Mientras se trabaja con un marco de datos grande, el marco de datos consta de cualquier cantidad de columnas que tienen diferentes tipos de datos. Para preprocesar los datos para aplicar operaciones en ellos, debemos conocer las dimensiones del marco de datos y los tipos de datos de las columnas que están presentes en el marco de datos.
En este artículo vamos a saber cómo verificar el tipo de columna del Dataframe. Para verificar el tipo de columna estamos usando la función dtypes. La función dtypes se utiliza para devolver la lista de tuplas que contienen el Nombre de la columna y el tipo de columna.
Sintaxis: df.dtypes()
donde, df es el marco de datos
Al principio, crearemos un marco de datos y luego veremos algunos ejemplos e implementación.
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Product_details.com") \
.getOrCreate()
return spk
def create_df(spark,data,schema):
df1 = spark.createDataFrame(data,schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
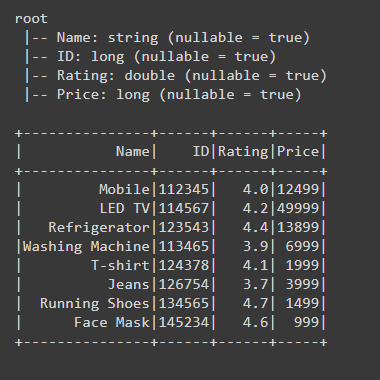
input_data = [("Mobile",112345,4.0,12499),
("LED TV",114567,4.2,49999),
("Refrigerator",123543,4.4,13899),
("Washing Machine",113465,3.9,6999),
("T-shirt",124378,4.1,1999),
("Jeans",126754,3.7,3999),
("Running Shoes",134565,4.7,1499),
("Face Mask",145234,4.6,999)]
schema = ["Name","ID","Rating","Price"]
# calling function to create dataframe
df = create_df(spark,input_data,schema)
# visualizing the dataframe
df.show()
Producción:
Ejemplo 1: verificar el tipo de columna del marco de datos usando la función dtypes()
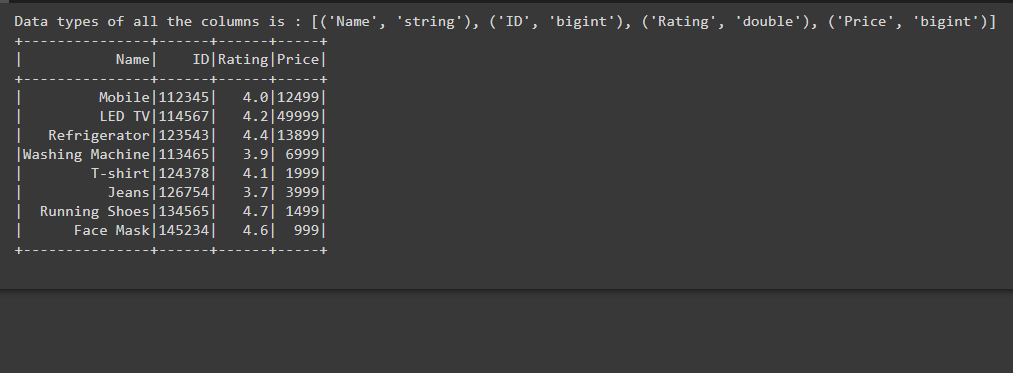
En el siguiente código de ejemplo, hemos creado el marco de datos y luego, para obtener los tipos de columna de todas las columnas presentes en el marco de datos, hemos usado la función dtypes al escribir df.dtypes usando una string f mientras buscamos los tipos de datos de todas las columnas que hemos impreso. además. Esto da una lista de tuplas que contiene el nombre y el tipo de datos de las columnas.
Python
# finding data type of the all the
# column using dtype function and
# printing
print(f'Data types of all the columns is : {df.dtypes}')
# visualizing the dataframe
df.show()
Producción:
Ejemplo 2: verificar el tipo de datos de columna específico del marco de datos
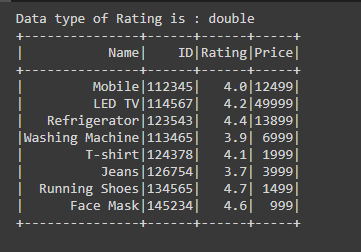
En el siguiente código, después de crear el marco de datos, estamos encontrando el tipo de datos de la columna en particular usando la función dtypes() escribiendo dict(df.dtypes)[‘Rating’] , aquí estamos usando dict porque, como vemos en el ejemplo anterior, df .dtypes devuelve la lista de tuplas que contiene el nombre y el tipo de datos de la columna. Entonces, usando dict estamos encasillando tupla en el diccionario.
Como sabemos en el diccionario, los datos se almacenan en un par de clave y valor, mientras escribimos dict(df.dtypes)[‘Rating’] estamos dando la clave, es decir, ‘Rating’ y extrayendo su valor que es double , que es el tipo de datos de la columna. Entonces, de esta manera, podemos averiguar el tipo de datos del tipo de columna al pasar el nombre específico de la columna.
Python
# finding data type of the Rating
# column using dtype function
data_type = dict(df.dtypes)['Rating']
# printing
print(f'Data type of Rating is : {data_type}')
# visualizing the dataframe
df.show()
Producción:
Ejemplo 3: verificar el tipo de columna del marco de datos usando for loop
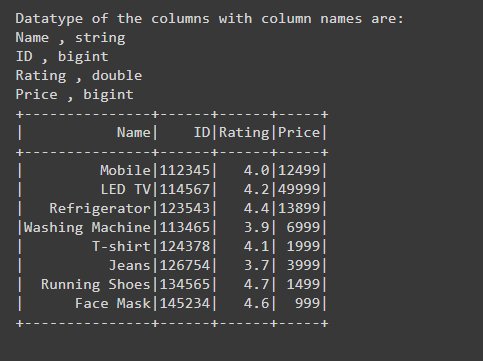
Después de crear el Dataframe, para encontrar los tipos de datos de la columna con el nombre de la columna, estamos usando df.dtypes que nos da la lista de tuplas.
Mientras iteramos, obtenemos el nombre de la columna y el tipo de columna como una tupla y luego imprimimos el nombre de la columna y el tipo de columna usando print(col[0],”,”,col[1]). De esta manera, estamos obteniendo cada nombre de columna y tipo de columna utilizando iterando.
Python
print("Datatype of the columns with column names are:")
# finding datatype of all column with
# column name using for loop
for col in df.dtypes:
# printing the column and datatype
# of that column
print(col[0],",",col[1])
# visualizing the dataframe
df.show()
Producción:
Ejemplo 4: verificar el tipo de columna del marco de datos usando el esquema
Después de crear el marco de datos para verificar el tipo de columna, estamos usando la función printSchema() escribiendo df.printSchema() a través de esta función, se imprime el esquema del marco de datos que contiene el tipo de datos de todas y cada una de las columnas presentes en el marco de datos. Entonces, usando la función printSchema() también podemos verificar fácilmente el tipo de columna del PySpark Dataframe.
Python
# printing the schema of the Dataframe # using printscheam function df.printSchema() # visualizing the dataframe df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA