requisitos previos:
- Clasificación de imágenes
- Redes neuronales de convolución que incluyen agrupación básica , capas de convolución con normalización en redes neuronales y abandono .
- Aumento de datos .
- Redes Neuronales .
- Arreglos numpy .
En este artículo, vamos a discutir cómo clasificar imágenes usando TensorFlow. La clasificación de imágenes es un método para clasificar las imágenes en sus respectivas clases de categorías. El conjunto de datos CIFAR-10, como sugiere, tiene 10 categorías diferentes de imágenes. Hay un total de 60000 imágenes de 10 clases diferentes que nombran Avión , Automóvil , Pájaro , Gato , Ciervo , Perro , Rana , Caballo , Barco , Camión . Todas las imágenes son de tamaño 32×32. Hay en total 50000 imágenes de trenes y 10000 imágenes de prueba.
Para construir un clasificador de imágenes, usamos la API de keras de tensorflow para construir nuestro modelo. Para construir un modelo, se recomienda tener compatibilidad con GPU, o también puede usar las computadoras portátiles Google Colab.
Implementación paso a paso:
- El primer paso para escribir cualquier código es importar todas las bibliotecas y módulos necesarios. Esto incluye importar tensorflow y otros módulos como numpy. Si el módulo no está presente, puede descargarlo usando pip install tensorflow en el símbolo del sistema (para Windows) o si está usando un cuaderno jupyter, simplemente escriba !pip install tensorflow en la celda y ejecútelo para descargar el módulo . Otros módulos se pueden importar de manera similar.
Python3
import tensorflow as tf # Display the version print(tf.__version__) # other imports import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.layers import Input, Conv2D, Dense, Flatten, Dropout from tensorflow.keras.layers import GlobalMaxPooling2D, MaxPooling2D from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.models import Model
Producción:
2.4.1
La salida del código anterior debería mostrar la versión de tensorflow que está utilizando, por ejemplo, 2.4.1 o cualquier otra.
- Ahora tenemos el soporte de módulo requerido, así que carguemos nuestros datos. El conjunto de datos de CIFAR-10 está disponible en la API de keras de tensorflow , y podemos descargarlo en nuestra máquina local usando tensorflow.keras.datasets.cifar10 y luego distribuirlo para entrenar y probar el conjunto usando la función load_data() .
Python3
# Load in the data cifar10 = tf.keras.datasets.cifar10 # Distribute it to train and test set (x_train, y_train), (x_test, y_test) = cifar10.load_data() print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
Producción:
El resultado del código anterior mostrará la forma de las cuatro particiones y se verá así

Aquí podemos ver que tenemos 5000 imágenes de entrenamiento y 1000 imágenes de prueba como se especifica arriba y todas las imágenes tienen un tamaño de 32 por 32 y tienen 3 canales de color, es decir, las imágenes son imágenes en color. Así como también es visible que solo hay una única etiqueta asignada con cada imagen.
- Hasta ahora, tenemos nuestros datos con nosotros. Pero aún así, no podemos enviarlo directamente a nuestra red neuronal. Necesitamos procesar los datos para enviarlos a la red. Lo primero en el proceso es reducir los valores de píxel. Actualmente, todos los píxeles de la imagen están en un rango de 1 a 256, y necesitamos reducir esos valores a un valor que oscile entre 0 y 1. Esto permite que nuestro modelo rastree fácilmente las tendencias y el entrenamiento eficiente. Podemos hacer esto simplemente dividiendo todos los valores de píxeles por 255.0.
Otra cosa que queremos hacer es aplanar (en palabras simples, reorganizarlos en forma de fila) los valores de la etiqueta usando la función aplanar().
Python3
# Reduce pixel values x_train, x_test = x_train / 255.0, x_test / 255.0 # flatten the label values y_train, y_test = y_train.flatten(), y_test.flatten()
- Ahora es un buen momento para ver algunas imágenes de nuestro conjunto de datos. Podemos visualizarlo en forma de cuadrícula de subtrama. Dado que el tamaño de la imagen es de solo 32 × 32, no espere mucho de la imagen. Sería uno borroso. Podemos hacer la visualización usando la función subplot () de matplotlib y recorriendo las primeras 25 imágenes de nuestra parte del conjunto de datos de entrenamiento.
Python3
# visualize data by plotting images fig, ax = plt.subplots(5, 5) k = 0 for i in range(5): for j in range(5): ax[i][j].imshow(x_train[k], aspect='auto') k += 1 plt.show()
Producción:

Aunque las imágenes no son claras, hay suficientes píxeles para que podamos especificar qué objeto hay en esas imágenes.
- Después de completar todos los pasos, ahora es el momento de construir nuestro modelo. Vamos a utilizar una red neuronal de convolución o CNN para entrenar nuestro modelo. Incluye el uso de una capa de convolución en esto, que es la capa Conv2d, así como métodos de agrupación y normalización. Finalmente, lo pasaremos a una capa densa y la capa densa final, que es nuestra capa de salida. Estamos usando la función de activación ‘ relu ‘. La capa de salida utiliza una función «softmax».
Python3
# number of classes
K = len(set(y_train))
# calculate total number of classes
# for output layer
print("number of classes:", K)
# Build the model using the functional API
# input layer
i = Input(shape=x_train[0].shape)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(i)
x = BatchNormalization()(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2))(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2))(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
x = BatchNormalization()(x)
x = MaxPooling2D((2, 2))(x)
x = Flatten()(x)
x = Dropout(0.2)(x)
# Hidden layer
x = Dense(1024, activation='relu')(x)
x = Dropout(0.2)(x)
# last hidden layer i.e.. output layer
x = Dense(K, activation='softmax')(x)
model = Model(i, x)
# model description
model.summary()
Producción:
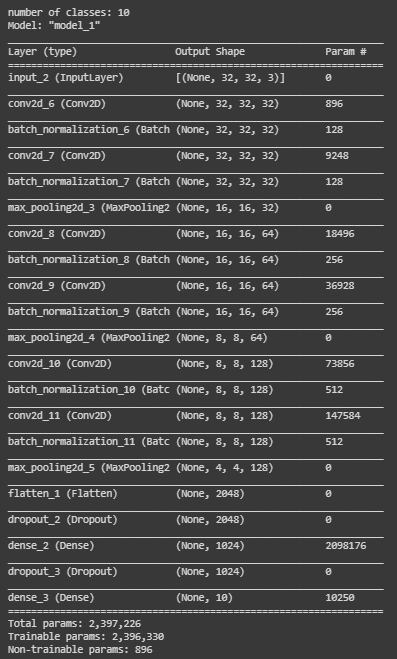
Nuestro modelo ya está listo, es hora de compilarlo. Estamos usando la función model.compile() para compilar nuestro modelo. Para los parámetros, estamos usando
- optimizador de adam
- sparse_categorical_crossentropy como función de pérdida
- métricas=[‘precisión’]
Python3
# Compile model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
- Ahora ajustemos nuestro modelo usando model.fit() pasándole todos nuestros datos. Vamos a entrenar nuestro modelo hasta 50 épocas, nos da un buen resultado, aunque puedes modificarlo si quieres.
Python3
# Fit r = model.fit( x_train, y_train, validation_data=(x_test, y_test), epochs=50)
Producción:
El modelo comenzará a entrenar y se verá así
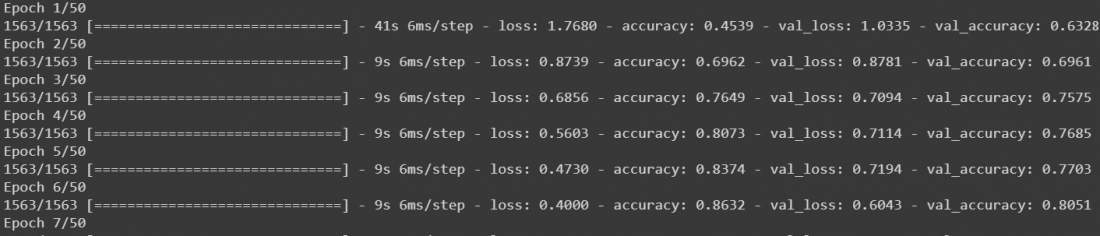
- Después de esto, nuestro modelo está entrenado. Aunque funcionará bien, para hacer que nuestro modelo sea mucho más preciso, podemos agregar aumento de datos en nuestros datos y luego entrenarlo nuevamente. Llamar de nuevo a model.fit() en datos aumentados continuará entrenando donde lo dejó. Vamos a colocar nuestros datos en un tamaño de lote de 32 y vamos a cambiar el rango de ancho y alto en 0,1 y voltear las imágenes horizontalmente. Luego llame a model.fit nuevamente por 50 épocas.
Python3
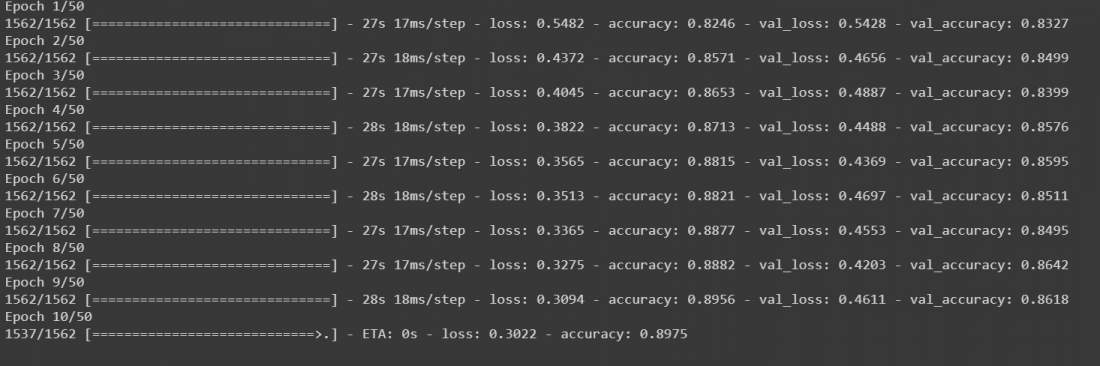
# Fit with data augmentation # Note: if you run this AFTER calling # the previous model.fit() # it will CONTINUE training where it left off batch_size = 32 data_generator = tf.keras.preprocessing.image.ImageDataGenerator( width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) train_generator = data_generator.flow(x_train, y_train, batch_size) steps_per_epoch = x_train.shape[0] // batch_size r = model.fit(train_generator, validation_data=(x_test, y_test), steps_per_epoch=steps_per_epoch, epochs=50)
Producción:
El modelo comenzará a entrenar durante 50 épocas. Aunque se ejecuta en la GPU, tardará al menos de 10 a 15 minutos.
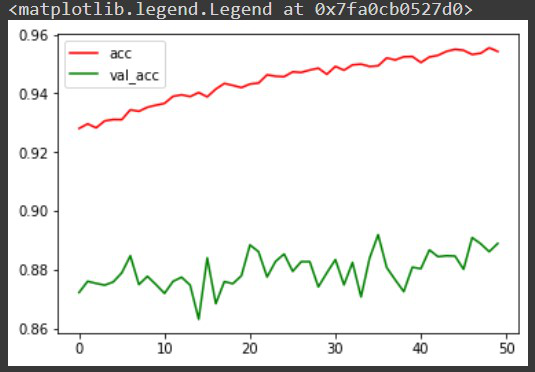
- Ahora que hemos entrenado nuestro modelo, antes de hacer predicciones a partir de él, visualicemos la precisión por iteración para un mejor análisis. Aunque existen otros métodos que incluyen array de confusión para un mejor análisis del modelo.
Python3
# Plot accuracy per iteration plt.plot(r.history['accuracy'], label='acc', color='red') plt.plot(r.history['val_accuracy'], label='val_acc', color='green') plt.legend()
Producción:
Hagamos una predicción sobre una imagen de nuestro modelo usando la función model.predict(). Antes de enviar la imagen a nuestro modelo, debemos reducir nuevamente los valores de píxel entre 0 y 1 y cambiar su forma a (1,32,32,3) ya que nuestro modelo espera que la entrada sea solo de esta forma. Para facilitar las cosas, tomemos una imagen del propio conjunto de datos. Ya está en formato de píxeles reducidos, pero tenemos que remodelarlo (1,32,32,3) usando la función remodelar(). Dado que estamos utilizando datos del conjunto de datos, podemos comparar el resultado previsto y el resultado original.
Python3
# label mapping
labels = '''airplane automobile bird cat deerdog frog horseship truck'''.split()
# select the image from our test dataset
image_number = 0
# display the image
plt.imshow(x_test[image_number])
# load the image in an array
n = np.array(x_test[image_number])
# reshape it
p = n.reshape(1, 32, 32, 3)
# pass in the network for prediction and
# save the predicted label
predicted_label = labels[model.predict(p).argmax()]
# load the original label
original_label = labels[y_test[image_number]]
# display the result
print("Original label is {} and predicted label is {}".format(
original_label, predicted_label))
Producción:

Ahora tenemos la salida, ya que la etiqueta original es cat y la etiqueta predicha también es cat.
Busquemos alguna etiqueta que haya sido mal clasificada por nuestro modelo, por ejemplo, para la imagen número 5722 recibimos algo como esto:
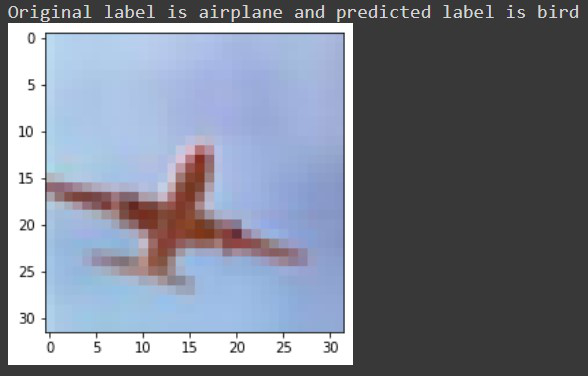
Finalmente, guardemos nuestro modelo usando la función model.save() como un archivo h5. Si está utilizando la colaboración de Google, puede descargar su modelo desde la sección de archivos.
Python3
# save the model
model.save('geeksforgeeks.h5')
Por lo tanto, de esta manera, se pueden clasificar imágenes utilizando Tensorflow.
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA