En este artículo, explicaremos cómo podemos contar la frecuencia de los conjuntos de elementos en el marco de datos dado en Pandas. Usando el método count(), size(), Series.value_counts() y pandas.Index.value_counts() podemos contar el número de frecuencia de los conjuntos de elementos en el DataFrame dado. Aquí, vamos a explicar varios ejemplos de cómo usar estas funciones en la práctica.
Datos sin procesar:
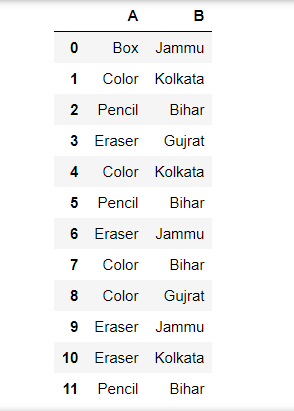
Ejemplo 1:
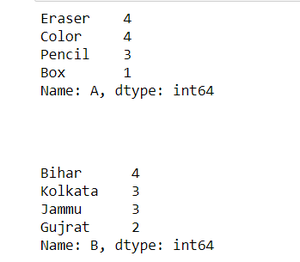
Usando Series.value_counts(): Este método es aplicable al objeto pandas.Series. Dado que cada objeto DataFrame es una colección de objetos Series, podemos aplicar este método para obtener los recuentos de frecuencia de los valores en una columna.
Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujarat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujarat', 'Jammu', 'Kolkata', 'Bihar']
})
count = df['A'].value_counts()
display(count)
count = df['B'].value_counts()
display(count)
Producción:
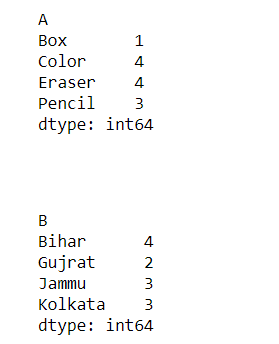
Ejemplo 2: Usando Pandas dataframe.size()
Devuelve un número total de elementos, se compara multiplicando filas y columnas devueltas por el método de forma.
Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujarat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujarat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).size()
display(freq)
freq = df.groupby(['B']).size()
display(freq)
Producción:
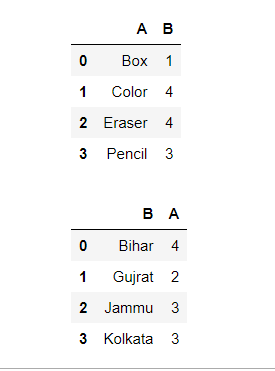
Ejemplo 3: Usando Pandas reset_index()
Es un método para restablecer el índice de un marco de datos. El método reset_index() establece una lista de números enteros que van desde 0 hasta la longitud de los datos como un índice.
Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujarat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujarat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A'])['B'].agg('count').reset_index()
display(freq)
freq = df.groupby(['B'])['A'].agg('count').reset_index()
display(freq)
Producción:
Ejemplo 4: Usando Pandas dataframe.count()
Se utiliza para contar el no. de observaciones no NA/nulas a lo largo del eje dado. También funciona con datos de tipo no flotante.
Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujarat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujarat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).count()
display(freq)
freq = df.groupby(['B']).count()
display(freq)
Producción:

Publicación traducida automáticamente
Artículo escrito por deepanshu_rustagi y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA