Naive Bayes es un algoritmo de clasificación no lineal supervisado en programación R. Los clasificadores Naive Bayes son una familia de clasificadores probabilísticos simples basados en la aplicación del teorema de Baye con fuertes suposiciones de independencia (Naive) entre las características o variables. El algoritmo Naive Bayes se llama «Naive» porque supone que la aparición de una determinada característica es independiente de la aparición de otras características.
Teoría
El algoritmo Naive Bayes se basa en el teorema de Bayes. El teorema de Bayes da la probabilidad condicional de un evento A dado que ha ocurrido otro evento B.
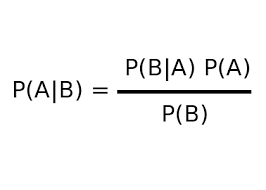
donde,
P(A|B) = Probabilidad condicional de A dado B.
P(B|A) = Probabilidad condicional de B dado A.
P(A) = Probabilidad del evento A.
P(B) = Probabilidad del evento B.
Para muchos predictores, podemos formular la probabilidad posterior de la siguiente manera:
P(A|B) = P(B1|A) * P(B2|A) * P(B3|A) * P(B4|A) …
Ejemplo
Consider a sample space:
{HH, HT, TH, TT}
where,
H: Head
T: Tail
P(Second coin being head given = P(A|B)
first coin is tail) = P(A|B)
= [P(B|A) * P(A)] / P(B)
= [P(First coin is tail given second coin is head) *
P(Second coin being Head)] / P(first coin being tail)
= [(1/2) * (1/2)] / (1/2)
= (1/2)
= 0.5
El conjunto de datos
El conjunto de datos de Iris consta de 50 muestras de cada una de las 3 especies de Iris (Iris setosa, Iris virginica, Iris versicolor) y un conjunto de datos multivariado introducido por el estadístico y biólogo británico Ronald Fisher en su artículo de 1936 El uso de múltiples medidas en problemas taxonómicos. Se midieron cuatro características de cada muestra, es decir, la longitud y el ancho de los sépalos y pétalos y, basándose en la combinación de estas cuatro características, Fisher desarrolló un modelo discriminante lineal para distinguir las especies entre sí.
Python3
# Loading data data(iris) # Structure str(iris)

Realización de Naive Bayes en un conjunto de datos
Usando el algoritmo Naive Bayes en el conjunto de datos que incluye 11 personas y 6 variables o atributos
Python3
# Installing Packages
install.packages("e1071")
install.packages("caTools")
install.packages("caret")
# Loading package
library(e1071)
library(caTools)
library(caret)
# Splitting data into train
# and test data
split <- sample.split(iris, SplitRatio = 0.7)
train_cl <- subset(iris, split == "TRUE")
test_cl <- subset(iris, split == "FALSE")
# Feature Scaling
train_scale <- scale(train_cl[, 1:4])
test_scale <- scale(test_cl[, 1:4])
# Fitting Naive Bayes Model
# to training dataset
set.seed(120) # Setting Seed
classifier_cl <- naiveBayes(Species ~ ., data = train_cl)
classifier_cl
# Predicting on test data'
y_pred <- predict(classifier_cl, newdata = test_cl)
# Confusion Matrix
cm <- table(test_cl$Species, y_pred)
cm
# Model Evaluation
confusionMatrix(cm)
Producción:
- Modelo clasificador_cl:
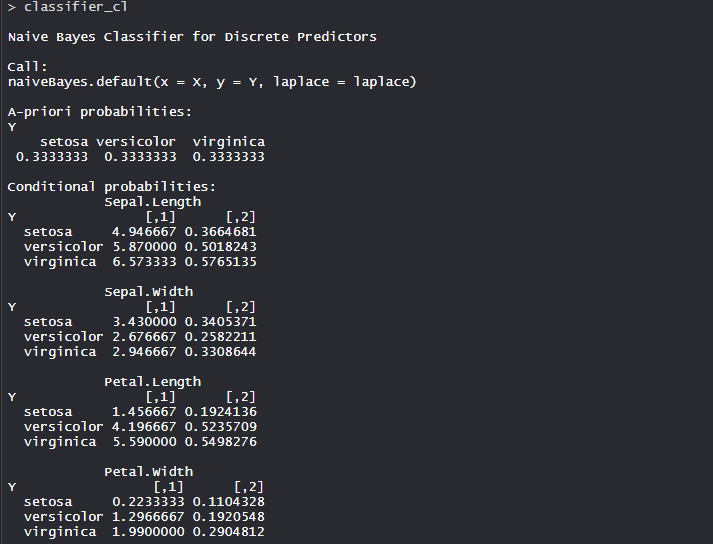
- La probabilidad condicional para cada característica o variable es creada por modelo por separado. También se calculan las probabilidades a priori que indican la distribución de nuestros datos.
- Array de confusión:
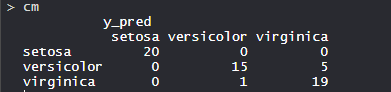
- Entonces, 20 Setosa se clasifican correctamente como Setosa. De 16 Versicolor, 15 Versicolor se clasifican correctamente como Versicolor y 1 se clasifica como virginica. De 24 vírgenes, 19 vírgenes se clasifican correctamente como vírgenes y 5 se clasifican como Versicolor.
- Evaluación del modelo:
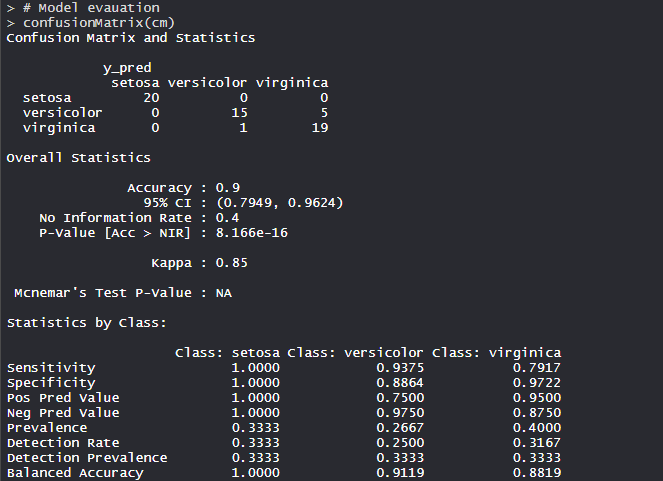
- El modelo logró una precisión del 90 % con un valor p inferior a 1. Con sensibilidad, especificidad y precisión equilibrada, la construcción del modelo es buena.
Por lo tanto, Naive Bayes se usa ampliamente en el análisis de sentimiento, categorización de documentos, filtrado de correo no deseado, etc. en la industria.