Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
Pandas groupby se utiliza para agrupar los datos según las categorías y aplicar una función a las categorías. También ayuda a agregar datos de manera eficiente.
La función Pandas dataframe.groupby()se utiliza para dividir los datos en grupos según algunos criterios. Los objetos pandas se pueden dividir en cualquiera de sus ejes. La definición abstracta de agrupación es proporcionar un mapeo de etiquetas a nombres de grupos.
Sintaxis: DataFrame.groupby(by=Ninguno, axis=0, level=Ninguno, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parámetros:
por: mapeo, función, string o
eje iterable: int,
nivel predeterminado 0: si el eje es un índice múltiple (jerárquico), agrupar por un nivel o niveles en particular
as_index: para la salida agregada, devolver el objeto con etiquetas de grupo como el índice. Solo relevante para la entrada de DataFrame. as_index=False es efectivamente una ordenación de salida agrupada de «estilo SQL»
: Ordenar claves de grupo. Obtenga un mejor rendimiento desactivando esto. Tenga en cuenta que esto no influye en el orden de las observaciones dentro de cada grupo. groupby conserva el orden de las filas dentro de cada grupo.
group_keys: al llamar a apply, agregue claves de grupo al índice para identificar las piezas
Reduzca la dimensionalidad del tipo de devolución si es posible; de lo contrario, devuelva un tipo consistenteDevuelve: objeto GroupBy
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí
Ejemplo #1: Utilice groupby()la función para agrupar los datos según el «Equipo».
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
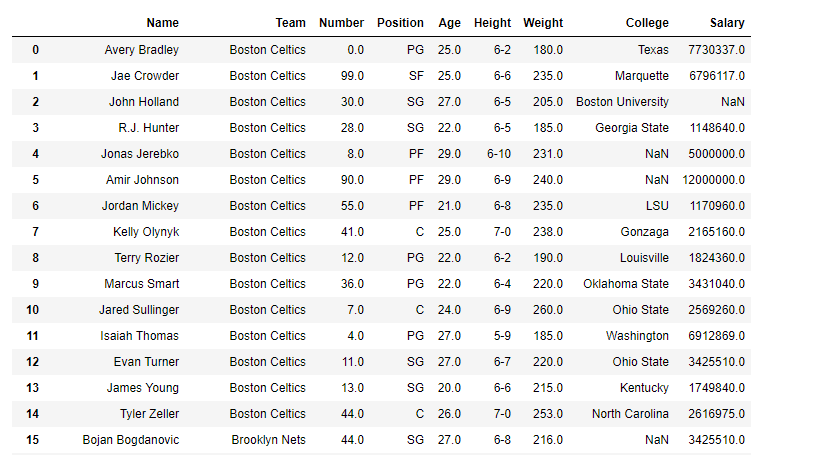
Ahora aplica la groupby()función.
# applying groupby() function to
# group the data on team value.
gk = df.groupby('Team')
# Let's print the first entries
# in all the groups formed.
gk.first()
Producción :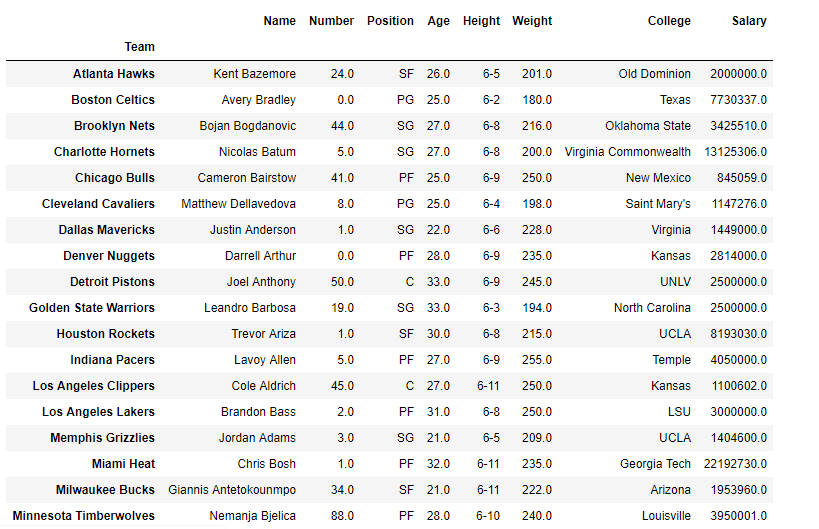
Imprimamos el valor contenido en cualquiera de los grupos. Para eso usa el nombre del equipo. Usamos la función get_group()para encontrar las entradas contenidas en cualquiera de los grupos.
# Finding the values contained in the "Boston Celtics" group
gk.get_group('Boston Celtics')
Salida: 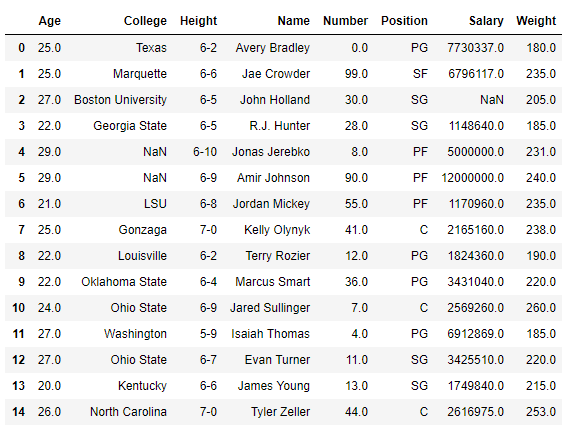
Ejemplo n.º 2: utilice groupby()la función para formar grupos en función de más de una categoría (es decir, utilice más de una columna para realizar la división).
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# First grouping based on "Team"
# Within each team we are grouping based on "Position"
gkk = df.groupby(['Team', 'Position'])
# Print the first value in each group
gkk.first()
Producción :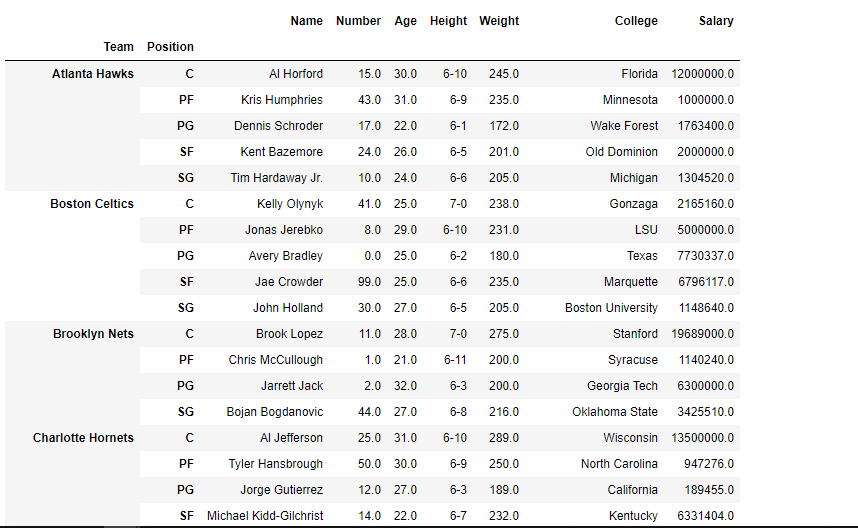
groupby()es una función muy poderosa con muchas variaciones. Hace que la tarea de dividir el marco de datos sobre algunos criterios sea realmente fácil y eficiente.
Publicación traducida automáticamente
Artículo escrito por Shubham__Ranjan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA