Muchas veces, mientras trabajamos con la automatización web, necesitamos convertir el código HTML en texto. Esto se puede hacer usando BeautifulSoup. Este módulo proporciona la función get_text() que toma HTML como entrada y devuelve texto como salida.
Ejemplo 1:
Python3
# importing the library
from bs4 import BeautifulSoup
# Initializing variable
gfg = BeautifulSoup("<b>Section </b><br/>BeautifulSoup<ul>\
<li>Example <b>1</b></li>")
# Calculating result
res = gfg.get_text()
# Printing the result
print(res)
Producción:
Section BeautifulSoupExample 1
Ejemplo 2: este ejemplo extrae datos del sitio web en vivo y luego los convierte en texto. En este ejemplo, usamos el módulo de solicitud de la biblioteca urllib para leer datos HTML de la URL.
Python3
# importing the library
from bs4 import BeautifulSoup
from urllib import request
# Initializing variable
url = "https://www.geeksforgeeks.org/matrix-introduction/"
gfg = BeautifulSoup(request.urlopen(url).read())
# Extracting data for article section
bodyHtml = gfg.find('article', {'class' : 'content'})
# Calculating result
res = bodyHtml.get_text()
# Printing the result
print(res)
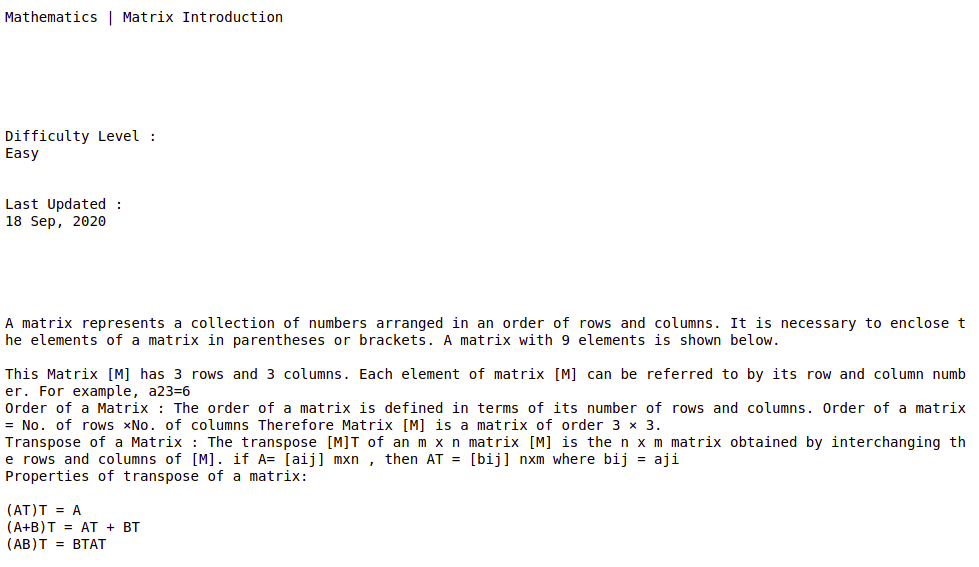
Producción:
Publicación traducida automáticamente
Artículo escrito por aman neekhara y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA