En este artículo, discutiremos cómo agrupar PySpark DataFrame y luego ordenarlo en orden descendente.
Métodos utilizados
- groupBy(): la función groupBy() en pyspark se usa para agrupar datos idénticos en DataFrame mientras realiza una función agregada en los datos agrupados.
Sintaxis: DataFrame.groupBy(*columnas)
Parámetros:
- cols→ Cns por el cual necesitamos agrupar datos
- sort(): La función sort() se usa para ordenar una o más columnas. Por defecto, ordena en orden ascendente.
Sintaxis: sort(*columnas, ascendente=Verdadero)
Parámetros:
- cols→ Columnas por las que se necesita realizar la clasificación.
- PySpark DataFrame también proporciona la función orderBy() que ordena una o más columnas. Por defecto ordena de forma ascendente.
Sintaxis: orderBy(*columnas, ascendente=Verdadero)
Parámetros:
- cols→ Columnas por las que se necesita realizar la clasificación.
- ascendente → Valor booleano para decir que la clasificación se debe realizar en orden ascendente
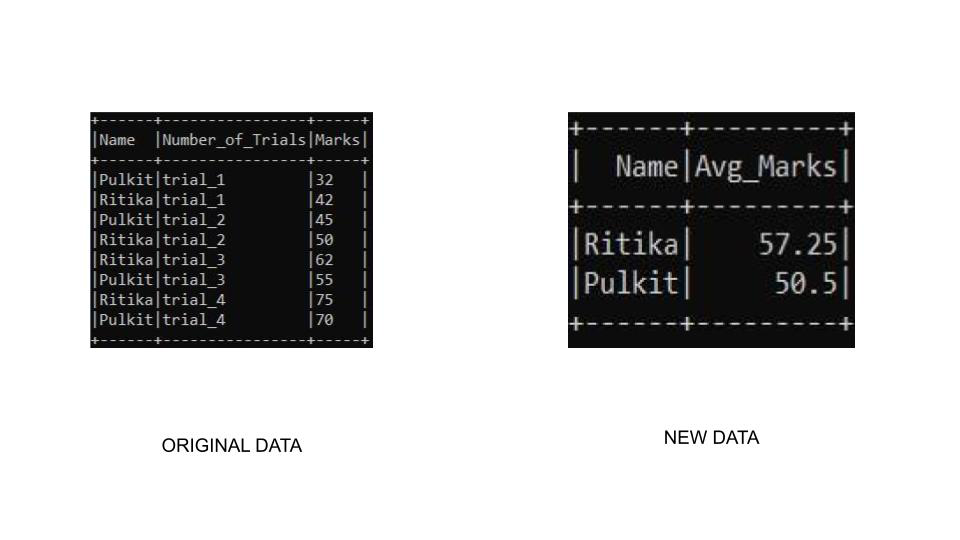
Ejemplo 1: en este ejemplo, vamos a agrupar el marco de datos por nombre y marcas agregadas. Ordenaremos la tabla usando la función sort() en la que accederemos a la columna usando la función col() y la función desc() para ordenarla en orden descendente.
Python3
# import the required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("GeeksForGeeks").getOrCreate()
# Define sample data
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema
schema = ["Name","Number_of_Trials","Marks"]
# create a dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
# group by name and aggrigate using
# average marks sort the column using
# col and desc() function
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(col("Avg_Marks").desc()) \
.show()
# stop spark session
spark.stop()
Producción:
Ejemplo 2: en este ejemplo, vamos a agrupar el marco de datos por nombre y marcas agregadas. Ordenaremos la tabla usando la función sort() en la que accederemos a la columna dentro de la función desc() para ordenarla en orden descendente.
Python3
# import the required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema to be used
schema = ["Name","Number_of_Trials","Marks"]
# create the dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
# perform groupby operation on name table
# aggrigate marks and give it a new name
# sort in descending order by avg_marks
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(desc("Avg_Marks")) \
.show()
# stop sparks session
spark.stop()
Producción:
Ejemplo 3: en este ejemplo, vamos a agrupar el marco de datos por nombre y marcas agregadas. Ordenaremos la tabla usando la función orderBy() en la que pasaremos el parámetro ascendente como Falso para ordenar los datos en orden descendente.
Python3
# import required modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
# Start spark session
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
# sample dataset
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
# define the schema
schema = ["Name","Number_of_Trials","Marks"]
# create a dataframe
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name")\
.agg(avg("Marks").alias("Avg_Marks"))\
.orderBy("Avg_Marks", ascending=False)\
.show()
# stop sparks session
spark.stop()
Producción:
Publicación traducida automáticamente
Artículo escrito por pulkit12dhingra y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA