Es un hecho bien establecido que la ordenación por fusión se ejecuta más rápido que la ordenación por inserción. Usando el análisis asintótico, podemos probar que la clasificación por fusión se ejecuta en el tiempo O (nlogn) y la clasificación por inserción toma O (n ^ 2). Es obvio porque la ordenación por fusión utiliza un enfoque de divide y vencerás al resolver recursivamente los problemas donde la ordenación por inserción sigue un enfoque incremental.
Si escudriñamos aún más el análisis de la complejidad del tiempo, sabremos que la ordenación por inserción no es lo suficientemente mala. Sorprendentemente, la ordenación por inserción supera a la ordenación por fusión en tamaños de entrada más pequeños. Esto se debe a que hay pocas constantes que ignoramos al deducir la complejidad del tiempo. En tamaños de entrada más grandes del orden de 10 ^ 4, esto no influye en el comportamiento de nuestra función. Pero cuando los tamaños de entrada caen por debajo, digamos menos de 40, entonces las constantes en la ecuación dominan el tamaño de entrada ‘n’.
Hasta aquí todo bien. Pero no estaba satisfecho con tal análisis matemático. Como estudiante de informática, debemos creer en escribir código. He escrito un programa en C para tener una idea de cómo los algoritmos compiten entre sí para varios tamaños de entrada. Y también, por qué se realiza un análisis matemático tan riguroso para establecer las complejidades del tiempo de ejecución de estos algoritmos de clasificación.
Implementación:
//C++ code to compare performance of sorting algorithms
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <time.h>
#define MAX_ELEMENT_IN_ARRAY 1000000001
int cmpfunc (const void * a, const void * b)
{
// Compare function used by qsort
return ( *(int*)a - *(int*)b );
}
int* generate_random_array(int n)
{
srand(time(NULL));
int *a = malloc(sizeof(int) * n), i;
for(i = 0; i < n; ++i)
a[i] = rand() % MAX_ELEMENT_IN_ARRAY;
return a;
}
int* copy_array(int a[], int n)
{
int *arr = malloc(sizeof(int) * n);
int i;
for(i = 0; i < n ;++i)
arr[i] = a[i];
return arr;
}
//Code for Insertion Sort
void insertion_sort_asc(int a[], int start, int end)
{
int i;
for(i = start + 1; i <= end ; ++i)
{
int key = a[i];
int j = i - 1;
while(j >= start && a[j] > key)
{
a[j + 1] = a[j];
--j;
}
a[j + 1] = key;
}
}
//Code for Merge Sort
void merge(int a[], int start, int end, int mid)
{
int i = start, j = mid + 1, k = 0;
int *aux = malloc(sizeof(int) * (end - start + 1));
while(i <= mid && j <= end)
{
if(a[i] <= a[j])
aux[k++] = a[i++];
else
aux[k++] = a[j++];
}
while(i <= mid)
aux[k++] = a[i++];
while(j <= end)
aux[k++] = a[j++];
j = 0;
for(i = start;i <= end;++i)
a[i] = aux[j++];
free(aux);
}
void _merge_sort(int a[],int start,int end)
{
if(start < end)
{
int mid = start + (end - start) / 2;
_merge_sort(a,start,mid);
_merge_sort(a,mid + 1,end);
merge(a,start,end,mid);
}
}
void merge_sort(int a[],int n)
{
return _merge_sort(a,0,n - 1);
}
void insertion_and_merge_sort_combine(int a[], int start, int end, int k)
{
// Performs insertion sort if size of array is less than or equal to k
// Otherwise, uses mergesort
if(start < end)
{
int size = end - start + 1;
if(size <= k)
{
//printf("Performed insertion sort- start = %d and end = %d\n", start, end);
return insertion_sort_asc(a,start,end);
}
int mid = start + (end - start) / 2;
insertion_and_merge_sort_combine(a,start,mid,k);
insertion_and_merge_sort_combine(a,mid + 1,end,k);
merge(a,start,end,mid);
}
}
void test_sorting_runtimes(int size,int num_of_times)
{
// Measuring the runtime of the sorting algorithms
int number_of_times = num_of_times;
int t = number_of_times;
int n = size;
double insertion_sort_time = 0, merge_sort_time = 0;
double merge_sort_and_insertion_sort_mix_time = 0, qsort_time = 0;
while(t--)
{
clock_t start, end;
int *a = generate_random_array(n);
int *b = copy_array(a,n);
start = clock();
insertion_sort_asc(b,0,n-1);
end = clock();
insertion_sort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(b);
int *c = copy_array(a,n);
start = clock();
merge_sort(c,n);
end = clock();
merge_sort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(c);
int *d = copy_array(a,n);
start = clock();
insertion_and_merge_sort_combine(d,0,n-1,40);
end = clock();
merge_sort_and_insertion_sort_mix_time+=((double) (end - start))/CLOCKS_PER_SEC;
free(d);
start = clock();
qsort(a,n,sizeof(int),cmpfunc);
end = clock();
qsort_time += ((double) (end - start)) / CLOCKS_PER_SEC;
free(a);
}
insertion_sort_time /= number_of_times;
merge_sort_time /= number_of_times;
merge_sort_and_insertion_sort_mix_time /= number_of_times;
qsort_time /= number_of_times;
printf("\nTime taken to sort:\n"
"%-35s %f\n"
"%-35s %f\n"
"%-35s %f\n"
"%-35s %f\n\n",
"(i)Insertion sort: ",
insertion_sort_time,
"(ii)Merge sort: ",
merge_sort_time,
"(iii)Insertion-mergesort-hybrid: ",
merge_sort_and_insertion_sort_mix_time,
"(iv)Qsort library function: ",
qsort_time);
}
int main(int argc, char const *argv[])
{
int t;
scanf("%d", &t);
while(t--)
{
int size, num_of_times;
scanf("%d %d", &size, &num_of_times);
test_sorting_runtimes(size,num_of_times);
}
return 0;
}
He comparado los tiempos de ejecución de los siguientes algoritmos:
- Clasificación por inserción : El algoritmo tradicional sin modificaciones/optimización. Funciona muy bien para tamaños de entrada más pequeños. Y sí, supera la ordenación por combinación
- Merge sort : sigue el enfoque divide y vencerás. Para tamaños de entrada del orden de 10^5, este algoritmo es la elección correcta. Hace que la ordenación por inserción no sea práctica para tamaños de entrada tan grandes.
- Versión combinada de ordenación por inserción y ordenación por fusión: modifiqué un poco la lógica de la ordenación por fusión para lograr un tiempo de ejecución considerablemente mejor para tamaños de entrada más pequeños. Como sabemos, la ordenación por fusión divide su entrada en dos mitades hasta que es lo suficientemente trivial como para ordenar los elementos. Pero aquí, cuando el tamaño de entrada cae por debajo de un umbral como ‘n’ < 40, este algoritmo híbrido realiza una llamada al procedimiento tradicional de ordenación por inserción. Debido al hecho de que la ordenación por inserción se ejecuta más rápido en entradas más pequeñas y la ordenación por fusión se ejecuta más rápido en entradas más grandes, este algoritmo hace un mejor uso de ambos mundos.
- Clasificación rápida: no he implementado este procedimiento. Esta es la función de biblioteca qsort() que está disponible en
. He considerado este algoritmo para conocer el significado de la implementación. Se requiere una gran experiencia en programación para minimizar la cantidad de pasos y hacer el máximo uso de las primitivas del lenguaje subyacente para implementar un algoritmo de la mejor manera posible. Esta es la razón principal por la que se recomienda utilizar funciones de biblioteca. Están escritos para manejar cualquier cosa y todo. Optimizan al máximo posible. Y antes de que me olvide, según mi análisis, qsort() se ejecuta increíblemente rápido en prácticamente cualquier tamaño de entrada.
El analisis:
- Entrada: el usuario debe proporcionar la cantidad de veces que desea probar el algoritmo correspondiente a la cantidad de casos de prueba. Para cada caso de prueba, el usuario debe ingresar dos números enteros separados por espacios que indican el tamaño de entrada ‘n’ y ‘num_of_times’ que indica la cantidad de veces que desea ejecutar el análisis y sacar el promedio. (Aclaración: si ‘num_of_times’ es 10, cada uno de los algoritmos especificados anteriormente se ejecuta 10 veces y se toma el promedio. Esto se hace porque la array de entrada se genera aleatoriamente correspondiente al tamaño de entrada que especifica. La array de entrada podría ser todo ordenado. Nuestro podría corresponder al peor de los casos, es decir, orden descendente. Para evitar los tiempos de ejecución de tales arrays de entrada. El algoritmo se ejecuta ‘num_of_times’ y se toma el promedio.
) La rutina clock() y la macro CLOCKS_PER_SEC dese utiliza para medir el tiempo empleado.
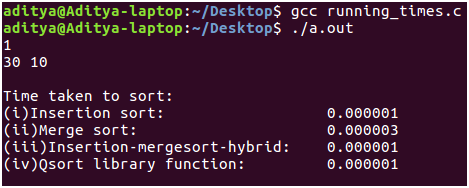
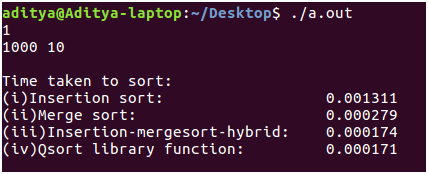
Compilación: he escrito el código anterior en un entorno Linux (Ubuntu 16.04 LTS). Copie el fragmento de código anterior. ¡Compile usando gcc, ingrese las entradas como se especifica y admire el poder de los algoritmos de clasificación! - Resultados: como puede ver para tamaños de entrada pequeños, la ordenación por inserción supera a la ordenación por fusión en 2 * 10^-6 segundos. Pero esta diferencia en el tiempo no es tan significativa. Por otro lado, el algoritmo híbrido y la función de biblioteca qsort() funcionan tan bien como la ordenación por inserción. El tamaño de entrada ahora se incrementa aproximadamente 100 veces a n = 1000 desde n = 30. La diferencia ahora es tangible. La ordenación por combinación se ejecuta 10 veces más rápido que la ordenación por inserción. De nuevo hay un empate entre el rendimiento del algoritmo híbrido y la rutina qsort(). Esto sugiere que qsort() se implementa de una manera que es más o menos similar a nuestro algoritmo híbrido, es decir, cambiando entre diferentes algoritmos para aprovecharlos al máximo.
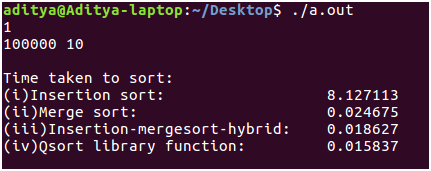
Finalmente, el tamaño de entrada se incrementa a 10 ^ 5 (¡1 Lakh!) Que es probablemente el tamaño ideal utilizado en escenarios prácticos. En comparación con la entrada anterior n = 1000, donde la ordenación por combinación venció a la ordenación por inserción al ejecutarse 10 veces más rápido, aquí la diferencia es aún más significativa. ¡La ordenación por combinación supera a la ordenación por inserción 100 veces!
El algoritmo híbrido que hemos escrito, de hecho, supera la ordenación por fusión tradicional al ejecutarse 0,01 segundos más rápido. Y, por último, qsort(), la función de biblioteca, finalmente nos demuestra que la implementación también juega un papel crucial al medir meticulosamente los tiempos de ejecución al ejecutarse 3 milisegundos más rápido. 😀
Nota: No ejecute el programa anterior con n >= 10^6 ya que requerirá mucha potencia informática. ¡Gracias y feliz codificación! 🙂
Este artículo es una contribución de Aditya Ch . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA