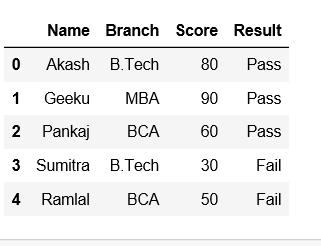
Los pandas brindan una manera conveniente de manejar los datos y su transformación. Veamos cómo podemos convertir una columna de marco de datos en un nombre de fila o índice en Pandas.
Cree un marco de datos primero con dictado de listas.
Python3
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'Name':["Akash", "Geeku", "Pankaj", "Sumitra", "Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80", "90", "60", "30", "50"],
'Result': ["Pass", "Pass", "Pass", "Fail", "Fail"]}
# creating a dataframe
df = pd.DataFrame(data)
df
Producción:
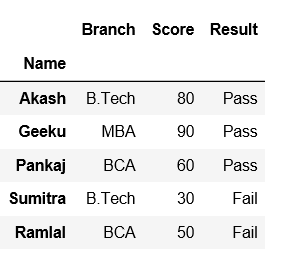
Método #1: Usando el método set_index() .
Python3
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'Name':["Akash", "Geeku", "Pankaj", "Sumitra", "Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80", "90", "60", "30", "50"],
'Result': ["Pass", "Pass", "Pass", "Fail", "Fail"]}
# Creating a dataframe
df = pd.DataFrame(data)
# Using set_index() method on 'Name' column
df = df.set_index('Name')
df
Producción:
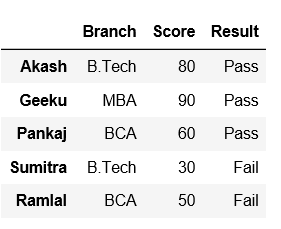
Ahora, establezca el nombre del índice como Ninguno.
Python3
# set the index to 'None' via its name property df.index.names = [None] df
Producción:
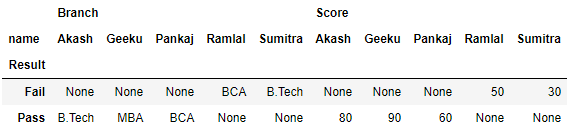
Método #2: Usar el método pivot() .
Para convertir una columna en un nombre de fila o índice en un marco de datos, Pandas tiene una función Pivot incorporada. Ahora, digamos que queremos que Result sean las filas/índice, y las columnas sean el nombre en nuestro marco de datos, para lograr esto, pandas ha proporcionado un método llamado Pivot. Veamos cómo funciona,
Python3
# importing pandas as pd
import pandas as pd
# Creating a dict of lists
data = {'name':["Akash", "Geeku", "Pankaj", "Sumitra", "Ramlal"],
'Branch':["B.Tech", "MBA", "BCA", "B.Tech", "BCA"],
'Score':["80", "90", "60", "30", "50"],
'Result': ["Pass", "Pass", "Pass", "Fail", "Fail"]}
df = pd.DataFrame(data)
# pivoting the dataframe
df.pivot(index ='Result', columns ='name')
df
Producción: