En este artículo, volveremos de un índice múltiple a un índice único en el marco de datos de pandas. A veces, cuando estamos haciendo análisis de datos exploratorios o manipulación de datos, tenemos que hacer la indexación múltiple en el marco de datos, para extraer información significativa o usar las columnas de manera eficiente y fácil. Después de realizar la manipulación de datos, si queremos cambiar nuestro marco de datos de índice múltiple a índice único, para que se vea mejor, se recomienda cambiar el marco de datos a un índice único.
El índice es como una dirección, así es como se puede acceder a cualquier punto de datos en el marco de datos o serie. Tanto las filas como las columnas tienen índices, los índices de las filas se denominan índice y para las columnas.
En este artículo, vamos a utilizar el archivo homelessness.csv para el marco de datos y le aplicaremos métodos.
Python3
# importing pandas library as alias pd.
import pandas as pd
# using pandas read_csv().
df = pd.read_csv('homelessness.csv')
df.head()
Producción:

Como podemos ver, este marco de datos no tiene índice. Entonces, creamos un índice con indexación múltiple usando pandas set_index() , pasando el nombre de las columnas como la lista.
Python3
# making the 'region' and 'state' column as index. df_mi = df.set_index(['region' , 'state' , 'individuals']) print(df_mi.head())
Producción:
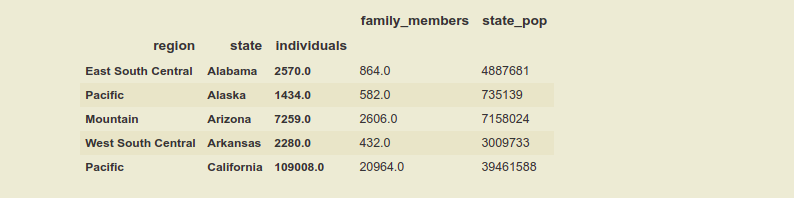
Ahora, el marco de datos tiene indexación jerárquica o indexación múltiple. Para revertir el índice del marco de datos de índice múltiple a un índice único usando la función incorporada de Pandas reset_index() .
Sintaxis: DataFrame.reset_index(level=Ninguno, drop=False, inplace=False, col_level=0, col_fill=”)
Devuelve : (Marco de datos o Ninguno) Marco de datos con el nuevo índice o Ninguno si inplace=True .
Revertir el índice múltiple usando la forma anterior, es decir; usando reset_index() podemos seguir como:
- Utilizando el nivel del índice.
- Usando el nombre del index.
Usando el nivel del índice
Pasar los valores a la función usando la palabra clave level , que acepta la lista de los niveles, que queremos revertir desde la posición del índice. Como sabemos los multiíndices forman una jerarquía de índices, por eso estos también son conocidos como índices jerárquicos. En este marco de datos, ‘región’ es el índice de nivel (0) o el índice principal y el ‘estado’ es el índice de nivel (1) y ‘individuos’ es el índice de nivel (2) . Convertir el marco de datos en un solo índice , manteniendo el índice de ‘estado’ y revirtiendo el índice de ‘región’ e ‘individuos’.
Python3
# using the reset_index(), reverting the # level 0 and level 2 indexes. df_si_level = df_mi.reset_index( level = [0 , 2] ) print(df_si_level.head())
Producción:
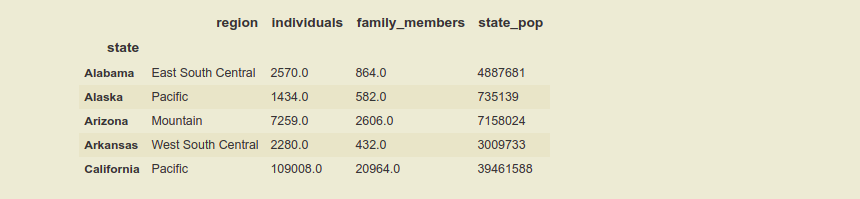
Usando el nombre del índice
En este método simplemente pasando el nombre de los índices en una lista a reset_index(). Convertir el marco de datos en un solo índice, manteniendo el índice de ‘ individuos ‘ y revirtiendo el índice de ‘ región ‘ y ‘ estado ‘, simplemente omitiendo sus nombres en la lista.
Python3
# using the reset_index(), reverting # the 'region' and 'state' indexes. df_si_name = df_mi.reset_index([ 'region' , 'state' ]) print(df_si_name.head())
Salida :
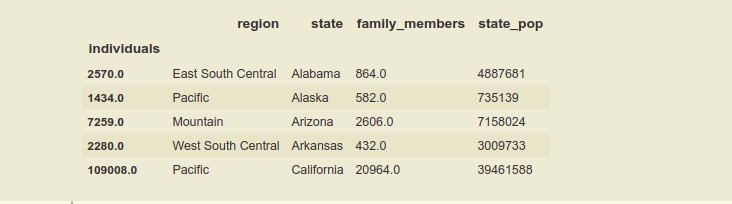
Nota : si deseamos que el marco de datos no tenga índices, o no queremos que ninguna columna sea un índice, en ese caso, podemos pasar el nombre de todos los índices o niveles en reset_index() , para hacer que el índice Dataframe sea gratuito.
Publicación traducida automáticamente
Artículo escrito por pawanagrawalp847 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA