El reconocimiento de voz es una característica importante en varias aplicaciones utilizadas, como la domótica, la inteligencia artificial, etc. Este artículo tiene como objetivo proporcionar una introducción sobre cómo utilizar la biblioteca SpeechRecognition de Python. Esto es útil ya que puede usarse en microcontroladores como Raspberri Pis con la ayuda de un micrófono externo.
Instalaciones requeridas
Se debe instalar lo siguiente:
- Módulo de reconocimiento de voz de Python:
sudo pip install SpeechRecognition
- PyAudio: use el siguiente comando para usuarios de Linux
sudo apt-get install python-pyaudio python3-pyaudio
Si las versiones en los repositorios son demasiado antiguas, instale pyaudio usando el siguiente comando
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev && sudo pip install pyaudio
Use pip3 en lugar de pip para python3.
Los usuarios de Windows pueden instalar pyaudio ejecutando el siguiente comando en una terminalpip install pyaudio
Entrada de voz usando un micrófono y traducción de voz a texto
- Configurar Micrófono (Para micrófonos externos): Es recomendable especificar el micrófono durante el programa para evitar fallas.
Escriba lsusb en la terminal. Aparecerá una lista de dispositivos conectados. El nombre del micrófono se vería asíUSB Device 0x46d:0x825: Audio (hw:1, 0)
Tome nota de esto, ya que se utilizará en el programa.
- Establecer tamaño de fragmento: esto básicamente implicó especificar cuántos bytes de datos queremos leer a la vez. Por lo general, este valor se especifica en potencias de 2, como 1024 o 2048
- Establecer frecuencia de muestreo: la frecuencia de muestreo define con qué frecuencia se registran los valores para su procesamiento
- Establezca la ID del dispositivo en el micrófono seleccionado : en este paso, especificamos la ID del dispositivo del micrófono que deseamos usar para evitar ambigüedades en caso de que haya varios micrófonos. Esto también ayuda a la depuración, en el sentido de que, mientras ejecutamos el programa, sabremos si se está reconociendo el micrófono especificado. Durante el programa, especificamos un parámetro device_id. El programa dirá que no se pudo encontrar device_id si no se reconoce el micrófono.
- Permitir ajuste por ruido ambiental: dado que el ruido ambiental varía, debemos permitir que el programa ajuste el umbral de energía de grabación por un segundo o más para que se ajuste de acuerdo con el nivel de ruido externo.
- Traducción de voz a texto: Esto se hace con la ayuda de Google Speech Recognition. Esto requiere una conexión a Internet activa para funcionar. Sin embargo, hay ciertos sistemas de Reconocimiento fuera de línea como PocketSphinx, pero tienen un proceso de instalación muy riguroso que requiere varias dependencias. El reconocimiento de voz de Google es uno de los más fáciles de usar.
Los pasos anteriores se han implementado a continuación:
#Python 2.x program for Speech Recognition import speech_recognition as sr #enter the name of usb microphone that you found#using lsusb#the following name is only used as an examplemic_name = "USB Device 0x46d:0x825: Audio (hw:1, 0)"#Sample rate is how often values are recordedsample_rate = 48000#Chunk is like a buffer. It stores 2048 samples (bytes of data)#here. #it is advisable to use powers of 2 such as 1024 or 2048chunk_size = 2048#Initialize the recognizerr = sr.Recognizer() #generate a list of all audio cards/microphonesmic_list = sr.Microphone.list_microphone_names() #the following loop aims to set the device ID of the mic that#we specifically want to use to avoid ambiguity.for i, microphone_name in enumerate(mic_list): if microphone_name == mic_name: device_id = i #use the microphone as source for input. Here, we also specify #which device ID to specifically look for incase the microphone #is not working, an error will pop up saying "device_id undefined"with sr.Microphone(device_index = device_id, sample_rate = sample_rate, chunk_size = chunk_size) as source: #wait for a second to let the recognizer adjust the #energy threshold based on the surrounding noise level r.adjust_for_ambient_noise(source) print "Say Something" #listens for the user's input audio = r.listen(source) try: text = r.recognize_google(audio) print "you said: " + text #error occurs when google could not understand what was said except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Transcribir un archivo de audio a texto
Si tenemos un archivo de audio que queremos traducir a texto, simplemente debemos reemplazar la fuente con el archivo de audio en lugar de un micrófono.
Coloque el archivo de audio y el programa en la misma carpeta para mayor comodidad. Esto funciona para archivos WAV, AIFF o FLAC.
A continuación se muestra una implementación.
#Python 2.x program to transcribe an Audio fileimport speech_recognition as sr AUDIO_FILE = ("example.wav") # use the audio file as the audio source r = sr.Recognizer() with sr.AudioFile(AUDIO_FILE) as source: #reads the audio file. Here we use record instead of #listen audio = r.record(source) try: print("The audio file contains: " + r.recognize_google(audio)) except sr.UnknownValueError: print("Google Speech Recognition could not understand audio") except sr.RequestError as e: print("Could not request results from Google Speech Recognition service; {0}".format(e)) |
Solución de problemas
Los siguientes problemas se encuentran comúnmente
- Micrófono silenciado: esto hace que no se reciba la entrada. Para verificar esto, puede usar alsamixer.
Se puede instalar usandosudo apt-get install libasound2 alsa-utils alsa-oss
Escriba un mezclador . La salida se verá algo así
Simple mixer control 'Master', 0 Capabilities: pvolume pswitch pswitch-joined Playback channels: Front Left - Front Right Limits: Playback 0 - 65536 Mono: Front Left: Playback 41855 [64%] [on] Front Right: Playback 65536 [100%] [on] Simple mixer control 'Capture', 0 Capabilities: cvolume cswitch cswitch-joined Capture channels: Front Left - Front Right Limits: Capture 0 - 65536 Front Left: Capture 0 [0%] [off] #switched off Front Right: Capture 0 [0%] [off]
Como puede ver, el dispositivo de captura está actualmente apagado. Para encenderlo, escriba alsamixer
Como puede ver en la primera imagen, está mostrando nuestros dispositivos de reproducción. Presione F4 para cambiar a Capturar dispositivos.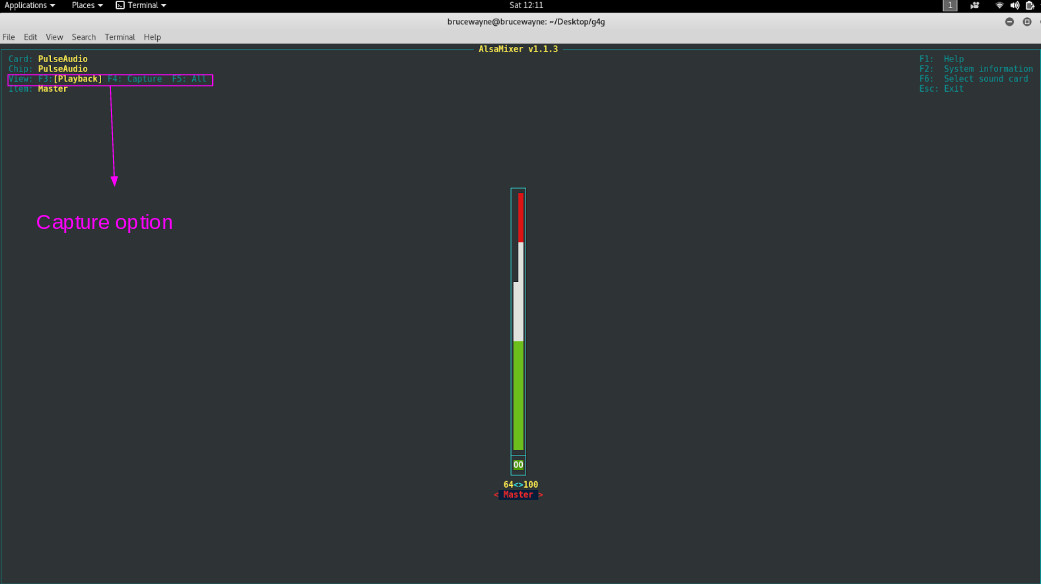
En la segunda imagen, la parte resaltada muestra que el dispositivo de captura está silenciado. Para activarlo, presione la barra espaciadora

Como puede ver en la última imagen, la parte resaltada confirma que el dispositivo de captura no está silenciado.

- Micrófono actual no seleccionado como dispositivo de captura:
En este caso, el micrófono se puede configurar escribiendo alsamixer y seleccionando tarjetas de sonido. Aquí puede seleccionar el dispositivo de micrófono predeterminado.
Como se muestra en la imagen, la parte resaltada es donde debe seleccionar la tarjeta de sonido.
La segunda imagen muestra la selección de pantalla para la tarjeta de sonido.

- Sin conexión a Internet: la conversión de voz a texto requiere una conexión a Internet activa.
Este artículo es una contribución de Deepak Srivatsav . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA