Es posible que sea necesario estandarizar un conjunto de datos grande que tenía varias columnas con diferentes rangos y unidades antes de continuar con el procesamiento. En este artículo, discutiremos cómo estandarizar una columna de marco de datos en el lenguaje de programación R.
Primero analicemos la estandarización. La estandarización es una técnica de escalado de características . Es el proceso de cambiar la escala de los datos para que los datos tengan una media de ‘0’ y una desviación estándar de ‘1’.
Fórmula:

Aquí,  es la media y
es la media y  es la desviación estándar. Estamos restando la media de cada valor en la observación y luego dividiendo por la desviación estándar. Esto también se llama fórmula de puntuación Z.
es la desviación estándar. Estamos restando la media de cada valor en la observación y luego dividiendo por la desviación estándar. Esto también se llama fórmula de puntuación Z.
Ejemplo :
|
|
Nombre |
Años |
CGPA |
|---|---|---|---|
|
1. |
A |
15 |
5.0 |
|
2. |
B |
dieciséis |
4.0 |
|
3. |
C |
20 |
5.0 |
|
4. |
D |
19 |
2.0 |
|
5. |
mi |
19 |
1.0 |
|
6. |
F |
17 |
3.0 |
En este conjunto de datos, tenemos los nombres de los estudiantes, su edad y CGPA como nombres de columna. Como la edad está en el rango de 15 a 20 y el CGPA está en el rango de 1.0 a 5.0. Nos gustaría estandarizar el CGPA y la columna de edad. Entonces, nuestro conjunto de datos debería verse así:
|
|
Nombre |
Años |
CGPA |
|---|---|---|---|
|
1. |
A |
-1.3561270 |
1.0206207 |
|
2. |
B |
-0.8475794 |
0.4082483 |
|
3. |
C |
1.1866111 |
1.0206207 |
|
4. |
D |
0.6780635 |
-0.8164966 |
|
5. |
mi |
0.6780635 |
-1.4288690 |
|
6. |
F |
-0.3390318 |
-0.2041241 |
Método 1: Uso de la función Escala.
R tiene una función integrada llamada scale() con fines de estandarización.
Sintaxis: escala(x,centro=Verdadero,escala=Verdadero)
Aquí, «x» representa la columna de datos/conjunto de datos en el que desea aplicar la estandarización. El parámetro «center» toma valores booleanos, restará la media del valor de observación cuando se establece en True. El parámetro «escala» toma valores booleanos, dividirá la diferencia resultante por la desviación estándar cuando se establezca en Verdadero.
Acercarse:
- Crear conjunto de datos
- Aplicar la función de escala en la columna de datos
- Convierta el resultado del vector en el marco de datos
- Mostrar resultado
Programa:
R
# Creating Dataset
X <- c('A','B','C','D','E','F')
Y <- c(15,16,20,19,19,17)
Z <- c(5.0,4.0,5.0,2.0,1.0,3.0)
dataframe <- data.frame(Name = X, Age = Y, CGPA = Z )
# applying scale function
dataframe[2 : 3] <- as.data.frame(scale(dataframe[2 : 3]))
# displaying result
dataframe
Producción:
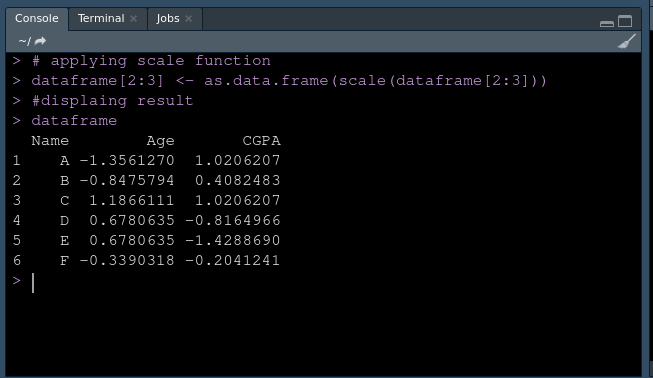
Usando escala
Método 2: Usando la base R
Acercarse:
- Crear conjunto de datos.
- Cree una función para la estandarización.
Sintaxis: estandarizar = function(x){ z <- (x – mean(x)) / sd(x) return( z)}
- Aplique esta función a las columnas de datos.
- Convierta el resultado del vector en el marco de datos
- Mostrar resultado
Programa:
R
# Creating Dataset
X <- c('A', 'B', 'C', 'D', 'E', 'F')
Y <- c(15, 16, 20, 19, 19, 17)
Z <- c(5.0, 4.0, 5.0, 2.0, 1.0, 3.0)
dataframe <- data.frame(Name = X, Age = Y, CGPA = Z )
# creating Standardization function
standardize = function(x){
z <- (x - mean(x)) / sd(x)
return( z)
}
# apply your function to the dataset
dataframe[2:3] <-
apply(dataframe[2:3], 2, standardize)
#displaying result
dataframe
Producción:
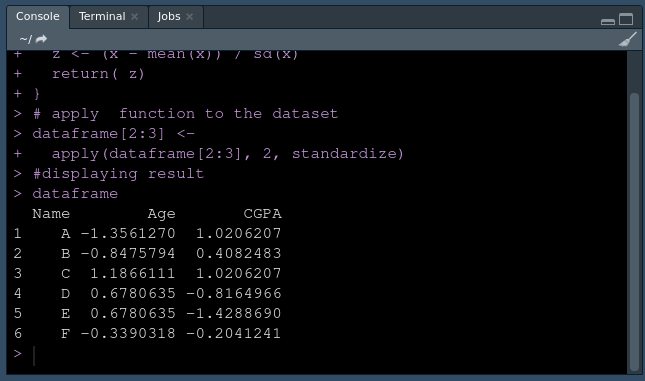
Uso de la función de estandarización personalizada
Publicación traducida automáticamente
Artículo escrito por amnindersingh1414 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA