En este artículo, mostraremos cómo usar groupby en un marco de datos multiíndice en Pandas . En la ciencia de datos, cuando realizamos un análisis exploratorio de datos, a menudo usamos groupby para agrupar los datos de una columna en función de la otra columna. Entonces, podemos analizar cómo se agrupan los datos de una columna o según la otra columna. También existe una alternativa a groupby, también podemos usar una tabla dinámica .
Una operación groupby implica alguna combinación de dividir el objeto, aplicar una función y combinar los resultados. Esto se puede usar para agrupar grandes cantidades de datos y calcular operaciones en estos grupos. Cualquier operación groupby involucra una de las siguientes operaciones en el DataFrame original. Son los siguientes:
- Dividir el objeto.
- Combinando la salida.
- Aplicando una función.
Sintaxis:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True,
group_keys=True, squeeze=False, **kwargs)
Parámetros :
- por : mapeo, función, etiqueta o lista de tablas
- eje : {0 o ‘índice’, 1 o ‘columnas’}, predeterminado 0
- nivel: nombre del nivel
- ordenar : booleano, predeterminado Verdadero
Tipo de retorno : DataFrameGroupBy
Tenemos que pasar el nombre de los índices, en la lista al argumento de nivel en la función groupby. El índice de ‘región’ es el índice de nivel (0) y el índice de ‘estado’ es el índice de nivel (1) . En este artículo, vamos a utilizar este archivo CSV.
Veamos el archivo CSV
Python3
# importing pandas library
# as alias pd
import pandas as pd
# storing the data in the df dataframe
# using pandas 'read_csv()'.
df = pd.read_csv('homelessness.csv')
print(df.head())
Producción:
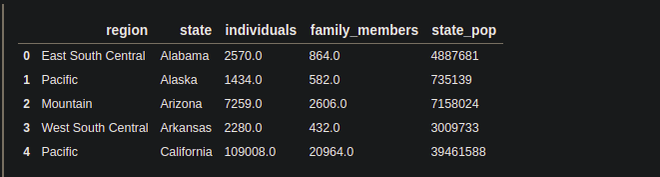
Columnas en el DataFrame: Podemos conocer las columnas del DataFrame usando el atributo de columnas de Pandas.
Python3
# using pandas columns attribute. col = df.columns print(col)
Salida :

Como no hay indexación en el DataFrame, podemos decir que este DataFrame no tiene índice. Primero, tenemos que hacer este DataFrame, Multi index DataFrame o Hierarchical index DataFrame .
Multi-indexación: el DataFrame que tiene más de un índice se llama Multi-index DataFrame . Para saber más sobre el DataFrame de múltiples índices, cómo hacer que el DataFrame sea de múltiples índices y cómo usar el DataFrame de múltiples índices para la exploración de datos, puede consultar este artículo.
Para hacer que el DataFrame sea multi-indexado, usaremos la función set_index() de Pandas . Vamos a hacer que las columnas ‘ región ‘ y ‘ estado ‘ del marco de datos sean el índice.
Ejemplo
Python3
# using the pandas set_index(). # passing the name of the columns in the list. df = df.set_index(['region' , 'state']) # sort the data using sort_index() df.sort_index() print(df.head())
Salida :
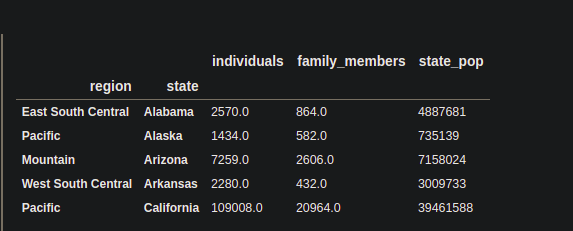
Ahora, el DataFrame es un DataFrame de múltiples índices que tiene las columnas ‘ región ‘ y ‘ estado ‘ como índice.
Uso de la operación Groupby en el marco de datos de múltiples índices :
Aquí representaremos los niveles con el índice de numeración a partir de 0.
Python3
# passing the level of indexes in # the list to the level argument. df.groupby(level=[0,1]).sum()
Producción:
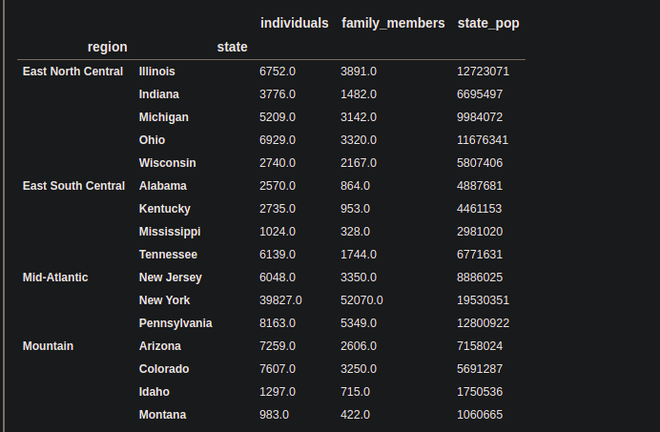
En lugar del número de nivel, también podemos pasar los nombres de las columnas.
Python3
# passing name of the index in # the level argument. y = df.groupby(level=['region'])['individuals'].mean() print(y)
Producción:
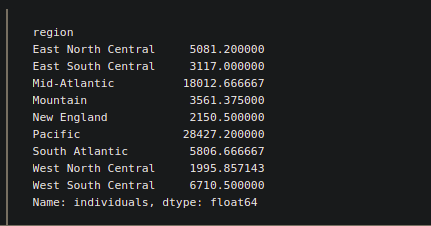
También podemos explorar más algunos métodos con groupby.
1. aplicar() en groupby:
Supongamos que queremos saber cuántos estados de cada región tienen más de 1000 ‘family_members’ . Para este tipo de enunciado del problema, podemos usar apply(). Dentro de apply() , tenemos que pasar el tipo de función, que está especialmente diseñada para una tarea en particular. Entonces, en este caso, vamos a usar la función lambda , que es una excelente manera de escribir funciones en una línea.
Ejemplo:
Python3
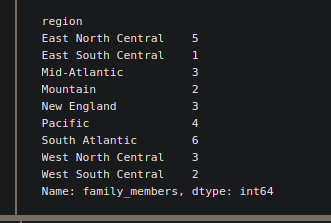
# import numpy library as alias np import numpy as np # applying .apply(), inside which passing # the lambda function. lambda function, # counting the no of states in each region # where are more than 1000 family_members. fam_1000 = df.groupby( level=["region"])["family_members"].apply(lambda x : np.sum(x>1000)) print(fam_1000)
Producción:
2. agg() en groupby :
La función agg() se puede usar para realizar alguna operación estadística como min(), max(), mean(), etc. Si queremos realizar más de una operación estadística a la vez, podemos pasarlas a la lista .
Python3
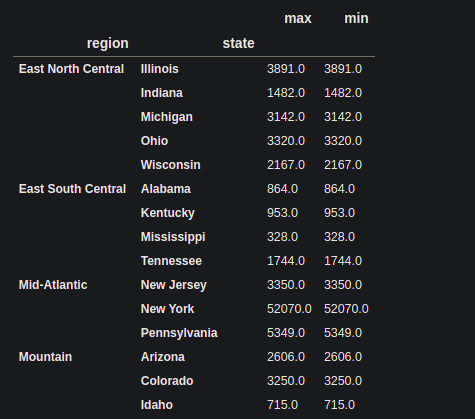
# performing max() and min() operation, # on the 'state_pop' column. df_agg = df.groupby( level=["region", "state"])["state_pop"].agg(["max", "min"]) print(df_agg)
Producción:
3. transform() en groupby:
El transform() se usa para transformar las columnas, bajo una condición dada. Dentro de la función de transformación, tenemos que pasar la función que se encargará de realizar una tarea especial. Vamos a utilizar la función lambda .
Ejemplo:
Python3
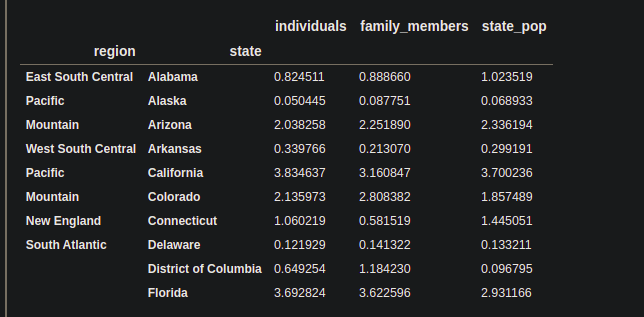
# defining the lambda function as 'score' score = (lambda x : (x / x.mean())) # applying transform() on all the # columns of DataFrame inside the # transform(), passing the score df_tra = df.groupby(level=["region"]).transform(score) print(df_tra.head(10))
Producción:
Nota: Existe una alternativa de operación groupby, Pivot_table , que también se usa para agrupar la primera columna en función de las columnas de los demás, pero una tabla dinámica puede ser más útil si queremos analizar grupos estadísticamente.
Publicación traducida automáticamente
Artículo escrito por pawanagrawalp847 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA