_program_name.py
notas al pie
El intérprete que construimos es muy básico. Esto, por supuesto, se puede extender para hacer mucho más. Se pueden agregar bucles y condicionales. Se pueden implementar características de diseño modulares u orientadas a objetos. La integración de módulos, las definiciones de métodos, los parámetros de los métodos son algunas de las características que se pueden extender al mismo.
Publicación traducida automáticamente
Artículo escrito por rahulhegde97 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA