Requisito previo: agrupamiento de K-Means
La agrupación en clústeres de K-Means es uno de los enfoques de partición y cada clúster se representará con un centroide calculado. Todos los puntos de datos en el grupo tendrán una distancia mínima desde el centroide calculado.
Scipy es una biblioteca de código abierto que se puede utilizar para cálculos complejos. Se usa principalmente con arrays NumPy. Se puede instalar ejecutando el comando que se indica a continuación.
pip instalar scipy
Tiene paquetes dedicados para el proceso de agrupamiento. Hay dos módulos que pueden ofrecer métodos de agrupación.
- clúster.vq
- clúster.jerarquía
clúster.vq
Este módulo brinda la función de cuantificación vectorial para usar con el método de agrupación en clústeres K-Means. La cuantificación de vectores juega un papel importante en la reducción de la distorsión y la mejora de la precisión. En su mayoría, la distorsión aquí se calcula utilizando la distancia euclidiana entre el centroide y cada vector. En base a esto, los puntos de datos del vector od se asignan a un grupo.
clúster.jerarquía
Este módulo proporciona métodos para el agrupamiento jerárquico general y sus tipos, como el agrupamiento aglomerativo. Tiene varias rutinas que se pueden usar para aplicar métodos estadísticos en las jerarquías, visualizar los grupos, graficar los grupos, verificar vínculos en los grupos y también verificar si dos jerarquías diferentes son equivalentes.
En este artículo, se utilizará el módulo cluster.vq para realizar el agrupamiento de K-Means.
Agrupación de K-Means con la biblioteca Scipy
El agrupamiento de K-medias se puede realizar en datos dados ejecutando los siguientes pasos.
- Normalice los puntos de datos.
- Calcule los centroides (denominados código y la array 2D de centroides se denomina libro de códigos).
- Forme grupos y asigne los puntos de datos (lo que se conoce como mapeo del libro de códigos).
clúster.vq.whiten()
Este método se utiliza para normalizar los puntos de datos. La normalización es muy importante cuando los atributos considerados son de unidades diferentes. Por ejemplo, si la longitud se da en metros y la anchura en pulgadas, puede producir una varianza desigual para los vectores. Siempre se prefiere tener una varianza de unidades mientras se realiza el agrupamiento de K-Means para obtener agrupaciones precisas. Por lo tanto, la array de datos debe pasar al método whiten() antes de cualquier otro paso.
cluster.vq.whiten(array_entrada, verificación_finita)
Parámetros:
- input_array : la array de puntos de datos que se normalizarán.
- check_finite: si se establece en verdadero, verifica si la array de entrada contiene solo números finitos. Si se establece en falso, ignora la verificación.
clúster.vq.kmeans()
Este módulo vq tiene dos métodos, a saber, kmeans() y kmeans2().
El método kmeans() utiliza un valor umbral que al ser menor o igual al cambio de distorsión en la última iteración, el algoritmo termina. Este método devuelve los centroides calculados y el valor medio de las distancias euclidianas entre las observaciones y los centroides.
cluster.vq.kmeans(input_array, k, iteraciones, umbral, check_finite)
Parámetros:
- input_array : la array de puntos de datos que se normalizarán.
- k : No.de.clusters (centroides)
- iteraciones : N.º de iteraciones para realizar kmsignifica que la distorsión se minimice. Si se especifica k, se ignora.
- umbral: un valor entero que, si se vuelve menor o igual al cambio en la distorsión en la última iteración, el algoritmo termina.
- check_finite: si se establece en verdadero, verifica si la array de entrada contiene solo números finitos. Si se establece en falso, ignora la verificación.
El método kmeans2() no utiliza el valor de umbral para verificar la convergencia. Tiene más parámetros que deciden el método de inicialización de centroides, un método para manejar grupos vacíos y validar si las arrays de entrada contienen solo números finitos. Este método devuelve los centroides y los grupos a los que pertenece el vector.
cluster.vq.kmeans2(input_array, k, iteraciones, umbral, minit, faltante, check_finite)
Parámetros:
- input_array : la array de puntos de datos que se normalizarán.
- k : No.de.clusters (centroides)
- iteraciones : N.º de iteraciones para realizar kmsignifica que la distorsión se minimice. Si se especifica k, se ignora.
- umbral: un valor entero que, si se vuelve menor o igual al cambio en la distorsión en la última iteración, el algoritmo termina.
- minit : Una string que denota el método de inicialización de los centroides. Los valores posibles son ‘random’, ‘points’, ‘++’, ‘matrix’ .
- faltante: una string que denota acción sobre clústeres vacíos. Los valores posibles son ‘warn’, ‘raise’ .
- check_finite: si se establece en verdadero, verifica si la array de entrada contiene solo números finitos. Si se establece en falso, ignora la verificación.
clúster.vq.vq()
Este método asigna las observaciones a los centroides apropiados que se calculan mediante el método kmeans(). Requiere que las arrays de entrada estén normalizadas. Toma las entradas normalizadas y el libro de códigos generado como entrada. Devuelve el índice del libro de códigos al que corresponde la observación y la distancia entre la observación y su código (centroide).
Agrupación de K-Means con una array de datos 2D
Paso 1: Importe los módulos requeridos.
Python3
# import modules import numpy as np from scipy.cluster.vq import whiten, kmeans, vq, kmeans2
Paso 2 : Importar/generar datos. Normalizar los datos.
Python3
# observations data = np.array([[1, 3, 4, 5, 2], [2, 3, 1, 6, 3], [1, 5, 2, 3, 1], [3, 4, 9, 2, 1]]) # normalize data = whiten(data) print(data)
Producción

Paso 3: Calcule los centroides y genere el libro de códigos para el mapeo usando el método kmeans()
Python3
# code book generation
centroids, mean_value = kmeans(data, 3)
print("Code book :\n", centroids, "\n")
print("Mean of Euclidean distances :",
mean_value.round(4))
Producción

Paso 4: Asigne los centroides calculados en el paso anterior a los conglomerados.
Python3
# mapping the centroids
clusters, distances = vq(data, centroids)
print("Cluster index :", clusters, "\n")
print("Distance from the centroids :", distances)
Producción

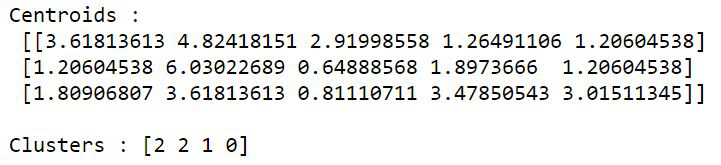
Considere el mismo ejemplo con kmeans2() . Esto no requiere el paso adicional de llamar al método vq(). Repita los pasos 1 y 2, luego use el siguiente fragmento.
Python3
# assign centroids and clusters
centroids, clusters = kmeans2(data, 3,
minit='random')
print("Centroids :\n", centroids, "\n")
print("Clusters :", clusters)
Producción
Ejemplo 2: agrupación de K-Means del conjunto de datos de Diabetes
El conjunto de datos contiene los siguientes atributos en función de los cuales un paciente se coloca en un grupo de diabéticos o en un grupo de no diabéticos .
- Embarazos
- Glucosa
- Presión arterial
- Grosor de la piel
- Insulina
- IMC
- Función de pedigrí de diabetes
- Años
Python3
# import modules
import matplotlib.pyplot as plt
import numpy as np
from scipy.cluster.vq import whiten, kmeans, vq
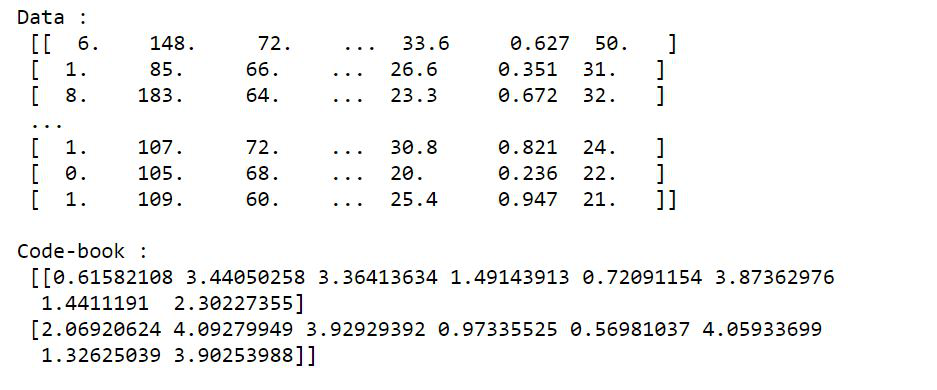
# load the dataset
dataset = np.loadtxt(r"{your-path}\diabetes-train.csv",
delimiter=",")
# excluding the outcome column
dataset = dataset[:, 0:8]
print("Data :\n", dataset, "\n")
# normalize
dataset = whiten(dataset)
# generate code book
centroids, mean_dist = kmeans(dataset, 2)
print("Code-book :\n", centroids, "\n")
clusters, dist = vq(dataset, centroids)
print("Clusters :\n", clusters, "\n")
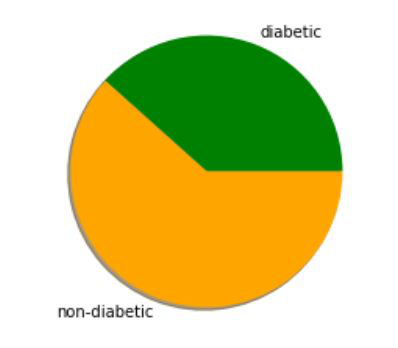
# count non-diabetic patients
non_diab = list(clusters).count(0)
# count diabetic patients
diab = list(clusters).count(1)
# depict illustration
x_axis = []
x_axis.append(diab)
x_axis.append(non_diab)
colors = ['green', 'orange']
print("No.of.diabetic patients : " + str(x_axis[0]) +
"\nNo.of.non-diabetic patients : " + str(x_axis[1]))
y = ['diabetic', 'non-diabetic']
plt.pie(x_axis, labels=y, colors=colors, shadow='true')
plt.show()
Producción

Publicación traducida automáticamente
Artículo escrito por erakshaya485 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA