En este artículo, discutiremos cómo reorganizar o reordenar la columna del marco de datos usando el paquete dplyr en el lenguaje de programación R.
Creando Dataframe para demostración:
R
# load the package
library(dplyr)
# create the dataframe with three columns
# id , department and salary with 8 rows
data = data.frame(id = c(7058, 7059, 7060, 7089,
7072, 7078, 7093, 7034),
department = c('IT','sales','finance',
'IT','finance','sales',
'HR','HR'),
salary = c(34500.00, 560890.78, 67000.78,
25000.00, 78900.00, 25000.00,
45000.00, 90000))
# display dataframe
data
Producción:
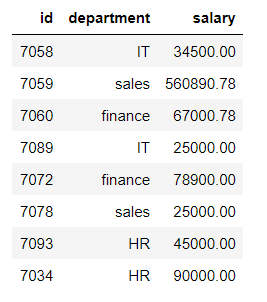
Método 1: Usando el método select()
Vamos a usar un método select() para reordenar las columnas.
Sintaxis: seleccionar (marco de datos, columnas)
dónde
- dataframe es el dataframe de entrada
- las columnas son las columnas de entrada que se reordenarán
Aquí estamos reorganizando el marco de datos (id, departamento, salario) a (salario, id, departamento)
R
print("Before: ")
data
print("After: ")
# reorder the columns using select
select(data, salary, id, department)
Producción:
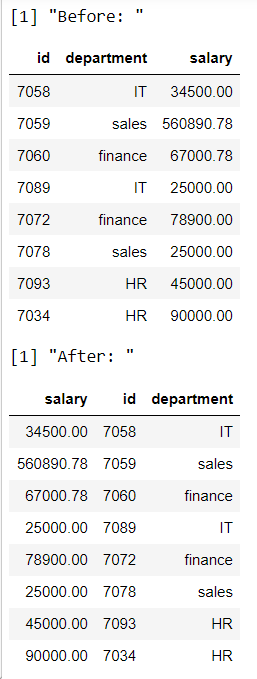
Método 2: reorganizar la columna del marco de datos por posición de columna.
Aquí, reorganizaremos las columnas usando el índice/posición de la columna. Así que usaremos el método de selección para hacer esto.
Nota: el índice/posición de la columna comienza con 1
Sintaxis : select(dataframe.index_positions)
Dónde,
- dataframe es el dataframe de entrada
- index_positions son posiciones de columna que se reorganizarán
Aquí estamos reorganizando en diferentes posiciones.
R
# display actual dataframe
print("actual dataframe")
print(data)
print("reorder the column with position")
# reorder the columns with column positions
# using select
print(select(data,3,1,2))
Producción:
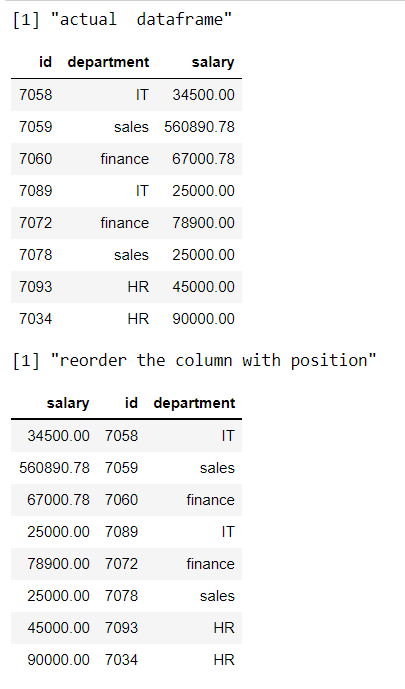
Método 3: reorganizar o reordenar el nombre de la columna alfabéticamente
Aquí estamos usando la función order() junto con la función select() para reorganizar las columnas en orden alfabético. Entonces ordenaremos las columnas usando la función colnames.
Sintaxis: dataframe %>% select(order(colnames(dataframe)))
dónde,
- dataframe es el dataframe de entrada
- %>% es el operador de tubería para pasar el resultado al marco de datos
- order() se usa para reorganizar las columnas del marco de datos en orden alfabético
- colnames() es la función para obtener las columnas en el marco de datos
Aquí estamos reorganizando los datos según los nombres de las columnas en orden alfabético.
R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in alphabetic
# order
data %>% select(order(colnames(data)))
Producción:
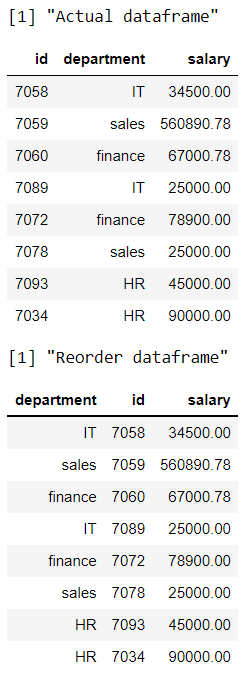
Método 4: reorganizar o reordenar el nombre de la columna en orden alfabético inverso
entonces ordenaremos las columnas usando la función colnames a la inversa.
Sintaxis: dataframe %>% select(order(colnames(dataframe),decreasing=TRUE))
dónde,
- dataframe es el dataframe de entrada
- %>% es el operador de tubería para pasar el resultado al marco de datos
- order() se usa para reorganizar las columnas del marco de datos en orden alfabético
- colnames() es la función para obtener las columnas en el marco de datos
- El parámetro decreciente = VERDADERO especifica ordenar el marco de datos en orden descendente
Aquí estamos reorganizando los datos según los nombres de las columnas en orden alfabético inverso.
R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in reverse alphabetic order
data %>% select(order(colnames(data),
decreasing = TRUE))
Producción:
Método 5: Mueva o cambie la columna a la Primera posición/última posición en R
Vamos a usar el método everything() para cambiar la columna a la primera, de esta manera, podemos reorganizar el marco de datos.
Sintaxis: trama de datos %>% select(nombre_columna, todo())
dónde,
- dataframe es el dataframe de entrada
- column_name es la columna que se desplazará primero
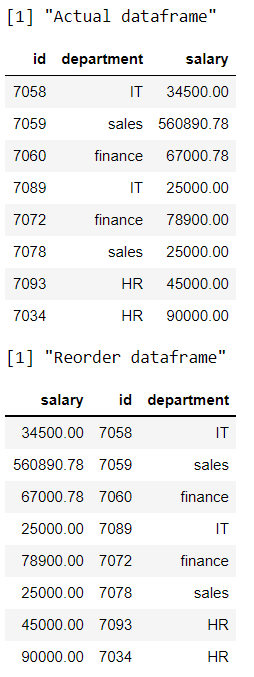
Programa R para cambiar la columna del departamento como primera
R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# getting department column as first
data %>% select(department, everything())
Producción:
Método 6: Usando dplyr arreglar()
Aquí vamos a reorganizar las filas en función de una columna en particular en orden ascendente usando la función de arreglo()
Sintaxis: trama de datos %>% arreglar (nombre_columna)
Dónde
- dataframe es el dataframe de entrada
- column_name es la columna en la que las filas del marco de datos se organizan en función de esta columna
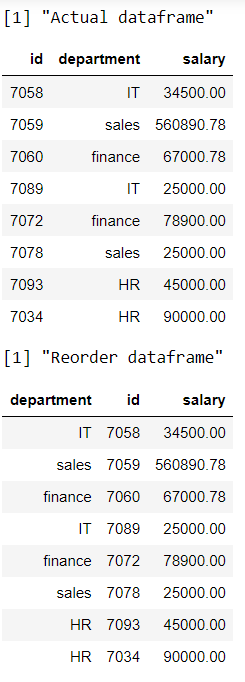
Programa R para reorganizar las filas según la columna del departamento
R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on department column
data %>% arrange(department)
Producción:
Método 7: Usar el método dplyr Organize() y des()
Aquí vamos a reorganizar las filas en función de una columna en particular en orden ascendente usando la función de arreglo() junto con la función desc().
Sintaxis: marco de datos %>% arreglar (desc (nombre_columna))
Dónde
- dataframe es el dataframe de entrada
- column_name es la columna en la que las filas del marco de datos se organizan en función de esta columna en orden descendente
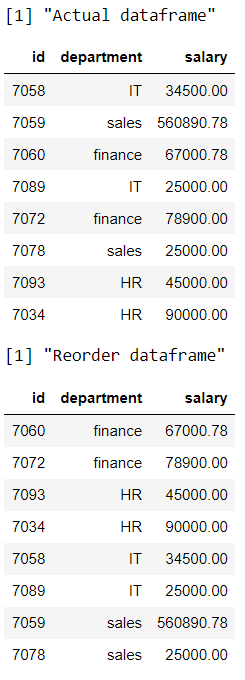
R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on salary
# column in descending order
data %>% arrange(desc(salary))
Producción:
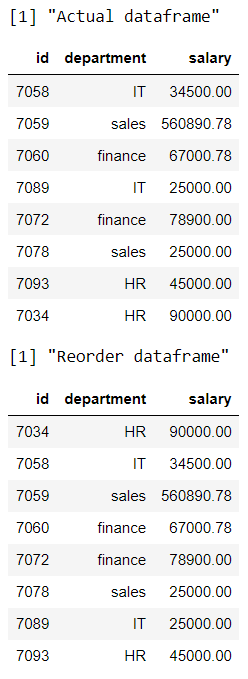
Método 8: Uso de la función Organize_all() en R dplyr
Aquí vamos a organizar/reordenar las filas en función de múltiples variables en el marco de datos, por lo que estamos usando la función Organize_all()
Sintaxis: organizar_todos (marco de datos)
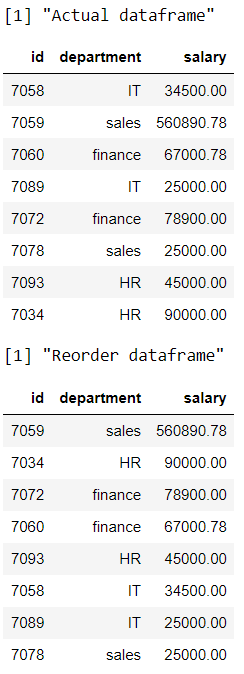
R
print("Actual dataframe")
# display actual dataframe
data
print("Reorder dataframe")
# rearrange multiple columns
arrange_all(data)
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA