Como sabemos, el selenium es una herramienta de automatización basada en la web que nos ayuda a automatizar los navegadores. Selenium es una herramienta de prueba de código abierto, lo que significa que podemos descargarla fácilmente de Internet y usarla. Con la ayuda de Selenium, también podemos eliminar los datos de las páginas web. Aquí, en este artículo, vamos a discutir cómo desechar varias páginas usando selenium.
Puede haber muchas formas de extraer los datos de las páginas web, discutiremos una de ellas. Recorrer el número de página es la forma más sencilla de raspar los datos. Podemos usar un contador incremental para cambiar una página a otra página. Como muchas veces, nuestro bucle se ejecutará, el programa eliminará los datos de las páginas web.
URL de la primera página:
https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=1
Por último, los números de página únicos se incrementarán como página = 1, página = 2 … Ahora, veamos la URL de la segunda página.
URL de la segunda página:
https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2
Ahora, analicemos el enfoque.
Instalación:
Nuestro primer paso, antes de escribir una sola línea de código. Tenemos que instalar el selenium para usar la clase webdriver . A través del cual podemos instanciar los navegadores y obtener la página web de la URL de destino.
pip install selenium
Una vez que selenium se instaló correctamente. Ahora, podemos ir al siguiente paso para instalar nuestro próximo paquete.
El siguiente paquete es webdriver_manager, instálelo primero,
pip install webdriver_manager
¡Sí! Hemos terminado con la instalación de paquetes importantes o necesarios.
Ahora, veamos la implementación a continuación:
- Aquí en este programa, con la ayuda de for loop, eliminaremos dos páginas web porque estamos ejecutando for loop solo dos veces. Si queremos desechar más páginas, podemos aumentar el recuento de bucles.
- Almacene la URL de la página en una variable de string page_url e incremente su recuento de números de página utilizando el contador de bucle for.
- Ahora, cree una instancia del navegador web Chrome
- Abra la URL de la página en el navegador Chrome usando el objeto del controlador
- Ahora, raspando datos de la página web usando localizadores de elementos como el método find_elements_by_class_name . Este método devolverá una lista de tipos de elementos. Almacenaremos todos los datos necesarios dentro de la variable de la lista, como el título, el precio, la descripción y la calificación .
- Almacene todos los datos como lista de lista de un solo producto. En element_list, almacenaremos esta lista resultante.
- Finalmente, imprime la lista de elementos . Luego cierre el objeto controlador.
Python3
# importing necessary packages
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# for holding the resultant list
element_list = []
for page in range(1, 3, 1):
page_url = "https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=" + str(page)
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(page_url)
title = driver.find_elements_by_class_name("title")
price = driver.find_elements_by_class_name("price")
description = driver.find_elements_by_class_name("description")
rating = driver.find_elements_by_class_name("ratings")
for i in range(len(title)):
element_list.append([title[i].text, price[i].text, description[i].text, rating[i].text])
print(element_list)
#closing the driver
driver.close()
Producción:
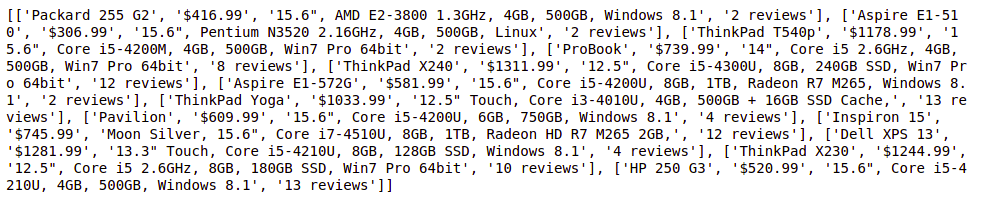
Almacenamiento de datos en un archivo de Excel:
Ahora, almacenaremos los datos de element_list en un archivo de Excel usando el paquete xlsxwriter . Entonces, primero, tenemos que instalar este paquete xlsxwriter .
pip install xlsxwriter
Una vez que la instalación esté lista. Veamos el código simple a través del cual podemos convertir la lista de elementos en un archivo de Excel .
Python3
with xlsxwriter.Workbook('result.xlsx') as workbook:
worksheet = workbook.add_worksheet()
for row_num, data in enumerate(element_list):
worksheet.write_row(row_num, 0, data)
Primero, estamos creando un libro de trabajo llamado result.xlsx . Después de eso, consideraremos la lista de un solo producto como una sola fila . Enumere la lista como una fila y sus datos como columnas dentro del archivo de Excel que comienza como un número de fila 0 y un número de columna 0.
Ahora, veamos su implementación:
Python3
import xlsxwriter
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
element_list = []
for page in range(1, 3, 1):
page_url = "https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=" + str(page)
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(page_url)
title = driver.find_elements_by_class_name("title")
price = driver.find_elements_by_class_name("price")
description = driver.find_elements_by_class_name("description")
rating = driver.find_elements_by_class_name("ratings")
for i in range(len(title)):
element_list.append([title[i].text, price[i].text, description[i].text, rating[i].text])
with xlsxwriter.Workbook('result.xlsx') as workbook:
worksheet = workbook.add_worksheet()
for row_num, data in enumerate(element_list):
worksheet.write_row(row_num, 0, data)
driver.close()
Producción:

Archivo de salida.
Haga clic aquí para descargar el archivo de salida.
Publicación traducida automáticamente
Artículo escrito por shubhanshuarya007 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA