En este artículo, vamos a escanear los subdominios utilizando el módulo de requests en Python, que nos permite realizar fácilmente requests HTTPS para obtener información de los sitios web. Para instalar el módulo de requests, escriba el siguiente comando en su símbolo del sistema.
pip install requests
La URL (Localizador uniforme de recursos) consta principalmente de cuatro partes:
- Protocolo
- subdominio
- Nombre de Dominio o Dominio de Segundo Nivel (SLD)
- Dominio de nivel superior (TLD)
La siguiente figura muestra las cuatro partes de la URL.
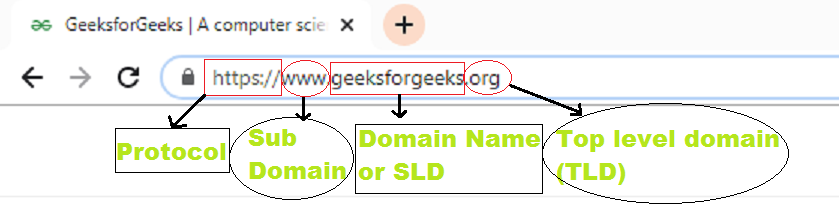
Los subdominios se definen como la parte del dominio que viene antes del nombre de dominio y la extensión del dominio, es decir, el dominio de nivel superior (TLD). Los subdominios se utilizan para organizar o dividir el contenido web en distintas secciones. Los subdominios nos ayudan a separar nuestro sitio web en secciones, los subdominios se ven como sitios web diferentes.
Archivo de subdominio utilizado:
mail mail2 www ns2 ns1 blog localhost m ftp mobile ns3 smtp search api dev secure webmail admin img news sms marketing test video www2 media static ads mail2 beta wap blogs download dns1 www3 origin shop forum chat www1 image new tv dns services music images pay ddrint conc
Acercarse:
- En primer lugar, tenemos una lista de nombres de subdominios en el archivo de texto para escanear esos subdominios ingresando la URL, puede obtener esta lista de subdominios de google.
- Ahora tenemos que crear la URL concatenando o usando f string con el protocolo, subdominio y nombre de dominio.
- Tenemos que usar for loop para poner subdominios en la URL uno por uno para escanear.
- Para evitar que el programa se bloquee cuando el subdominio no es válido con el nombre de dominio, tenemos que usar un bloque try-catch para omitir ese subdominio que no era válido y pasarlo con la ayuda del bloque catch y escanear el próximo subdominio con la ayuda de bloque de captura, el escaneo debe realizarse con la ayuda del módulo de solicitud, para la URL específica, la solicitud de obtención debe enviarse al servidor de acuerdo con la URL de respuesta del servidor que se imprimirá.
- Tan pronto como los subdominios se escanean y son válidos, se imprime la URL.
Pasos necesarios
- Módulo de solicitud de importación
- Cree una función para escanear los subdominios y pase el nombre de dominio y la lista de subdominios como parámetro.
- Ejecute un bucle para cada subdominio presente en la lista, y concatene el subdominio con el protocolo y el nombre de dominio en la secuencia de URL y guárdelo en la variable let denominada «URL».
- Ahora usamos la función request.get() y en ese paso, URL para recuperar la información del servidor dado usando la URL dada, si podemos recuperar información del servidor significa que el subdominio es válido con ese nombre de dominio, de lo contrario lo haremos páselo porque solíamos intentar y atrapar el bloque en el bloque de prueba, pasaremos la función request.get() y después de escanear, imprimiremos esa URL; de lo contrario, atraparemos el bloque de captura y pasaremos.
- Luego cree la función principal, en la entrada de usuario del nombre de dominio.
- Luego, abra la lista de archivos de texto de subdominios del almacenamiento en modo de lectura para escanear cada subdominio.
- Después de abrir el archivo en modo de lectura, estamos usando la función splitlines() para almacenar las strings divididas en la variable let denominada «sub_dom».
- Ahora llame a la función que habíamos creado para escanear el subdominio sin pasar por el nombre de dominio y sub_dom.
Mostrar los nombres de los subdominios presentes en el archivo de texto y crear una lista de esos subdominios.
Python
# opening the subdomain text file in the read mode
with open('subdomain_names.txt','r') as file:
# reading the file
name = file.read()
# using spilitlines() function storing the list
# of spitted strings
sub_dom = name.splitlines()
# printing number of subdomain names present in
# the list
print(f"Number of subdomain names present in the file are: {len(sub_dom)}\n")
# printing list of subdomain names present in the
# text file
print("List of subdomain names present in the file\n")
print(sub_dom)
Producción:

En el código anterior, estamos abriendo el archivo de texto del almacenamiento en el que están presentes nuestros nombres de subdominio que tenemos que escanear y también después de abrir el archivo del almacenamiento en modo de lectura, estamos haciendo la lista de contenido presente en ese archivo y imprimir el número de nombres de subdominio presentes en el archivo e imprimir la lista de nombres de subdominio.
El archivo de texto contiene solo 50 subdominios para demostración, puede tomar tantos subdominios como desee escanear según sus necesidades. Entonces, en la imagen de salida anterior, se imprime la lista de subdominios que escanearemos en el próximo ejemplo.
Usaremos este fragmento de código para escanear los subdominios.
Ejemplo 1: programa de exploración de subdominios usando Python.
Python
# importing module
import requests
# function for scanning subdomains
def domain_scanner(domain_name,sub_domnames):
print('----URL after scanning subdomains----')
# loop for getting URL's
for subdomain in sub_domnames:
# making url by putting subdomain one by one
url = f"https://{subdomain}.{domain_name}"
# using try catch block to avoid crash of the
# program
try:
# sending get request to the url
requests.get(url)
# if after putting subdomain one by one url
# is valid then printing the url
print(f'[+] {url}')
# if url is invalid then pass it
except requests.ConnectionError:
pass
# main function
if __name__ == '__main__':
# inputting the domain name
dom_name = input("Enter the Domain Name:")
# opening the subdomain text file
with open('subdomain_names1.txt','r') as file:
# reading the file
name = file.read()
# using spilitlines() function storing the list
# of splitted strings
sub_dom = name.splitlines()
# calling the function for scanning the subdomains
# and getting the url
domain_scanner(dom_name,sub_dom)
Producción:

El tiempo de escaneo dependerá de la cantidad de subdominios que esté escaneando, para la demostración tengo algunos nombres de subdominios en el archivo de texto, puede agregar tantos subdominios como desee escanear.
Ejemplo 2: Escáner de subdominios para Wikipedia usando Python.
Python
# importing library
import requests
# function for scanning subdomains
def domain_scanner(domain_name,sub_domnames):
print('-----------Scanner Started-----------')
print('----URL after scanning subdomains----')
# loop for getting URL's
for subdomain in sub_domnames:
# making url by putting subdomain one by one
url = f"https://{subdomain}.{domain_name}"
# using try catch block to avoid crash of
# the program
try:
# sending get request to the url
requests.get(url)
# if after putting subdomain one by one url
# is valid then printing the url
print(f'[+] {url}')
# if url is invalid then pass it
except requests.ConnectionError:
pass
print('\n')
print('----Scanning Finished----')
print('-----Scanner Stopped-----')
# main function
if __name__ == '__main__':
# inputting the domain name
dom_name = input("Enter the Domain Name:")
print('\n')
# opening the subdomain text file
with open('subdomain_names1.txt','r') as file:
# reading the file
name = file.read()
# using spilitlines() function storing the
# list of splitted strings
sub_dom = name.splitlines()
# calling the function for scanning the subdomains
# and getting the url
domain_scanner(dom_name,sub_dom)
Producción:

Publicación traducida automáticamente
Artículo escrito por srishivansh5404 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA