Mientras trabajamos con archivos CSV durante el análisis de datos, a menudo tenemos que lidiar con grandes conjuntos de datos. A veces, es posible que un solo archivo CSV no contenga todos los datos que necesita. En tales casos, es necesario fusionar estos archivos en un solo marco de datos. Afortunadamente, la biblioteca de Pandas nos brinda varios métodos, como fusionar, concatenar y unir para que esto sea posible. A través de los ejemplos que se dan a continuación, aprenderemos cómo combinar archivos CSV usando Pandas.
Archivo utilizado:
Primer CSV –

Segundo CSV –

Tercer CSV –

Método 1: fusión por nombres
Primero entendamos cada método usado en el programa dado arriba:
- pd.concat(): este método une los conjuntos de datos proporcionados a lo largo del eje de la fila o de la columna. Toma los objetos del marco de datos como parámetros. Junto con eso, también puede tomar otros parámetros como eje, ignore_index, etc.
- map (función, iterable): ejecuta una función específica para cada elemento en iterables. En el ejemplo anterior, la función pd.read_csv() se aplica a todos los archivos CSV de la lista proporcionada.
Acercarse:
- Al principio, importamos Pandas.
- Usando pd.read_csv() (la función), la función map lee todos los archivos CSV (los iterables) que hemos pasado. Ahora, pd.concat() toma estos archivos CSV asignados como argumento y los une a lo largo del eje de la fila (predeterminado). Podemos pasar axis=1 si deseamos fusionarlos horizontalmente a lo largo de la columna. Además, ignore_index = True establece valores de índice continuos para el marco de datos fusionado.
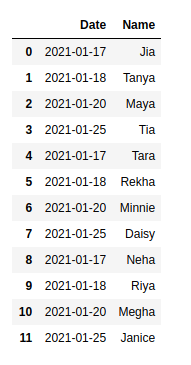
- Las imágenes que se muestran a continuación muestran mydata.csv, mydata1.csv y el marco de datos fusionado.
Ejemplo:
Python3
# importing pandas import pandas as pd # merging two csv files df = pd.concat( map(pd.read_csv, ['mydata.csv', 'mydata1.csv']), ignore_index=True) print(df)
Producción:
Método 2: fusionar todo
Acercarse:
- os.path.join() toma la ruta del archivo como el primer parámetro y los componentes de la ruta que se unirán como el segundo parámetro. “ mydata*.csv ayuda a devolver cada archivo en el directorio de inicio que comienza con “mydata” y termina con .CSV (Uso de comodín *).
- glob.glob() toma estos nombres de archivos unidos y devuelve una lista de todos estos archivos. En este ejemplo, se devuelven mydata.csv , mydata1.csv y mydata2.csv .
- Ahora, al igual que en el ejemplo anterior, esta lista de archivos se mapea y luego se concatena.
Simplemente podemos escribir estas tres líneas de código como:
df = pd.concat(mapa(pd.read_csv, glob.glob(os.path.join(“/home”, “mydata*.csv”))), ignore_index= True)
Ejemplo:
Python3
# importing libraries
import pandas as pd
import glob
import os
# merging the files
joined_files = os.path.join("/home", "mydata*.csv")
# A list of all joined files is returned
joined_list = glob.glob(joined_files)
# Finally, the files are joined
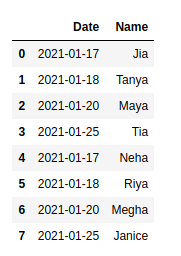
df = pd.concat(map(pd.read_csv, joined_list), ignore_index=True)
print(df)
Producción: