Scrapy es un marco rápido de rastreo web y raspado web de alto nivel que se utiliza para rastrear sitios web y extraer datos estructurados de sus páginas. Se puede utilizar para una amplia gama de propósitos, desde extracción de datos hasta monitoreo y pruebas automatizadas. En este tutorial, exploraremos cómo descargar archivos utilizando una araña de rastreo scrapy.
Para los principiantes, el rastreo web es el método de atravesar la World Wide Web para descargar información relacionada con un tema en particular. Una cosa a tener en cuenta es que no todos los sitios web le permitirán rastrear sus páginas, por lo que siempre es una buena práctica consultar su archivo robots.txt antes de intentar rastrear la página.
Paso 1: Instalación de paquetes:
Antes de comenzar a codificar, necesitamos instalar el paquete Scrapy
pip install scrapy
Paso 2: Creación de un proyecto
# scrapyProject is the name we chose for # the folder that will contain the project mkdir scrapyProject cd scrapyProject # downFiles is the name of the project scrapy startproject downFiles
El resultado después de ejecutar el código anterior en su terminal será el siguiente:

Salida al iniciar un nuevo proyecto scrapy
Paso 3: elegir una plantilla de araña
Scrapy viene con 4 plantillas de araña, a saber:
- básico: propósito general
- rastreo: para rastrear o seguir enlaces (preferido para descargar archivos)
- csvfeeed: para analizar archivos CSV
- xmlfeed: para analizar archivos XML
En este tutorial, usaremos la plantilla de araña de rastreo y la desarrollaremos más.
Para ver las plantillas de araña disponibles en scrapy:
scrapy genspider -l

Las 4 plantillas de araña disponibles en scrapy
Antes de comenzar a construir la estructura básica de la araña, asegúrese de estar trabajando dentro del directorio del proyecto (el directorio que contiene el archivo spider.cfg) que creó en el paso 2
Para cambiar su directorio :
# the project name we had decided was # downFiles in step2 cd downFiles
Para crear la estructura básica de la araña de rastreo:
scrapy genspider -t crawl nirsoft www.nirsoft.net # nirsoft es el nombre de la araña, www.nirsoft.com es el sitio web (dominio) que rastrearemos
Se creará un nuevo archivo python con el nombre de su araña con el siguiente contenido:
Este archivo se ubicará
…\scrapyProject\downFiles\downFiles\spiders\nirsoft.py
dónde
- scrapyProject es el nombre del directorio que contiene el proyecto
- downFiles es el nombre del proyecto
- nirsoft.py es la araña «vacía» recién creada
Código:
Python3
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class NirsoftSpider(CrawlSpider):
name = 'nirsoft'
allowed_domains = ['www.nirsoft.net']
start_urls = ['http://www.nirsoft.net/']
rules = (
Rule(LinkExtractor(allow=r'Items/'),
callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
return item
Este es un rastreador «vacío». Cuando se ejecuta no dará ningún resultado. Para extraer la información, debemos decirle a la araña qué enlaces necesita rastrear.
Nota: Esto es lo que diferencia a Scrapy de otros paquetes populares de rastreo web como Selenium que, si no se especifica, rastrea todos los datos (incluso si son innecesarios). Esta función hace que Scrapy sea más rápido que Selenium.
Paso 4: Definición de las reglas para la extracción de enlaces
Python3
rules = ( Rule(LinkExtractor(allow = r'Items/'), callback = 'parse_item', follow = True), )
El segmento de código anterior es lo que maneja qué enlaces rastreará la araña. Se pueden usar varios comandos para crear reglas, pero para este tutorial, usaremos solo un puñado común. Intentaremos descargar algunas herramientas ofrecidas por nirsoft.net. Todas las herramientas o más bien las utilidades están disponibles en sus utilidades, por lo que todos los enlaces relevantes siguen el patrón dado:
https://www.nirsoft.net/utils/...
Ejemplo:
https://www.nirsoft.net/utils/simple_program_debugger.html
https://www.nirsoft.net/utils/web_browser_password.html
https://www.nirsoft.net/utils/browsing_history_view.html
Entonces, el segmento de código anterior se editará de la siguiente manera:
Python3
rules = ( Rule(LinkExtractor(allow=r'utils/'), callback='parse_item', follow = True), )
Paso 4: analizar las páginas rastreadas
Ahora que hemos establecido qué enlaces se rastrearán, a continuación debemos definir qué debe rastrear exactamente la araña. Para ello, tendremos que inspeccionar las páginas en cuestión. Dirígete a cualquiera de los ejemplos anteriores y abre el modo de inspección de elementos (ctrl+shift+c para Windows, cmd+shift+c para MacOS)
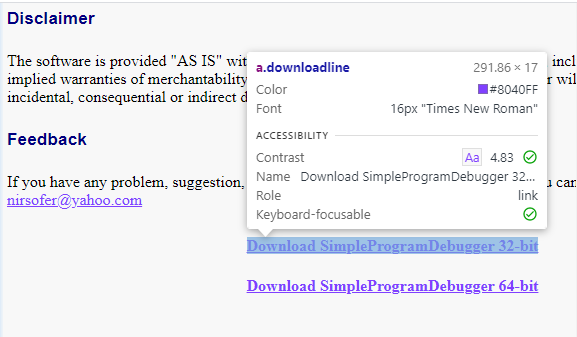
a.downloadline muestra que todos los enlaces de descarga son etiquetas ancla bajo el nombre de clase «downloadline»
- Como podemos ver, los enlaces de descarga son todos una etiqueta de anclaje (a) con un nombre de clase «downloadline» (a.downloadline)
- Así que ahora usaremos esto en un selector de CSS y extraeremos el atributo href de la etiqueta de anclaje
- Para que el rastreador funcione de manera eficiente, también necesitamos convertir los enlaces relativos en enlaces absolutos. Afortunadamente para nosotros, las últimas versiones de Scrapy nos permiten hacerlo con un método simple: urljoin()
Entonces, el método parse_item() se verá de la siguiente manera:
Python3
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
yield {'file_url': file_url}
Si ejecutamos el rastreador en este estado, obtendremos los enlaces a todas las utilidades disponibles en nirsoft.
scrapy crawl nirsoft
Para principiantes: recomendaría no ejecutar el comando anterior en este momento porque su símbolo del sistema se inundará con una tonelada de URL que se desplazan demasiado rápido para que sus ojos perciban algo.

En cuestión de segundos, nuestra línea de comando se inundará con todas las URL extraídas
En su lugar, pasemos al siguiente paso.
Paso 5: Descarga de archivos
Por fin llegó el momento que todos estábamos esperando, la descarga de los archivos. Sin embargo, antes de llegar a eso, debemos editar la clase de elemento que se creó cuando creamos la araña inicialmente. El archivo se puede encontrar en la siguiente ubicación:
...\scrapyProject\downFiles\downFiles\items.py
dónde
- scrapyProject es el nombre del directorio que contiene el proyecto
- downFiles es el nombre del proyecto
- items.py es la clase del elemento en cuestión
La clase de elementos debe editarse de la siguiente manera:
Python3
class DownfilesItem(scrapy.Item): # define the fields for your item here like: file_urls = scrapy.Field() files = scrapy.Field
Ahora actualizamos el script de araña para hacer uso de los campos de datos que hemos definido
Python3
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
item = DownfilesItem()
item['file_urls'] = [file_url]
yield item
También tendrá que importar la clase de elemento que definió anteriormente en su secuencia de comandos de araña, por lo que la sección de importación de la secuencia de comandos de araña se verá así:
Python3
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from downFiles.items import DownfilesItem
Finalmente, para habilitar la descarga de archivos, debemos realizar dos pequeños cambios en el archivo settings.py en nuestro directorio de proyectos:
1. Habilite las descargas de archivos:
ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline': 1,
}
2. Especifique la carpeta de destino para las descargas en settings.py:
FILES_STORE = r"D:\scrapyProject\nirsoft\downloads"
Nota: el destino de la carpeta debe ser un destino real
Usamos una string sin procesar para evitar errores debido a la barra invertida en la string de ubicación de Windows
Ahora si corremos
scrapy crawl nirsoft
Podremos encontrar todos los archivos descargados en la carpeta de destino especificada y, por lo tanto, ¡habremos terminado!
Limitación de los tipos de archivos a descargar
Dado que nuestro objetivo era descargar los archivos de instalación de las utilidades, sería mejor limitar el rastreador a descargar solo los archivos .zip y .exe y dejar el resto fuera. Esto también reducirá el tiempo de rastreo, lo que hará que el script sea más eficiente.
Para esto necesitamos editar nuestras funciones parse_items() como se muestra a continuación:
Python3
def parse_item(self, response):
file_url = response.css('.downloadline::attr(href)').get()
file_url = response.urljoin(file_url)
file_extension = file_url.split('.')[-1]
if file_extension not in ('zip', 'exe', 'msi'):
return
item = DownfilesItem()
item['file_urls'] = [file_url]
item['original_file_name'] = file_url.split('/')[-1]
yield item
También necesitamos agregar el nuevo campo de datos «original_file_name» a nuestra definición de clase de elementos:
Python3
class DownfilesItem(scrapy.Item): # define the fields for your item here like: file_urls = scrapy.Field() original_file_name = scrapy.Field() files = scrapy.Field
Guarde todos sus cambios y ejecute,
scrapy crawl nirsoft
Podremos encontrar todos los archivos .zip y .exe descargados en la carpeta de destino especificada. Sin embargo, todavía tenemos un problema:

Los códigos hash SHA1 no son legibles por humanos, por lo que sería preferible que los archivos se guardaran con sus nombres originales (legibles por humanos), lo que nos lleva a la siguiente sección
Creación de canalizaciones personalizadas
Inicialmente, usamos la canalización predeterminada de Scrapy para descargar los archivos, sin embargo, el problema era que los archivos se guardaban con sus códigos hash SHA1 en lugar de sus nombres de archivo legibles por humanos. Por lo tanto, debemos crear una canalización personalizada que guarde el nombre de archivo original y luego use ese nombre al descargar los archivos.
Al igual que nuestra clase de artículos (items.py), también tenemos una clase de tubería (pipelines.py) con una clase para nuestro proyecto generada cuando creamos el proyecto, usaremos esta clase para crear nuestra tubería personalizada
Python3
from scrapy.pipelines.files import FilesPipeline
class DownfilesPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
file_name: str = request.url.split("/")[-1]
return file_name
Importamos el FilesPipeline predeterminado proporcionado por Scrapy y luego sobrescribimos la función file_path para que, en lugar de usar el código hash como nombre de archivo, usara el nombre de archivo.
Comentamos la función process_item para que no sobrescriba la función process_item predeterminada de FilesPipeline.
A continuación, actualizamos nuestro archivo settings.py para usar nuestra canalización personalizada en lugar de la predeterminada.
ITEM_PIPELINES = {
'downFiles.pipelines.DownfilesPipeline': 1,
}
Finalmente, corremos
scrapy crawl nirsoft
Y tenemos nuestro resultado:
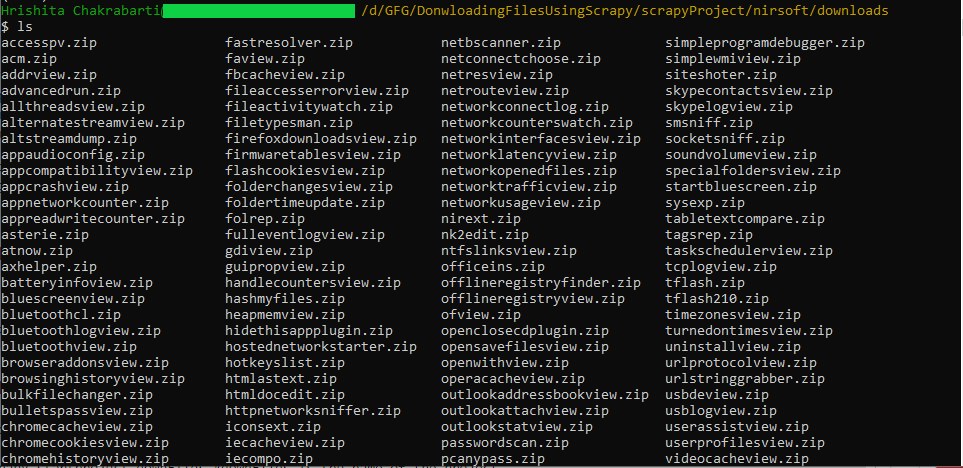
Gracias al Pipeline personalizado, los archivos descargados son mucho más legibles
Publicación traducida automáticamente
Artículo escrito por hrishitachakrabarti y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA